数据库运维工具化:一切从“简”,只为DBA更轻松
Posted 数据资产管理峰会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库运维工具化:一切从“简”,只为DBA更轻松相关的知识,希望对你有一定的参考价值。
众所周知,数据库的运维既是个技术活儿也是个苦差事,不仅要有广阔的知识面,强大的技术能力,对主机、存储、网络、操作系统也最好样样精通,而且还要会写SQL、shell、最好连Java也能拿下…同时,还需要拥有超强的耐心、谨慎的态度以及强健的体魄。
今天【DBA+社群】联合发起人邹德裕老师将告诉你如何让数据库运维简单化,如何减轻DBA的工作量及压力,提升效率,并且可以拥有更多时间去思考。
目录:
如何简单化
OraZ之路
OraZ后续计划开发或扩展功能
一如何简单化
1、第一个运维工具:ora
2008年刚进公司转做专职DBA,发现DBA竟然比以前干程序员还苦逼,通宵施工如家常便饭,而且有大量的重复工作。当时每个dba在共享服务器上都有自己的脚本集,每当应用侧有任何异动DBA们就找到自己的脚本集文件,然后替换条件复制粘贴执行,遇到没找到的就一顿狂敲键盘输SQL。特别是在遇到大故障时,身后便会围着一群人,有各方领导,还有开发商,里外好几层。那可真是令人抓狂,因为做过几年的开发,我便想,为何不做一个shell程序,统一入口,只要传入参数即可。于是我开发了第一个简单的Oracle运维工具,当时脚本集就叫ora。这个工具后来在运维团队不断被完善、扩散,至今仍在使用。

Ora脚本集的优点:
让日常监控、维护操作等标准化。
减少出错机会,提高效率。
让DBA从容应对故障应急。
缺点也是明显的,正是有了这个工具,现在很多DBA们到了非驻场的服务现场就不会写SQL了。(怪我喽…)
2、智能HANG分析
在运维期间碰到系统常发生HANG,当数据库发生在争夺内核级别的资源时,比如Latch等,在11G之前oracle不能自动的检测并处理这种死锁。这时候需用Hanganalyze工具dump资源持有的相互关系。当二线DBA到场时已基本Hang死,或无法登陆,即使能做出dump trace也无法反映真实原因。
另外分析trace定位堵塞源也要一定时间。所以分析出结果时往往应用已中断。既然hang住后要重启或终止掉所有前台发起数据库进程才能解决,何不在hang开始初期就发起自动hang分析,识别引起hang的源头,记录相关信息,终止源头。
具体过程如下:
1.通过等待事件识别Hang症状
2.根据上一步骤判断触发搜集hanganalyze
3. 分析hang的dump信息,并确认是否存在hang
4. 识别hang的源头记录相关信息并解决hang问题
这是我编写的第二个程序(由于该程序已申请了专利,代码在此就不分享了)。
注:在Oracle 11g 11.2.0.2版本发布后,其新特性中才出现了hang 管理器(Hang Manager)
HM配置参数(开启后会根据配置终止实例或进程,请谨慎使用):

3、小结
后面还有长事务、二阶段事务(DX锁)分析、自动生命周期管理、自动优化调度分析、自动巡检工具、离线巡检工具等等。如果你能把你日常需求做的工作工具化或自动化了,DBA就不是一个苦差活了。你也就有更多时间用来研究更深层次的技术了。
我只是一个会写程序却不安分的“懒”DBA。
二OraZ之路
至此越来越想做一个较为完整,能帮助DBA的工具。该工具将运行SQL查询视图监控数据库的性能,识别数据库存在的隐患。
数据库的运维工作包括部署安装、性能优化、备份容灾、故障恢复、预防性巡检等工作。这几个方面都存在不少重复度高、工作量大的任务,有的甚至还可以并行处理,这些都是该工具需解决的目标。
1、运行需求?
