京东金融数据分析:MySQL+HIVE的结合应用案例详解附全代码
Posted 爱数据原统计网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东金融数据分析:MySQL+HIVE的结合应用案例详解附全代码相关的知识,希望对你有一定的参考价值。
文末领取【案例数据集+全部代码】
给定的数据为业务情景数据,所有数据均已进⾏了采样和脱敏处理,字段取值与分布均与真实业务数据不同。提供了时间为 2016-08-03 到 2016-11-30 期间,用户在移动端的行为数据、购物记录和历史借贷信息,及 11 月的总借款金额。【数据集请在文末添加顾问老师领取】
文件包括user.csv,order.cav,click.csv,loan.csv,loan_sum.csv
前 言
一般的大数据项目一般都分为两种,一种是批处理一种是流式处理,此次练习批处理使用hive和presto处理,流式处理使用SparkStreaming+kafka来处理
任务 1
一般情况下我们的user的数据都是存在自己的关系型数据库中,所以这里将 t_user 用户信息到 mysql 中,我们在从MySQL中将其导入到hdfs上,其他三个文件及,t_click,t_loan 和 t_loan_sum 直接导入到 HDFS 中。
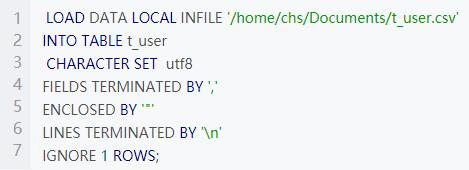
mysql自带csv导入功能所以先创建数据库和user表

导入数据
任务 2
利用 Sqoop 将 MySQL 中的 t_user 表导入到 HDFS 中,显示有哪些数据库
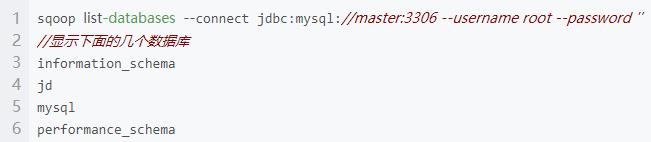
显示有哪些表

使用sqoop把MySQL中表t_user数据导入到hdfs的/data/sq目录下
sqoop import --connect jdbc:mysql://master:3306/jd --username root --password '' --table t_user --target-dir /data/sq出错了
18/08/21 13:44:26 ERROR tool.ImportTool: Import failed: No primary key could be found for table t_user. Please specify one with --split-by or perform a sequential import with '-m 1'.说是这个表中没有主键。我们可以建表的时候给它设置上主键,也可以使用下面–split-by来指定使用哪个字段分割
sqoop import --connect jdbc:mysql://master:3306/jd --username root --password '' --table t_user --target-dir /data/sq --split-by 'uid'又出错了

错误原因:因为我这里的hadoop集群使用了3台虚拟机,slave和slave2没有使用root用户访问MySQL的权限
进入mysql的控制台:
use mysql
select host,user,password from user;
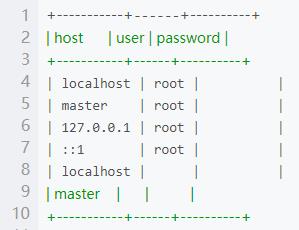
可以看到现在只有master有权限,给slave和slave2也设置权限

这才执行OK。查看导入后的hdfs上的目录hdfs dfs -ls /data/sq

查看每一部分的数据hdfs dfs -cat /data/sq
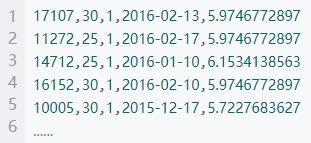
OK导入完成 剩下的几个CSV文件直接功过hadoop的put命令上传到hdfs上对应的目录即可。
任务 3
利用 Presto 分析产生以下结果,并通过 web 方式可视化:
各年龄段消费者每日购买商品总价值
男女消费者每日借贷金额
我们在使用presto做数据分析的时候,一般是跟hive联合起来使用,先从hive中创建相应的数据表,然后使用presto分析hive中的表。
启动hive
//启动hive的metastorenohup hive --service metastore >> /home/chs/apache-hive-2.1.1-bin/metastore.log 2>&1 &//启动hive servernohup hive --service hiveserver2 >> /home/chs/apache-hive-2.1.1-bin/hiveserver.log 2>&1 &//启动客户端 beeline 并连接beelinebeeline> !connect jdbc:hive2://master:10000/default hadoop hadoop
创建用户表

