进阶 | 重新认识Angular
Posted 腾讯IMWeb前端团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进阶 | 重新认识Angular相关的知识,希望对你有一定的参考价值。
| 导语 本文跟随着Angular的变迁聊聊这个框架,分享一些基础的介绍,以及个人的理解。 也用过其他框架,像React和Vue。 但与Angular结识较深,或许也是缘分吧。
谈谈Angular
内容概要
数据绑定 (updated)
模块化组织 (new)
依赖注入
路由和lazyload (new)
Rxjs (new)
预编译AOT (new)
拥抱变化,迎接未来
updated: 原有特性,有更新
new: 新增特性
数据绑定
常用模版绑定
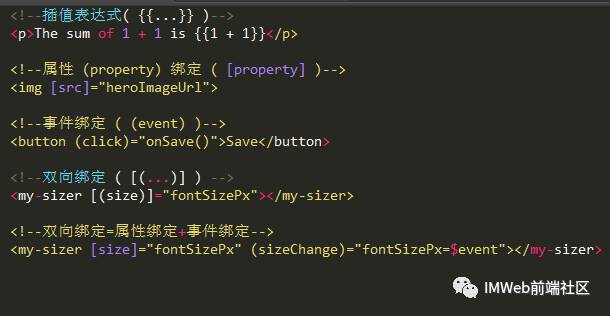
常用模版引擎
1. String-based 模板技术
基于字符串的parse和compile过程:
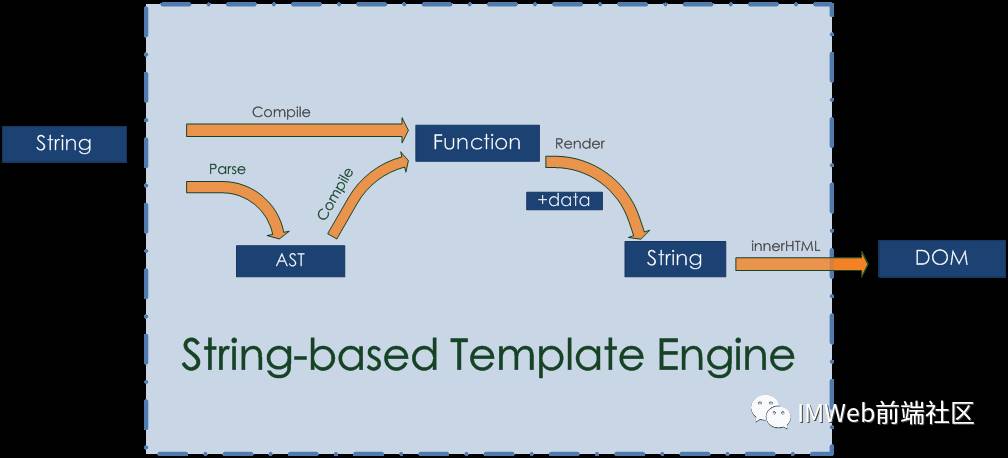
字符串模板强依赖于innerhtml(渲染), 因为它的输出物就是字符串。
2. Living templating 技术
基于字符串的parse和基于dom的compile过程:
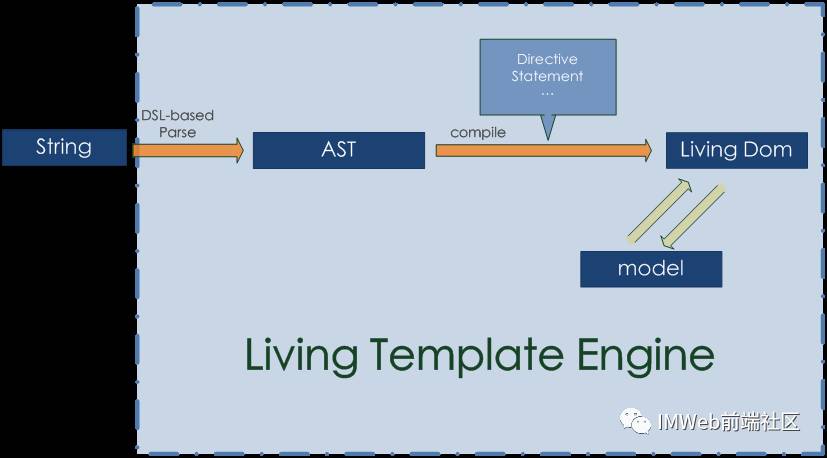
事实上,Living template的compile过程相对与Dom-based的模板技术更加纯粹, 因为它完全的依照AST生成,而不是在原Dom上的改写。
首先我们使用一个内建DSL来解析模板字符串并输出AST。
结合特定的数据模型(在regularjs中,是一个裸数据), 模板引擎层级游历AST并递归生成Dom节点(不会涉及到innerHTML)。
与此同时,指令、事件和插值等binder也同时完成了绑定,使得最终产生的Dom是与Model相维系的,即是活动的。
3. Dom-based 模板技术
基于Dom的link或compile过程:
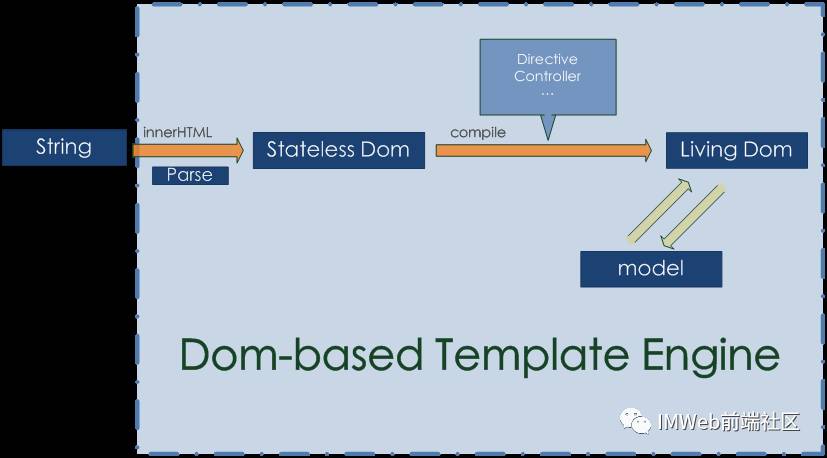
Dom-based的模板技术事实上并没有完整的parse的过程(先抛开表达式不说),如果你需要从一段字符串创建出一个view,你必然通过innerHTML来获得初始Dom结构. 然后引擎会利用Dom
API(attributes, getAttribute, firstChild… etc)层级的从这个原始Dom的属性中提取指令、事件等信息,继而完成数据与View的绑定,使其”活动化”。