Oraz是基于JDBC+SSH的JAVA应用,监测和分析数据库实例活动,系统要求是相当简单,只需jdbc能连接上数据库即可,该工具不会安装任何额外软件在你的服务器和终端上。
2、Oraz目前能做什么
· 有关数据库和实例的一般信息。
· 有关数据库结构和数据存储的详细信息: 表空间,数据库文件重做日志、 归档的日志等。表空间/数据文件使用情况和可用空间
· 内存信息: SGA/PGA 组件和大小,共享的池和缓冲区缓存统计数据。
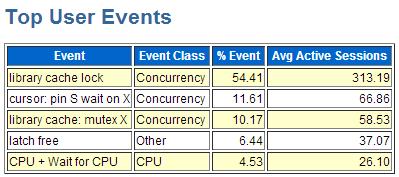
· 实例活动洞察-CPU消耗、 等待事件、 顶级的会话、 顶级SQL语句等。
· 会话信息-活动会话,排在前面的会话等。
· 顶尖的 SQL 语句和有关每个语句包括语句活动、 执行统计信息、 资源消耗、 执行计划、 版本等详细的信息。
· Oracle 数据库全系统统计信息、 操作系统统计、 指标和时间模型。
3、DBA日常运维之巡检
规避系统风险运维自动化体系形成之前,我们DBA的日常例行工作在总工作量中占比较高,很消耗人力,员工疲于奔命但工作效率不高,也很容易出差错。自动化平台把我们的员工从繁琐的常规工作中解放出来,更专注于做架构优化之类的有创造性的工作,效率也有了进一步的改善。
每日检查是工程师上班的第一件事,通过脚本来进行,脚本输出仅提示异常部分,检查内容例如:
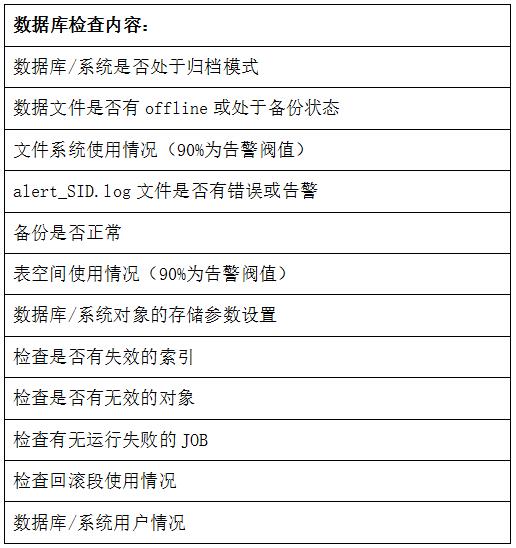
等,编写对应查询SQL,再通过JDBC访问远程服务器获取该值进行判断:
SELECT owner, constraint_name, table_name, status