导入hdfs上的数据

创建用户订单表

导入hdfs上的数据

创建用户点击表

导入hdfs上的数据

创建借款信息表t_loan

导入hdfs上的数据

创建月借款总额表t_loan_sum

导入hdfs上的数据

启动Presto
在安装目录下运行 bin/launcher start
运行客户端 bin/presto –server master:8080 –catalog hive –schema default
连接hive !connect jdbc:hive2://master:10000/default hadoop hadoop
开始查询分析
第一题
select t_user.age,t_order.buy_time,sum(t_order.price*t_order.qty-t_order.discount) as sum from t_user join t_order on t_user.uid=t_order.uid group by t_user.age,t_order.buy_time;部分结果
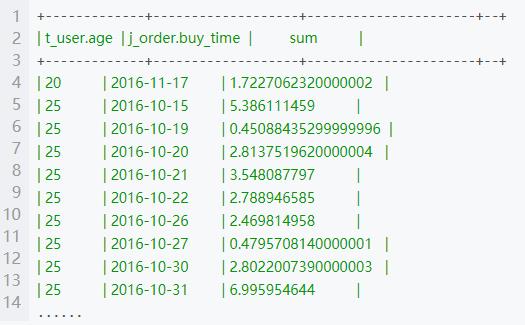
第二题
select t_user.sex,SUBSTRING(t_loan.loan_time,0,10) as time,sum(t_loan.loan_amount) as sum from t_user join t_loan on t_user.uid=t_loan.uid group by t_user.sex ,SUBSTRING(t_loan.loan_time,0,10);部分结果
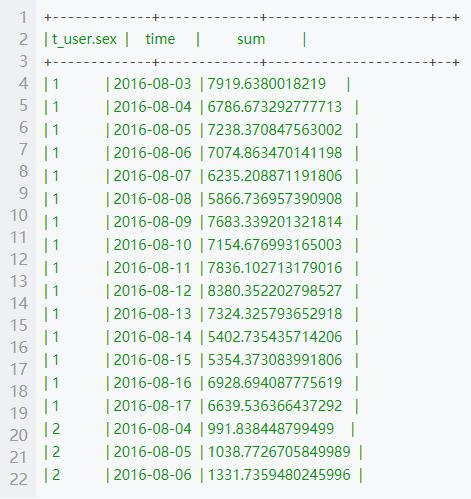
任务 4
利用 Spark RDD 或 Spark DataFrame 分析产生以下结果:
借款金额超过 2000(因为数据做过处理,这里就分析大于5的) 且购买商品总价值超过借款总金额的用户 ID
从不买打折产品且不借款的用户 ID
代码过长仅展示部分,完整代码请添加顾问领取
任务 5
利用 spark streaming 实时分析每个页面点击次数和不同年龄段消费总金额。
步骤:编写 Kafka produer 程序读取hdfs上的文件每隔一段时间产生数据,然后使用spark streaming读取kafka中的数据进行分析,分析结果写入到redis中。
(1)将 t_click 数据依次写入 kafka 中的 t_click 主题中,每条数据写入间隔为10 毫秒,其中 uid 为 key,click_time+” ,” +pid 为 value
代码过长仅展示部分,完整代码请添加顾问领取
运行结果
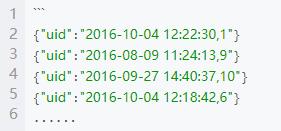
(2)将 t_order 数据依次写入 kafka 中的 t_order 主题中,每条数据写入间隔为10 毫秒,其中 uid 为 key,uid+” ,” +price + “,” + discount 为value
代码过长仅展示部分,完整代码请添加顾问领取
运行结果
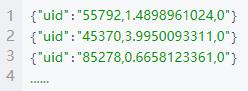
(3)编写 spark streaming 程序,依次读取 kafka 中 t_click 主题数据,并统计:每个页面累计点击次数,并存入 redis,其中 key 为” click+pid” ,value 为累计的次数

代码过长仅展示部分,完整代码请添加顾问领取
运行结果redis
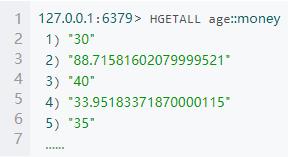
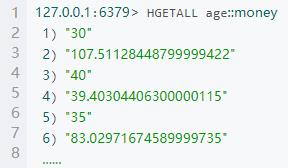
(4)编写 spark streaming 程序,依次读取 kafka 中 t_order 主题数据,并统计:不同年龄段消费总金额,并存入 redis,其中 key 为” age” ,value 为累计的消费金额
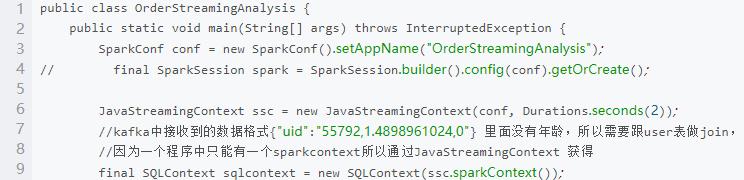
代码过长仅展示部分,完整代码请添加顾问领取
运行结果redis
End.
来源:CSDN
http://t.cn/A62W6INc
本文为转载分享,如侵权请联系后台删除
扫码添加职场老师微信领取【案例数据集+全部代码】
还可以获得职场老师生涯规划建议哦!
爱数据 · 6月公开课
直播主题:金融从业者:如何转行数据分析
课程亮点:
了解金融领域公司的行业最新动态
从金融转行其他行业的解决方案
风控类岗位转行的解决方案
银行柜员/理财经理等转行的解决方案
直播时间:6月4日 明晚20:30
点击“阅读原文”0元参与课程直播
以上是关于京东金融数据分析:MySQL+HIVE的结合应用案例详解附全代码的主要内容,如果未能解决你的问题,请参考以下文章