所以Dom-based的模板技术更像是一个数据与dom之间的“链接”和“改写”过程。
以上内容参考:《一个对前端模板技术的全面总结》
数据更新Diff
框架的数据更新:
React => 虚拟DOM
Vue => getter/setter
Angular => 脏检查
React
使用虚拟DOM进行Diff。Virtual DOM本质上就是在JS和DOM之间做了一个缓存。
Virtual DOM 算法:
1. 用JS对象模拟DOM树。
用javascript对象结构表示DOM树的结构;然后用这个树构建一个真正的DOM树,插到文档当中。
2. 比较两棵虚拟DOM树的差异。
当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,通过深度优先遍历两棵树,每层的节点进行对比,记录两棵树差异。
3. 把差异应用到真正的DOM树上。
把 2 所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了。
分享文章:《深度剖析:如何实现一个 Virtual DOM 算法》。
Vue
1. Vue1:使用getter/setter Proxy进行更新。
Vue使用的发布订阅模式,是点对点的绑定数据。
Proxy可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。
这里在对数据进行赋值和读取的时候,都会进行Proxy,然后点对点更新数据。
2. Vue2:使用虚拟DOM进行Diff。
参考React的虚拟DOM。
Angular
核心:使用脏检测(新/旧值比较)Diff
当Model发生变化,会检测所有视图是否绑定了相关数据,再更改视图
Zone.js(猴子补丁:运行时动态替换)
将Javascript中异步任务包裹一层,使其运行在Zone上下文中
每一个异步任务为一个Task,提供钩子函数(hook)
Angular2+变化
zone.js对异步任务进行跟踪
脏检查计算放进worker
Angular2+中树结构,自上而下进行脏检查(Angular1中的带有环的结构)
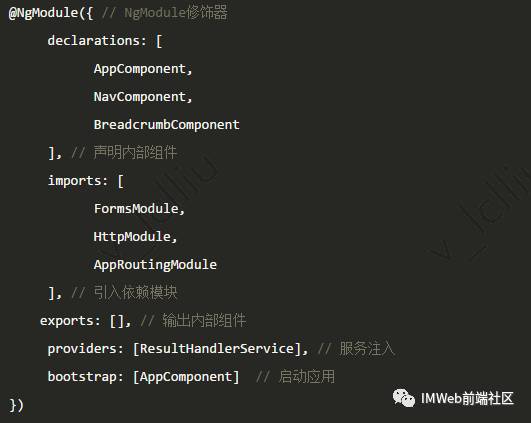
模块化组织
Angular模块
Angular模块把组件、指令和管道打包成内聚的功能块,每个模块聚焦于一个特性区域、业务领域、工作流或通用工具。
模块化思想
功能模块抽象层层放射到整个应用程序。

模块化思想层层包裹,结构组织也层层地抽象封装,树结构的设计思想从模块组织到依赖注入延伸。
模块修饰器
修饰器(Decorator)是一个函数,用来修改类的行为。
