R语言DataExplorer包:促进探索性数据分析(EDA)
Posted R语言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言DataExplorer包:促进探索性数据分析(EDA)相关的知识,希望对你有一定的参考价值。
这是我的第57篇原创文章,关于探索性数据分析(EDA)。
阅读完本文,你可以知道:
1 EDA是什么
2 DataExplore包如何促进EDA
探索性数据分析(EDA)是我们做数据分析的第一步,也是最重要的一步。通过EDA,可以让我们了解数据状况,发现数据问题,为我们后续的数据管理提供指导。
EDA是从原始数据入手,采用数据汇总和数据可视化的方法,研究数据的概况,变量的类型,变量的分布,变量与变量之间的关系,数据的常见问题(缺失值|无效值|异常值|数据范围|数据单位等)等内容,其目的就是最大程度地理解数据,最大程度地保证数据质量。
DataExplore包是R语言的一个EDA包,使用它,可以帮助我们更有效和快捷地对数据做EDA。
DataExplore包的主要使用,记录如下。
一 安装和导入DataExplore包
if(!require(DataExplorer)){
install.packages("DataExplorer")
require(DataExplorer)
}二 加载tidyverse包和funModeling包
library(tidyverse)
library(funModeling)
三 加载数据
# 加载数据
choco <- read_csv('./data/flavors_of_cacao.csv')
四 数据概况
# 数据概况
glimpse(choco)
df_status(choco)
choco %>% summary
结果
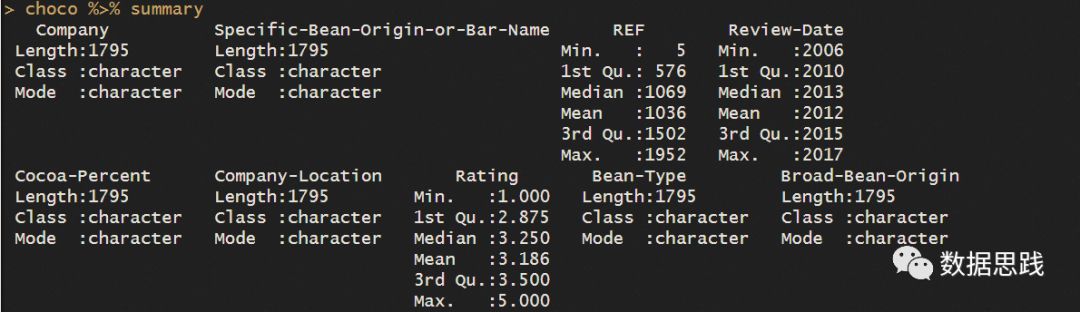
结论:
数据集有1795个观察,9个变量。
9个变量有6个是字符类型,3个是数值类型
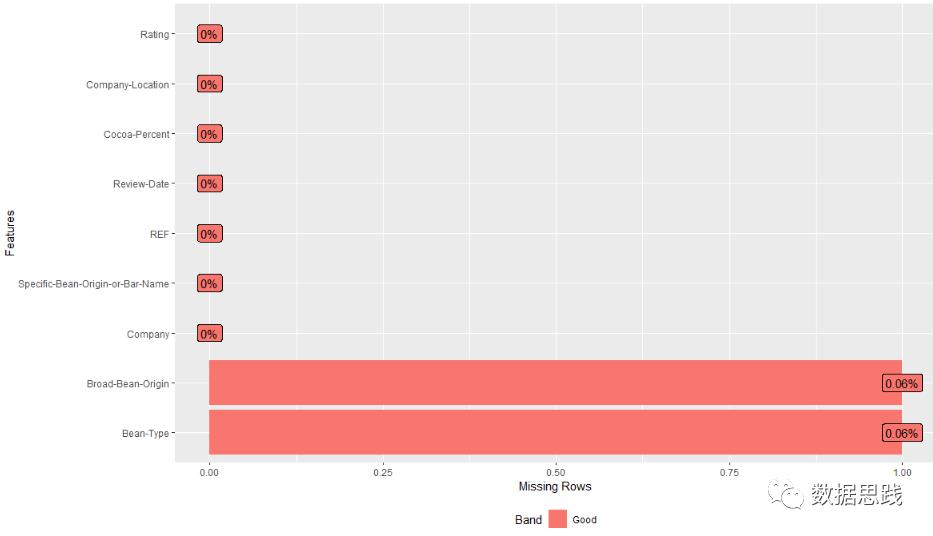