FROM all_constraints
WHERE owner = '&OWNER' AND status = 'DISABLED' AND constraint_type = 'P';
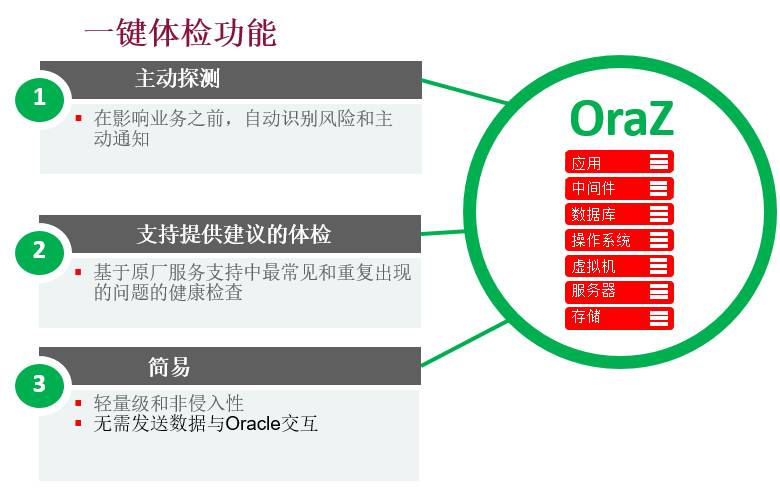
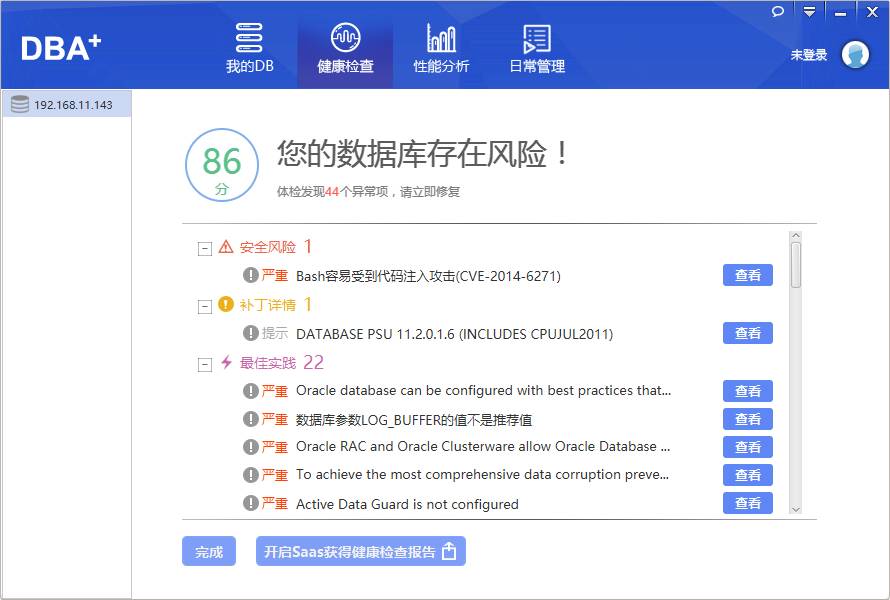
建立如360式的一键体检方式:
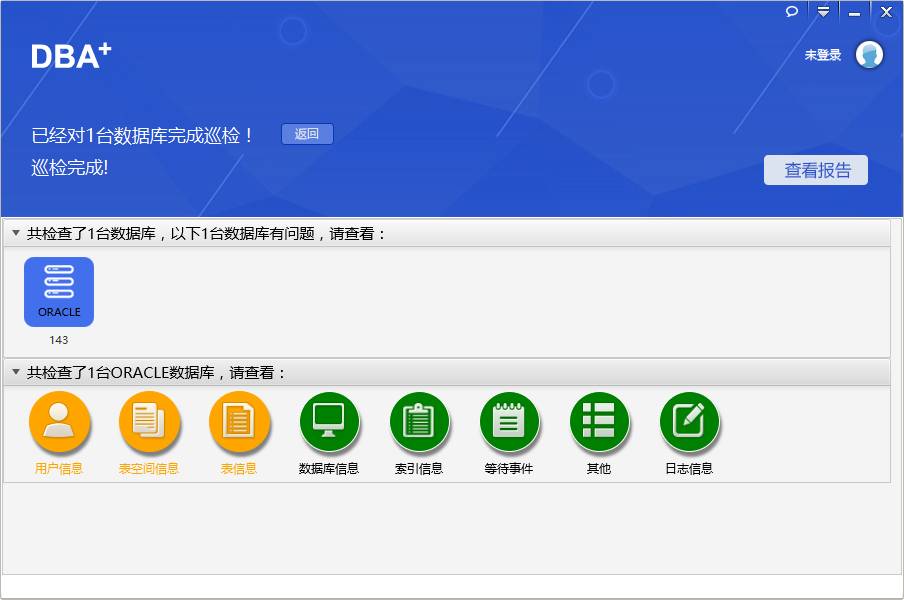

通过该体检功能可快速检测数据库问题;目前该巡检暂不支持自定义,可以考虑建立可通过saas平台分享的自定义巡检项。
4、实例活动洞察
实例活动洞察分析功能当前已同步发布更新,在很多情况下,当数据库发生性能问题的时候,我们是来不及收集足够的诊断信息的。或者收到告警,甚至问题发生的时候DBA根本不在场。这给我们诊断问题带来很大的困难。那么在这种情况下,我们是否能在事后收集一些信息来分析问题的原因呢。
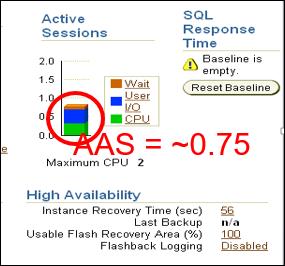
Oracle重器oem,而Top Activity功能是使用最为频繁的功能点:
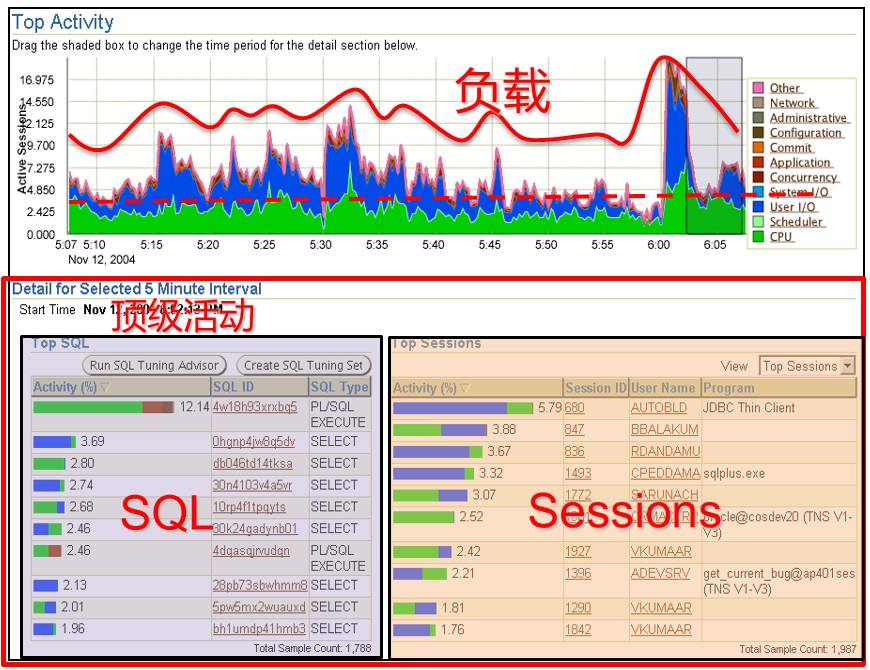
指定时段内的顶级消耗、会话等一目了然。上图中负载均以Average Active Sessions(AAS)平均活动会话进行计算。
每一个会话执行过程如下:

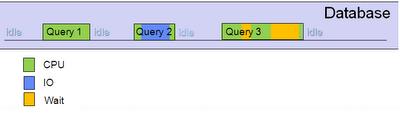
当有多个会话连接到库,并活动时:
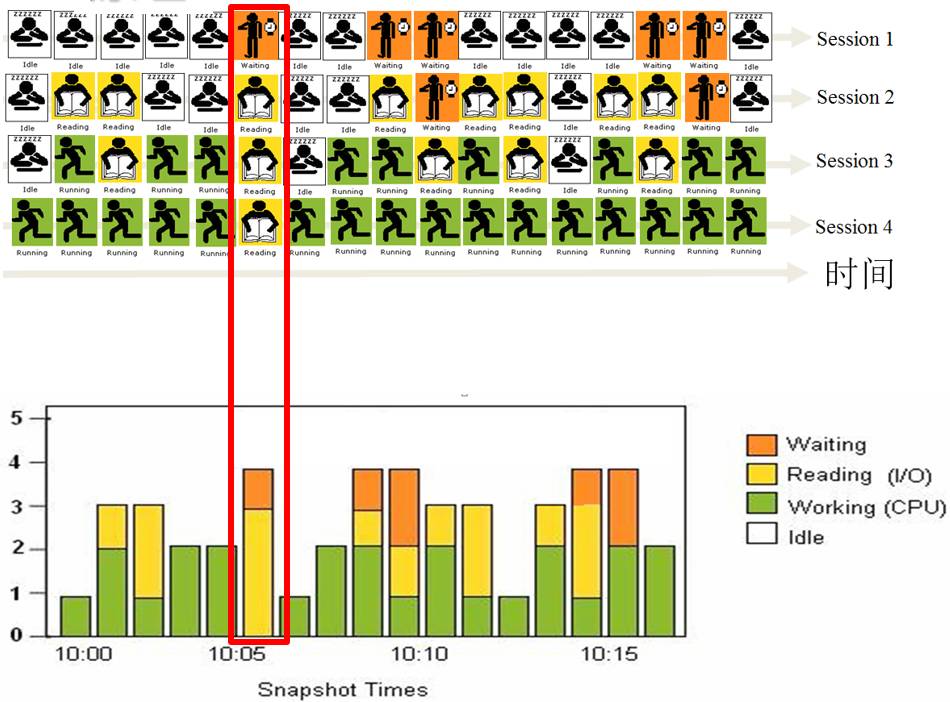