注意,修饰器(Decorator)并不是Typescript特性,而是ES6的特性。
ES2017引入了这项功能,目前Babel转码器已经支持。
依赖注入
Angular的依赖注入可谓是灵魂了,之前有篇详细讲这个的文章《谈谈Angular2中的依赖注入》。
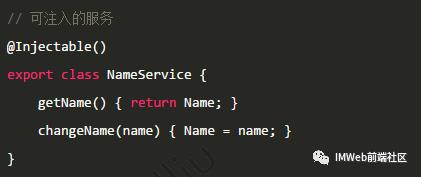
什么是依赖注入
依赖注入在项目中,体现为项目提供了这样一个注入机制:
有人负责提供服务,有人负责消耗服务,而这样的机制提供了中间的接口,并替使用者进行了创建并初始化这样的处理。
我们只需要知道,拿到的是完整可用的服务就好了,至于这个服务内部的实现,甚至是它又依赖了怎样的其他服务,都不需要关注。
依赖注入与状态管理
状态管理:
Angular:依赖注入服务来共享一些状态
其他框架(React/Vue)的状态管理:组件传递、bus总线、事件传递、状态管理工具Redux/Flux/Vuex
其实像我们设计一个项目,自行封装的一些组件和服务,然后再对它们的新建和初始化等等,也经常需要用到依赖注入这种设计方式的。
我们的服务也可以分为有记忆的和无记忆的,关键在于抽象完的组件是否内部记录自身状态,以及怎样维护这个状态等等,甚至设计不合理的话,这样的状态管理会经常使我们感到困扰,所以Redux、Flux和Mobx这样的状态管理框架也就出现了。
而Angular在某种程度上替我们做了这样的工作,并提供我们使用。
在Angular里面我们常常通过服务来共享一些状态的,而这些管理状态和数据的服务,便是通过依赖注入的方式进行处理的。
依赖注入还有有个很棒的地方,就是单元测试很方便,测试的时候也注入需要的服务就好了。
多级依赖注入
多级依赖注入:组件树与注入器树平行。
一个Angular应用是一个组件树,同时每个组件实例都有自己的注入器,组件的树与注入器的树平行。
现在树结构已经在前端领域越来越流行了,浏览器的DOM树/CSS规则树、React的虚拟DOM、以及Angular(其实不只是Angular)的组件树和注入器树。
上面也说道,并不是所有的组件都会注入服务的,所以有了”注入器冒泡”:
当一个组件申请获得一个依赖时,Angular先尝试用该组件自己的注入器来满足它。如果该组件的注入器没有找到对应的提供商,它就把这个申请转给它父组件的注入器来处理。
路由和lazyload
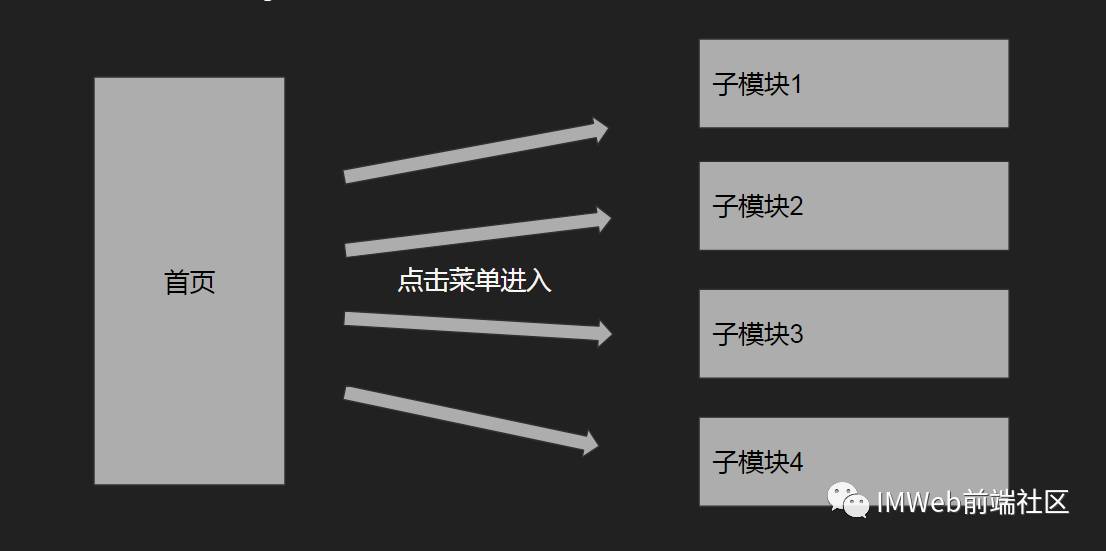
像我们打包页面,很多时候最终生成了一个bundle.js文件。这样,每次当我们请求页面的时候,都请求整个bundle.js并加载,有了Webpack或许我们只需要加载其中的某些模块,但还是需要请求到所有的代码。