9个变量都没有取0值,变量Bean-Type和Broad-Bean-Origin都有1个缺失,缺失值百分比是0.06%
summary()函数给连续变量提供了最小值,中位数,均值、一分位数、三分位数和中位数这些信息
五 数据清洗
根据原始数据集和数据概况结果,结合业务知识,对数据做清洗。
code
# 数据清洗
choco$`Cocoa-Percent` <- as.numeric(gsub('%', '', choco$`Cocoa-Percent`))
choco$`Review-Date`<- as.character(choco$`Review-Date`)
六 缺失值可视化分析
# 缺失值分析
plot_missing(choco)
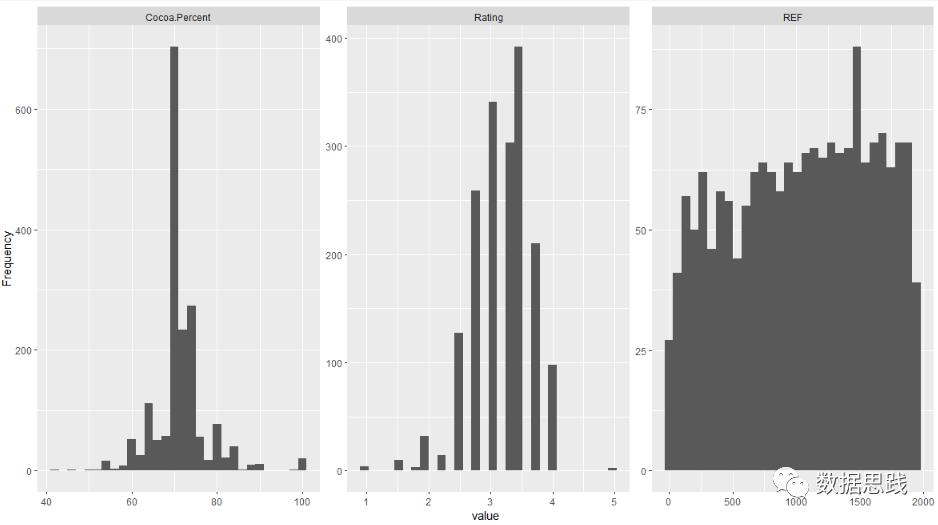
七 连续变量分布
# 连续型变量分布
# 直方图分析
plot_histogram(choco)
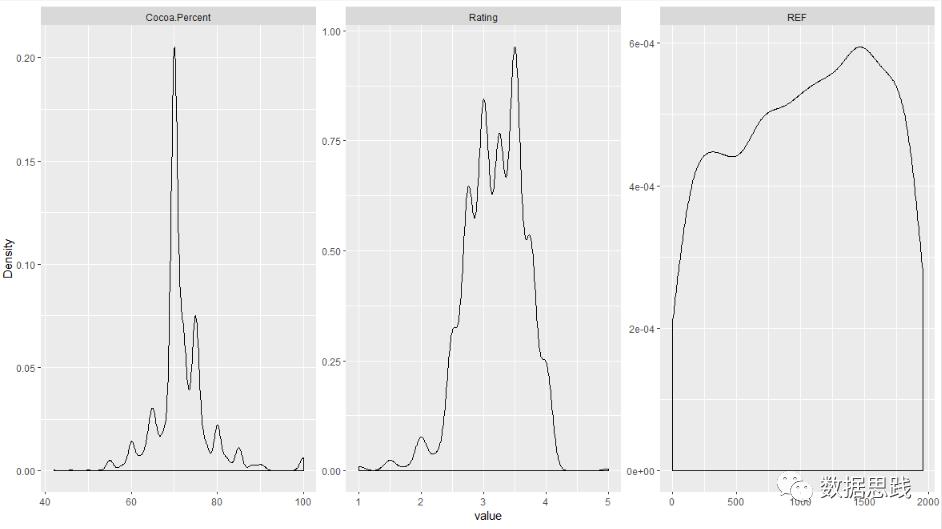
# 核密度曲线分析
plot_density(choco)
结果
八 类别变量分布
code
# 类别变量
# 柱状图
plot_bar(choco)
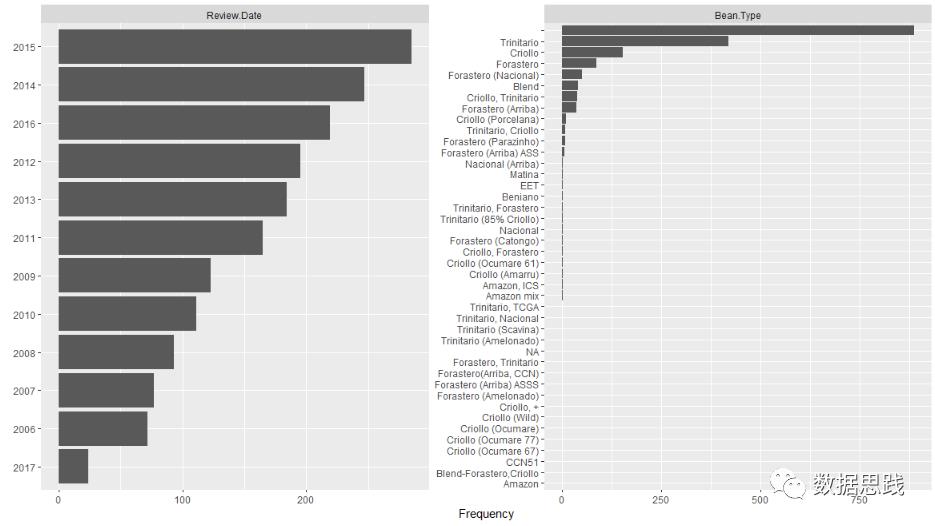
九 变量之间的关系图
# 多变量分析
plot_correlation(choco,
type = "continuous")
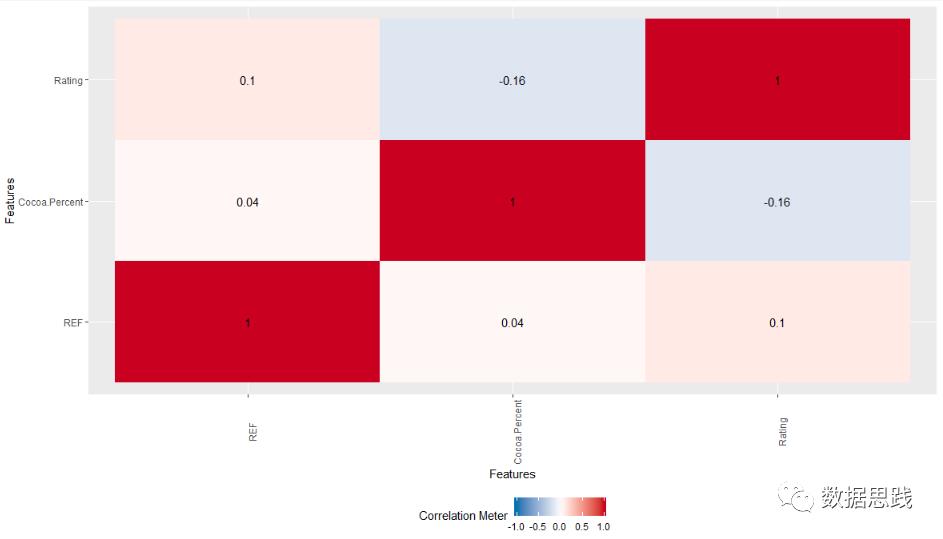
十 生成一份EDA报告
# 生成一份EDA的报告
create_report(choco)
创建一份html格式的探索性数据分析报告,让你全面地认识数据。
温馨提示:
只有充分地理解数据,才能更好地应用数据。
EDA从原始数据入手,对数据做画像工作,以保证数据可用和有价值。
参考资料:
