智能运维 | 百度多维度数据分析实战
Posted 百度智能云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能运维 | 百度多维度数据分析实战相关的知识,希望对你有一定的参考价值。
在采集监控数据时,人们常常会在数据上附加若干标签,从多个不同的角度对数据加以描述。我们把这种附加了不同角度标签的数据称为多维度数据。多维度数据除了可以展示更多的数据信息,在故障诊断中也能起到很大的作用。
本文将重点介绍百度云智能运维团队在多维度数据分析方面的实战经验:
多维度数据概念介绍
基于多维度数据的故障诊断分析
基于多维度数据的智能故障定位算法
假设有一个手机网站。
网站的前端开发工程师希望了解用户使用的浏览器情况,则会在采集PV(页面浏览)数据时增加UA(User Agent)标签,这样就可以有针对性地优化前端代码。另一方面,产品经理希望了解用户在不同网络条件下的行为特征,从而优化网站的内容展示。因此他们在PV数据上增加了“网络”标签。
在附加了这两个标签后,某时刻的PV数据就可以展开为表1所示的样子。表1假设UA标签有3个取值,分别是:
“百度浏览器”
“UC浏览器”
“OPPO浏览器”。
网络标签也有3个取值:
“3G”
“4G”
“Wifi”。
根据这两个标签的取值,PV数据就展开成了一个二维表的形态。表中的每一列对应的是UA标签的取值,每一行对应的是网络标签的取值。这就是我们把带标签的数据叫做多维度数据的原因。
这时每个维度对应一个标签,每个维度的值对应了标签的取值。
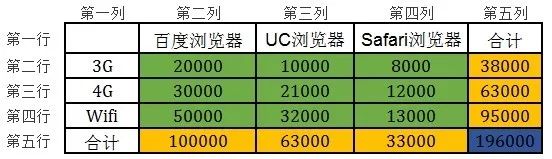
表1 PV数据二维表格(注:表中数据为假设数据)
表1中共有16个单元格有PV数据。
绿色单元格部分为两个维度的不同取值的交叉维度对应的PV。例如,第二行、二列的单元格表示来自“UA =百度浏览器”&“网络制式=3G”的PV为20000;
黄色单元格部分为某一个维度取值的PV总和;第二行、五列的单元格表示某段时间内,来自“网络制式=3G”的PV为38000,该值为“UA=*”&“网络制式=3G”所有维度的PV之和;
蓝色单元格部分表示所有维度的PV总和,即某段时间内的总PV为196000。
可以想象,如果在上述PV数据中再增加一个标签,比如销售人员希望增加“省份”标签来作为销售方案优化的依据,数据就会被展开成一个立方体。有n个标签时,数据就变成n维空间中的一个超立方体。
发生故障时,通常会体现在多维度数据中。我们在表1的基础上加上各维度的PVLost(即流量损失,处理失败的请求个数),如表2所示。
表2中每个单元格由两个数字组成,分别表示来自该维度的PV、PVLost。例如,第二行、二列的单元格{20000, 95}表示来自“UA=百度浏览器”&“网络制式=3G”的总请求PV流量为20000,其中95个PV因某种原因处理失败。
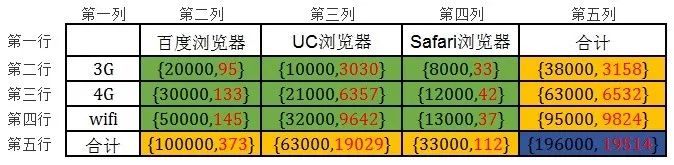