很多时候我们或许不需要进入所有的模块,这个时候浪费了很多的资源,同时首屏体验也受到了影响。
通过路由的lazyload以及上面提到的模块化,我们可以把每个lazyload的模块单独打包成一个分块bundle文件,当进入模块时才请求和加载,当我们的业务规模很大的时候,首屏速度得到大幅度提升。
Rxjs
很多时候我们都拿Rxjs和Promise来比较,但其实它们有很大的不一致。
以下很多内容来自《不要把Rx用成Promise》。
核心思想: 数据响应式
Promise => 允诺
Rxjs => 由订阅/发布模式引出来

Promise顾名思义,提供的是一个允诺,这个允诺就是在调用then之后,它会在未来某个时间段把异步得到的result/error传给then里的函数。
Rx不是允诺,它本质上还是由订阅/发布模式引出来的,它的核心思想就是数据响应式,源头是数据产生者,经过一系列的变换/过滤/合并的操作,被数据消费者所使用,数据消费者何时响应,完全取决于数据流何时能流下来。
执行和响应
1. Promise需要then()或catch()执行,并且是一次性的。
Promise需要调用then或者catch才能够执行,catch是另一种形式的then,调用then或者catch之后,它返回一个新的Promise,这样新的Promise也可以同样被调用,所以可以做成无限的then链。
2. Rxjs数据的流出不取决于是否subscribe(),并且可以多次响应。
Rx的数据是否流出不取决于是否subscribe,也就是说一个observable在未被订阅的时候也可以流出数据,在之后它被订阅过后,先前的数据是无法被数据消费者所查知,所以Rx还引入了一个lazy模式,允许数据缓存着直到被subscribe,但是数据是否流出还是并不依赖subscribe。
Rx的observable被subscribe之后,并不是继续返回一个新的observable,而是返回一个subscriber,这样用来取消订阅,但是这也导致了链式断裂,所以它不能像Promise那样组成无限then链。
数据源头和消费
1. Promise没有确切的数据消费者,每一个then都是数据消费者,同时也可能是数据源头,适合组装流程式(A拿到数据处理,完了给B,B完了把处理后的数据给C,以此类推)。
Promise的数据是一次性流出的,因为Promise内部维持着状态,初始化的pending,转成resolved或者rejected之后,状态就不可逆转了。