通过时间片段来看同一时刻有多少会话处于活动状态,该值为AAS值。以相同方法以sql语句维度统计该时刻活动,则找出顶级活动SQL,同样可以计算顶级活动program、user、会话等待。
由于DB Time=某一时段时间总和,故顶级活动SQL即为TOPSQL,所以AAS=DB Time / elapsed time (历时),之所以该指标叫做黄金指标,是因为通过AAS指标可以衡量一个系统的繁忙程度,这里有个CPU时间片概念,每一个CPU时间由操作系统分成CPU时间片,然后CPU时间片轮询模式分配给线程或进程(视操作新系统而定),在最小单位CPU片段内整个系统允许的最大允许数为cpu个数,故通过比较AAS值与CPU可以衡量数据库繁忙度,与CPU数量关联分析:
AAS/CPU_Count~= 0 非常空闲
AAS/CPU_Count<=0.5没堵塞
AAS /CPU_Count < 1 部分进程已达100%,应用开始出现缓慢
AAS/CPU_Count >或>> 1 出现性能问题或堵死、HANG状态
AAS在Oracle中OEM、ASH中的应用:
OEM中:
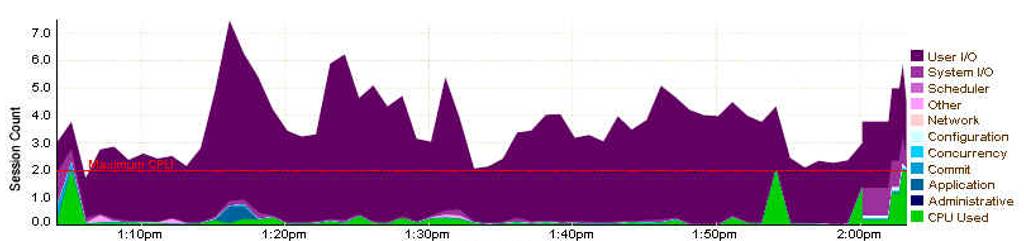
ASH中:
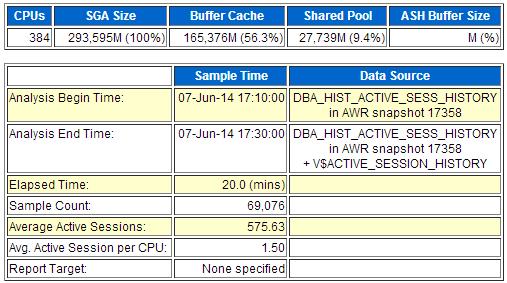
从Oracle 数据库 10g开始增加V$ACTIVE_SESSION_HISTORY视图,通过它可以容易地得知当前Instance的活动状态,主要是知道各个时刻系统都在等待哪些事件,通过对这些等待事件和相应等待次数的统计,就可以清晰地了解系统的历史工作负载特征和压力情况。此视图提供了大量宝贵的信息,而且不需要繁重的跟踪活动。