表2 PV&PVLost数据二维表格(注:表中数据为假设数据)
如果直接对表2进行人为的直观分析,很容易得到结论“此次故障的根因维度为‘UA = UC浏览器’”。
原因如下:
“UA = UC浏览器”的损失流量较多。服务总PVLost为19514,其中“UA = UC浏览器”的PVLost为19029,占总损失流量的97.51%;
“UA = UC浏览器”在各网络制式的流量损失率(PVLost/PV)较接近,分别为30.30%(3030/10000)、30.27%(6357/21000)、30.13%(9642/32000);且与“UA = UC浏览器”维度的的损失率30.20%(19029/63000)相似。
当维度只有两个、且维度的取值不多时,人工很容易定位到根因维度。但在实际工作中,并非如此。随着维度、维度取值增多,人工通过上述的方法进行定位的难度急剧增加。因此,需要通过机器学习的方式自动定位到根因维度。
参考人工定位过程中的分析思路,我们提取了两个可以描述某维度是否为根因的特征:
贡献度,即该维度PVLost与总PVLost的比例。
一致度,即构成该维度的子维度的异常程度的相似度。子维度的异常程度的一致度可通过各子维度异常程度间的变异系数衡量,变异系数越小,则异常程度越一致。
根据两个特征的描述可知,贡献程度越高、且子维度的异常相似度越高,则该维度为根因维度的可能性越大。
因此,可以将数据的各维度展开,分别计算各维度的贡献度、一致度两个特征,根据维度的特征识别根因的问题即可转化为分类问题。其中,分类器参数可根据历史故障时各维度的标注数据,利用机器学习算法训练得到。
图1为我们收集的历史故障时不同维度的散点图,图中每一个点为一个维度(其中,蓝色点为非根因维度,红色点为根因维度);横、纵轴分别代表贡献度、一致度两个特征;根因维度主要集中在图中的右下角(其贡献度较高、变异系数较小),绿色直线为对该组标注数据训练得到的分类线。
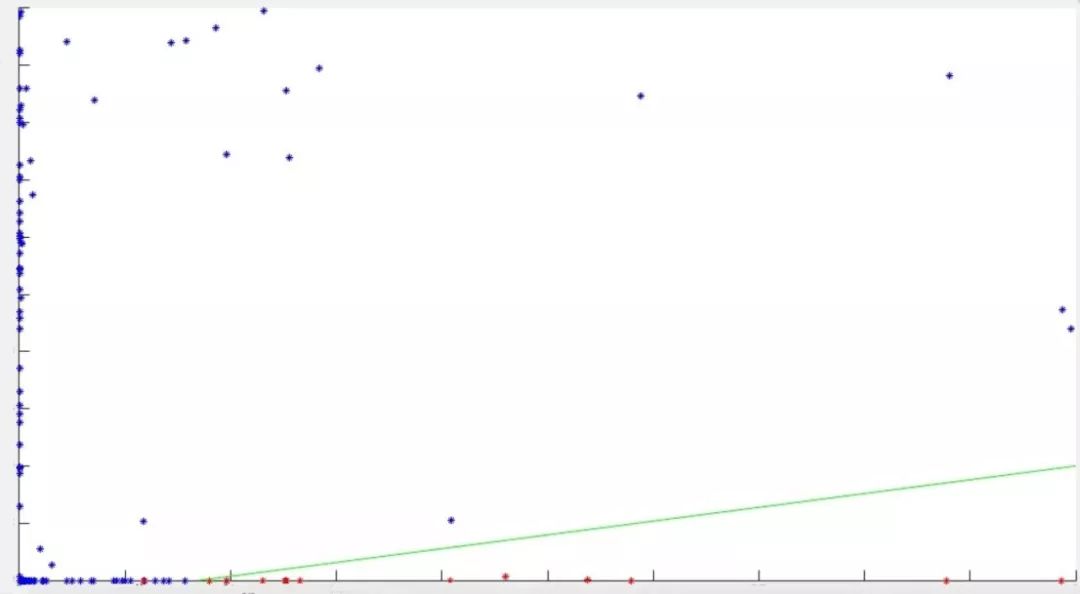
图1 根因维度识别散点图
当维度的个数及其取值过多时,将维度进行展开计算上述两个特征时会带来较大的时间、空间开销。
本文主要介绍了多维度数据,以及通过多维度数据分析进行故障诊断的一种方法。
首先介绍了多维度数据的特点,以及多维度数据的组织方式。结合一个PVLost增多的例子,分析了人工在利用多维度数据进行故障诊断的过程。参考人工定位过程,提出了基于多维度数据的故障诊断方法,该方法可适用到任意可加和的多维度数据定位的场景。
若您有任何疑问或想进一步了解多维度数据分析相关问题,欢迎给我们评论、留言!
作者简介
运之云 百度云高级研发工程师
从事百度云智能运维产品(Noah)大数据分析相关工作,重点关注时序数据分析、故障诊断及相关领域技术。
更多相关文章
|
| |
| |
|
| |
| |
| | |
| |
|
以上是关于智能运维 | 百度多维度数据分析实战的主要内容,如果未能解决你的问题,请参考以下文章