数据分析从零开始实战 | 基础篇
Posted 简说Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析从零开始实战 | 基础篇相关的知识,希望对你有一定的参考价值。
一、写在前面
之前的一个系列 『Python小知识 』主要和大家分享一下我快速看过一遍《零压力学Python》后觉得比较好玩、重要的一些知识点。
接下来我打算花一个月左右的时间把《数据分析实战》看完,实操一遍,同样开成一个系列『数据分析从零开始实战』,既然说了从零开始,就肯定是从零开始,当然如果真的一点基础都没有,建议大家把 『Python小知识 』专栏先看一遍。
Python小技能入门四篇
二、知识点概要
1.创建一个虚拟python运行环境,专门用于本系列学习;
2.数据分析常用模块pandas安装
3.利用pandas模块读写CSV格式文件
三、开始动手动脑
1.创建虚拟环境
我平时比较喜欢Pycharm,所以本系列打算完全用Pycharm做,Pycharm安装可以直接到官网上下载,使用社区版即可。
(1)好的正式开始,打开Pycharm,点击File->New Project,基本配置说明见下图。
特别说明:python里面项目路径里不要出现中文,同时项目名称也不要出现中文,名称尽量能够概括项目内容。

操作步骤图
(2)创建成功后,我们会在对应目录下面发现多了项目文件和虚拟环境文件。
2.数据分析常用模块Pandas安装
(1)零基础教程,首先教大家怎么进入虚拟环境:进入到目录I:\pyCoding\Frame\Data_analysis\Scripts(我的虚拟环境目录),按住shift+鼠标右键,打开powershell或者cmd(如果是powershell就先输入cmd),再输入activate,进入虚拟环境,你会发现在路径前面多了一个括号里面是你的虚拟环境名称,表示你进入了虚拟环境。具体看下面:
PS I:\pyCoding\Frame\Data_analysis\Scripts> cmd
Microsoft Windows [版本 10.0.17134.112]
(c) 2018 Microsoft Corporation。保留所有权利。
I:\pyCoding\Frame\Data_analysis\Scripts>activate
(Data_analysis) I:\pyCoding\Frame\Data_analysis\Scripts>
不知道大家有没有觉得很麻烦,我是觉得特别麻烦,每次进入虚拟环境都要先到指定文件路径,然后再输入指令,不符合程序员的风格啊!当然有简单方法,具体操作看我之前写的一篇文章里有详细介绍,,怎么快速进入虚拟环境。
(2)安装pandas模块
使用快捷方式进入虚拟环境后,直接pip指令安装
# cmd下直接操作
C:\Users\82055>workon
Pass a name to activate one of the following virtualenvs:
==============================================================================
Data_analysis
spiderenv
C:\Users\82055>workon Data_analysis
(Data_analysis) C:\Users\82055>pip install pandas
安装结果:

安装过程
安装过程大概1分钟左右,完成后会显示
Installing collected packages: pytz, numpy, six, python-dateutil, pandas
Successfully installed numpy-1.15.4 pandas-0.23.4 python-dateutil-2.7.5 pytz-2018.7 six-1.11.0
很明显看出,这个过程不仅安装了pandas包,还安装了numpy,pytz,six,python-dateutil这些附加包,后面我们也会用上。
3.利用pandas模块读写CSV格式文件
(1)数据文件下载
本系列按书上来的数据都是这里面的,《数据分析实战》书中源代码也在这个代码仓库中,当然后面我自己也会建一个代码仓库,记录自己的学习过程,大家可以先从这里下载好数据文件。
(2)pandas基本介绍
pandas为Python编程语言提供高性能,是基于NumPy 的一种易于使用的数据结构和数据分析工具,pandas为我们提供了高性能的高级数据结构(比如:DataFrame)和高效地操作大型数据集所需的工具,同时提供了大量能使我们快速便捷地处理数据的函数和方法。
(3)利用pandas读取CSV文件
读取代码:
# 导入数据处理模块
import pandas as pd
import os
# 获取当前文件父目录路径
father_path = os.getcwd()
# 原始数据文件路径
rpath_csv = father_path+r'\data01\city_station.csv'
# 读取数据
csv_read = pd.read_csv(rpath_csv)
# 显示数据前10条
print(csv_read.head(10))
运行结果:
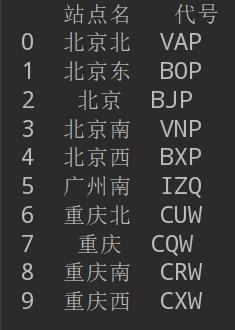
函数解析:
read_csv(filepath_or_buffer,sep,header,names,skiprows,na_values,encoding,nrows)
按指定格式读取csv文件。
常见参数解析:
1. filepath_or_buffer:字符串,表示文件路径;
2. sep: 字符串,指定分割符,默认是’,’;
3. header:数值, 指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0; 如果指定了列名header=None;
4. names: 列表,指定列名,如果文件中不包含header的行,应该显性表示header=None。
5. skiprows:列表,需要忽略的行数(从0开始),设置的行数将不会进行读取。
6. na_values:列表,设置需要将值替换成NAN的值,pandas默认NAN为缺省,可以用来处理一些缺省、错误的数值。
7. encoding:字符串,用于unicode的文本编码格式。例如,"utf-8"或"gbk"等文本的编码格式。
8. nrows:需要读取的行数。
(4)利用pandas写入CSV文件
写入代码:
import pandas as pd
import os
# 获取当前文件父目录路径
father_path = os.getcwd()
# 保存数据文件路径
path_csv = father_path+r'\data01\temp_city.csv'
# 写入数据(列名+列值)
data = {"站点名": ["北京北", "北京东", "北京", "北京南", "北京西"],
"代号": ["VAP", "BOP", "BJP", "VNP", "BXP"]}
# 数据初始化为DataFrame对象
df = pd.DataFrame(data)
# 数据写入
df.to_csv(path_csv)
运行结果:
函数解析:
to_csv(path_or_buf,sep,na_rep,columns,header,index)
1. path_or_buf:字符串,文件名、文件具体、相对路径、文件流等;
2. sep:字符串,文件分割符号;
3. na_rep:字符串,将NaN转换为特定值;
4. columns:列表,选择部分列写入;
5. header:None,写入时忽略列名;
6. index:False则选择不写入索引,默认为True。
如果你有CSDN账号的话,点击阅读原文,关注我。
和老表,一起学Python。
~随手点一下,好看~
以上是关于数据分析从零开始实战 | 基础篇的主要内容,如果未能解决你的问题,请参考以下文章