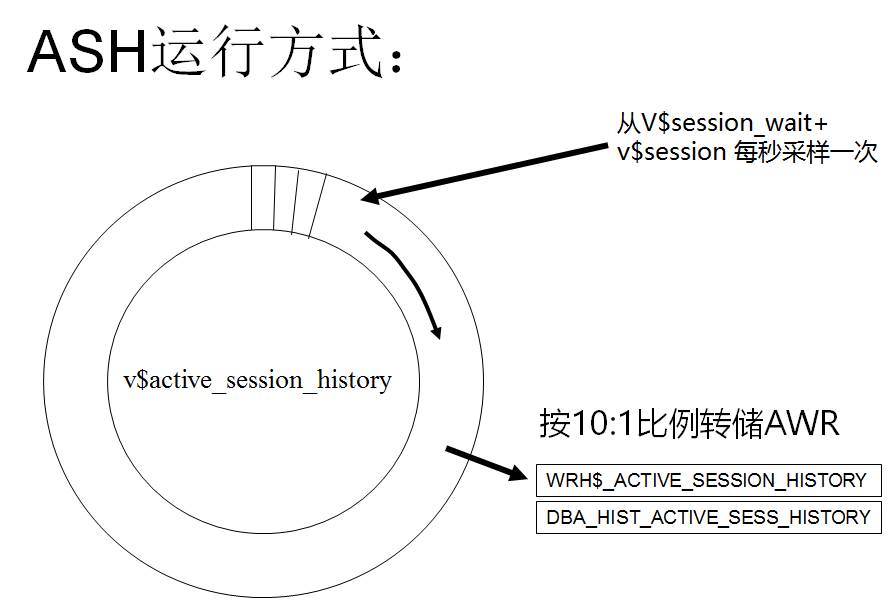
ASH数据采集由mmon进程与mmnl进程负责;
快照由MMON和MMNL后台进程自动地每隔固定时间采样一次。
MMON进程负责:
当某个测量值(metrics)超过了预设的限定值(threshold value)时提交警告
创建新的 MMON 隶属进程(MMON slave process)来进行快照(snapshot)
捕获最近修改过的 SQL 对象的统计信息
MMNL进程负责执行轻量级的且频率较高的后台任务,如捕获会话历史信息,测量值计算等。
AWR的采样工作由MMON进程每个1小时执行一次,ASH信息同样会被采样写出到AWR负载库中。ASH buffer根据被设计为保留1小时的信息,但很多时候这个内存是不够的,当ASH buffer写满后,另外一个后台进程MMNL将会主动将ASH信息写出。
ASH buffer大小
-按照公式Size of ASH Circular Buffer = Max [Min [ #CPUs * 2 MB, 5% of Shared Pool Size, 30MB ], 1MB ]计算,默认1M左右,该参数可以同隐含参数进行调整:
"_ash_size"隐含参数控制ash buffer的大小
ASH对应视图关系为:
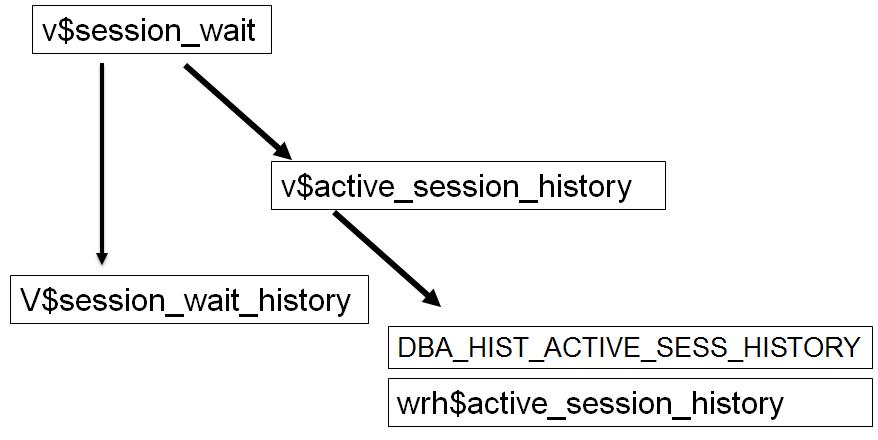
通过按分钟从v$active_session_history视图采集数据,展示如下:
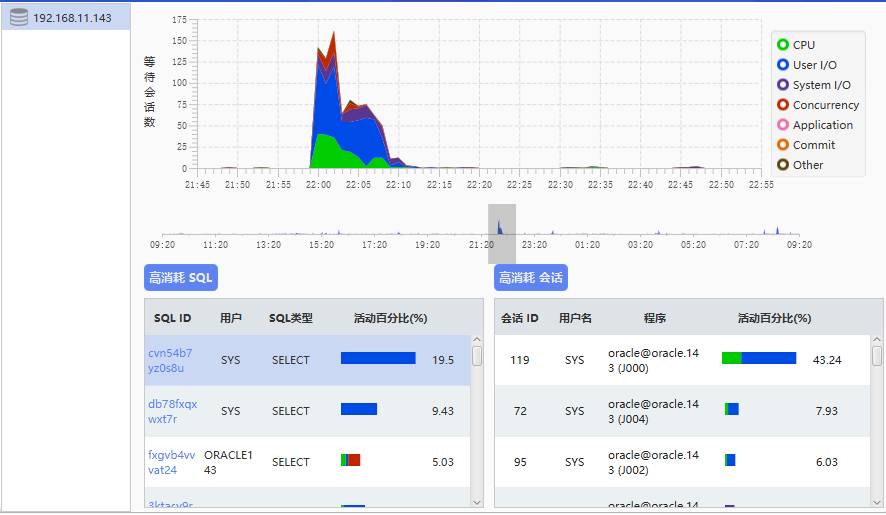