举例说promise().then(A).then(B).then(C).catch(D),数据是顺着链以此传播,但是只有一次,数据从A到B之后,A这个promise的状态发生了改变,从pedding转成了resolved,那么它就不可能再产生内容了,所以这个promise已经不是活动性的了。
2. Rxjs则有明确的数据源头,以及数据消费者。
Rx则不同,我们从Rx的接口就可以知道,它有onNext,onComplete和onError,onNext可以响应无数次,这也是符合我们对数据响应式的理解,数据在源头被隔三差五的发出,只要源头认为没有流尽(onComplete)或者出了问题(onError),那么数据就可以不断的流到响应者那边。
Rxjs例子
用AOT进行编译
JIT
JIT编译导致运行期间的性能损耗。由于需要在浏览器中执行这个编译过程,视图需要花更长时间才能渲染出来。
由于应用包含了Angular编译器以及大量实际上并不需要的库代码,所以文件体积也会更大。更大的应用需要更长的时间进行传输,加载也更慢。
AOT
预编译(AOT)会在构建时编译,这样可以在早期截获模板错误,提高应用性能。
AOT使得页面渲染更快,无需等待应用首次编译,以及减少体积,提早检测模板错误等等。
预编译(AOT) vs 即时编译(JIT)
只有一个Angular编译器,AOT和JIT之间的差别仅仅在于编译的时机和所用的工具。
使用AOT,编译器仅仅使用一组库在构建期间运行一次;
使用JIT,编译器在每个用户的每次运行期间都要用不同的库运行一次。
拥抱变化,迎接未来
身为框架,Angular和React、Vue各有各的优劣,哪个更适合则跟产品设计、应用场景以及团队等各种因素密切相关,没有谁是最好的,只有当前最适合的一个。
Angular的经常性不兼容、断崖式升级,或许对开发者不大友好。
但它对新事物的接纳吸收、勇于颠覆自身,是面向未来开发的好榜样。
我们也何尝不是,为何要死守某个框架、某种语言,或是争好坏、分高下。
何尝不抱着开放的心态,拥抱变化,然后迎接未来呢?
结束语
以上只是本人的个人理解,或许存在偏差。世上本就没有十全十美的事物,大家都在努力地相互宽容和理解。
那些我们想要分享的东西,肯定是存在很棒的亮点。而我们要做的,是尽力把自己看到的那完美的一面呈现给大家。
与其进行口水之争,取精辟,去糟粕,不更是面向未来的方式吗?
参考
《Angular的变革》
《Angular2 脏检查过程》
《预 (AoT) 编译器》
扫码下方二维码,
随时关注更多前端干货文章!
▼
微信:IMWebTech
以上是关于进阶 | 重新认识Angular的主要内容,如果未能解决你的问题,请参考以下文章