1https://towardsdatascience.com/simple-fast-exploratory-data-analysis-in-r-with-dataexplorer-package-e055348d9619
2https://boxuancui.github.io/DataExplorer/
附录:参考完整代码
if(!require(DataExplorer)){
install.packages("DataExplorer")
require(DataExplorer)
}
library(tidyverse)
library(funModeling)
# 加载数据
choco <- read_csv('./data/flavors_of_cacao.csv')
# 数据概况
glimpse(choco)
df_status(choco)
choco %>% summary
# 数据清洗
choco$`Cocoa-Percent` <- as.numeric(gsub('%', '', choco$`Cocoa-Percent`))
choco$`Review-Date`<- as.character(choco$`Review-Date`)
df_status(choco)
# 变量理解
plot_str(choco)
# 缺失值分析
plot_missing(choco)
# 连续型变量分布
# 直方图分析
plot_histogram(choco)
# 核密度曲线分析
plot_density(choco)
# 类别变量
# 柱状图
plot_bar(choco)
# 多变量分析
plot_correlation(choco,
type = "continuous")
# 生成一份EDA的报告
create_report(choco)
关于探索性数据分析EDA,您有什么想法请留言。
需要深入交流和沟通,请加我的微信:luqin360。备注:实名+工作或者专业,否则不会通过。
数据思考与践行
PDFMV框架系列文章
以上是关于R语言DataExplorer包:促进探索性数据分析(EDA)的主要内容,如果未能解决你的问题,请参考以下文章