从上图可看到选择时段内TOPSQL为“cvn54b7yz0s8u”,占该时段内的19.5%,主要在等待IO资源。
三OraZ后续计划开发或扩展功能
表空间增加读写走势分析、碎片率分析
计划作业执行详细信息和当前正在运行的作业。
闪回去/快速恢复区使用情况和备份信息。
深度体检
进程跟踪(10046、10053)以及trace分析
自动化优化分析等
Alert日志查询图形化展示
深度体检功能预告
对于数据库、中间件设计,在系统上线前,针对应用系统的主要业务场景和应用要求,对数据库、中间件软硬件配置,系统参数和数据存储进行优化设计,包括但不限于如下内容:
数据库适用应用特点的最佳实践配置
性能及稳定性满足设计需求
系统与数据库特性及设置的最佳匹配
数据库版本对已知BUG的修复
花5-10分钟发现系统存在的风险
直接提供来自MOS推荐的专业解决方案
如果你所在部门有如运维自动化、标准化、可视化、一体化(集中化)这些需求建设,可以与我联系,我们有AMP(自动化运维平台)和APM(应用性能管理),即使是已部署了IxM的Txxxx软件的企业依然会再使用我们的产品。
Q1:OraZ在windows 2008 R2下无法运行?
A1:目前与将OraZ放中文目录存在不兼容问题,建议放英文目录,如d:\dbaplus。
Q2:此程序是否可以自己定制?
A2:目前暂不支持自定制功能。
Q3:是否考虑加上统计信息方面检查?
A3:非常好的建议,在下一版本的一键体检中会增加该检查项。
Q4:最新版本OraZ在哪里可以下载?
Q5:Hpux、AIX支持问题
A5:本人无小型机做测试,暂未无法验证支持型,OraZ是通过java开发,通过jdbc连接,理论上是支持的,后续我会寻找该测试环境的进行验证。
Q6:有些系统只能用telnet23端口,好像工具不能用23端口连接?
A6:目前仅支持ssh协议,即22端口。
Q7:是否可以考虑把SQL_MONITOR功能也集成进去?
A7:非常好的建议,会纳入后续考虑功能列表。
Q8:是否支持mysql?
A8:当前版本在一键体检中支持Mysql,其它专用工具会根据需求逐步更新。
作者介绍:邹德裕
新炬网络首席专家,DBA+社群联合发起人。
OraZ产品作者,轻维软件产品架构师。
十年以上运维管理经验,Oracle OCM,精通Oracle9i、10g和11g数据库技术和Linux/Unix技术。
对数据库系统架构具有深刻的理解,并在数据库诊断、故障排除、优化、架构设计等方面具有丰富的经验。
点击下方【阅读原文】即可下载OraZ工具
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看王佩《基于Docker的mysql mha 的集群环境构建实践》;
回复020,看王津银《互联网运维的整体理念与最佳实践》
DBA+社群是中国最大的涵盖各种架构师、数据库、中间件的微信社群!线上分享2次/周、线下沙龙1次/月,顶级峰会6次/年,直接受众10000+,间接影响50万+ITer。DBA+社群致力于搭建一个学习交流、专业人脉、跨界合作的公益平台,更多精彩请持续关注dbaplus微信订阅号!
扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA
点击下方【阅读原文】下载OraZ工具
以上是关于数据库运维工具化:一切从“简”,只为DBA更轻松的主要内容,如果未能解决你的问题,请参考以下文章