神经网络低比特量化——LSQ
Posted AI异构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络低比特量化——LSQ相关的知识,希望对你有一定的参考价值。
LSQ
本文为IBM的量化工作,发表在ICLR 2020。论文题目:Learned Step Size Quantization。为了解决量化精度越低,模型识别率越低的问题,本文引入了一种新的手段来估计和扩展每个权重和激活层的量化器步长大小的任务损失梯度,并在 ImageNet 上的实验和分析证明了所提出的方法的有效性, 实现了ResNet 4 bit量化不掉精度!
论文链接:https://arxiv.org/abs/1902.08153 源码链接(非官方复现):https://github.com/zhutmost/lsq-net
摘要
在推理时以低精度操作运行的深度网络比高精度具有功耗和存储优势,但需要克服随着精度降低而保持高精度的挑战。在这里,本文提出了一种训练此类网络的方法,即 Learned Step Size Quantization,当使用来自各种架构的模型时,该方法在 ImageNet 数据集上实现了 SOTA 的精度,其权重和激活量化为2、3或4 bit 精度,并且可以训练达到全精度基线精度的3 bit 模型。本文的方法建立在现有的量化网络中学习权重的方法基础上,通过改进量化器本身的配置方式。具体来说,本文引入了一种新的手段来估计和扩展每个权重和激活层的量化器步长大小的任务损失梯度,这样它就可以与其他网络参数一起学习。这种方法可以根据给定系统的需要使用不同的精度水平工作,并且只需要对现有的训练代码进行简单的修改。
方法
量化计算公式
-
s为量化的 STEP SIZE 可学习参数。 s即是数据的缩放因子,又能控制数据截断的边界。 -
针对weights: -
针对data:
STEP SIZE GRADIENT
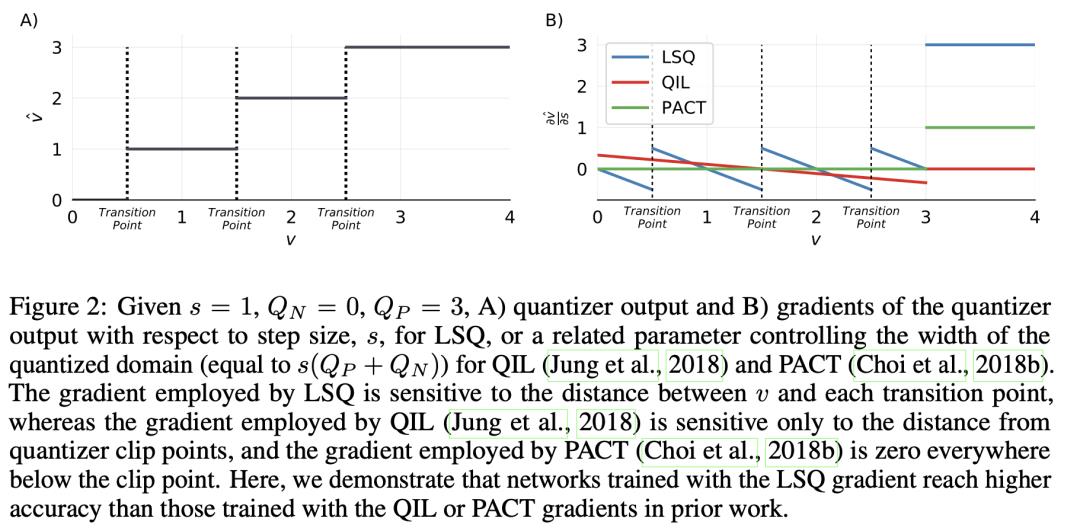
STEP SIZE GRADIENT SCALE
当量化比特数增加时,step-size会变小,以确保更为精细的量化;而当量化比特数减少时,step-size会变大。为了让step-size的参数更新,能够适应量化比特数的调整,需要将step-size的梯度乘以一个scale系数。
-
权重: , 代表当前层的权重数。 -
激活: , 代表当前层的特征数。
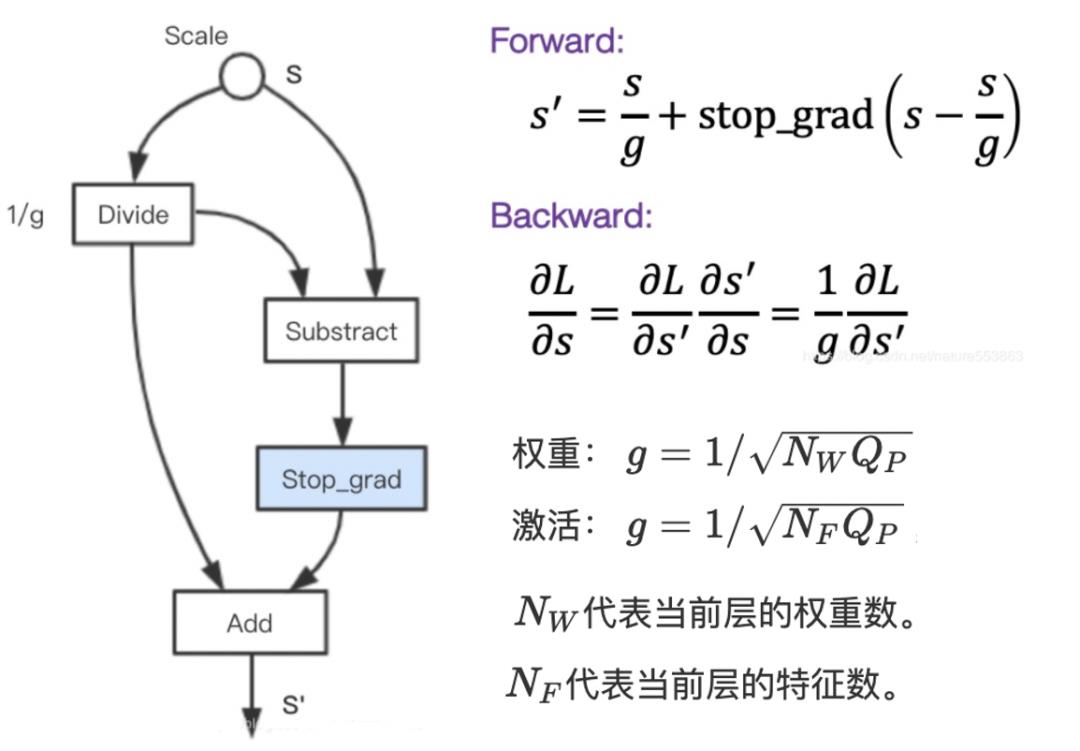
直通估计器
量化的权重和激活用于前向和反向传递,通过 Bengio 提出的直通估计器(STE)计算,如下公式:
实验结果
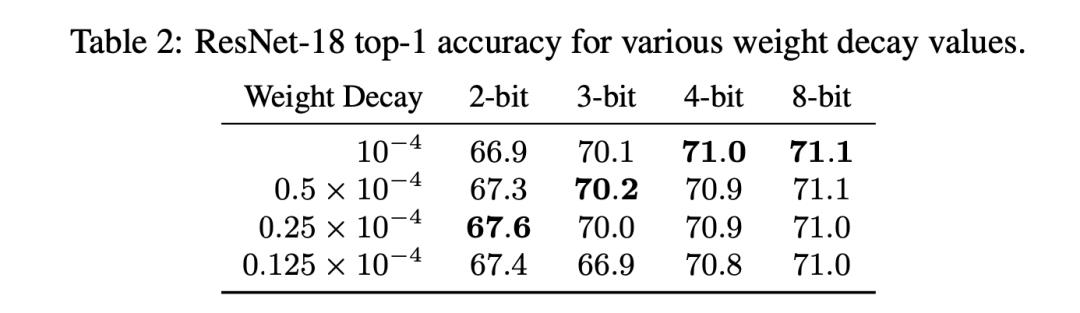
Weight Decay
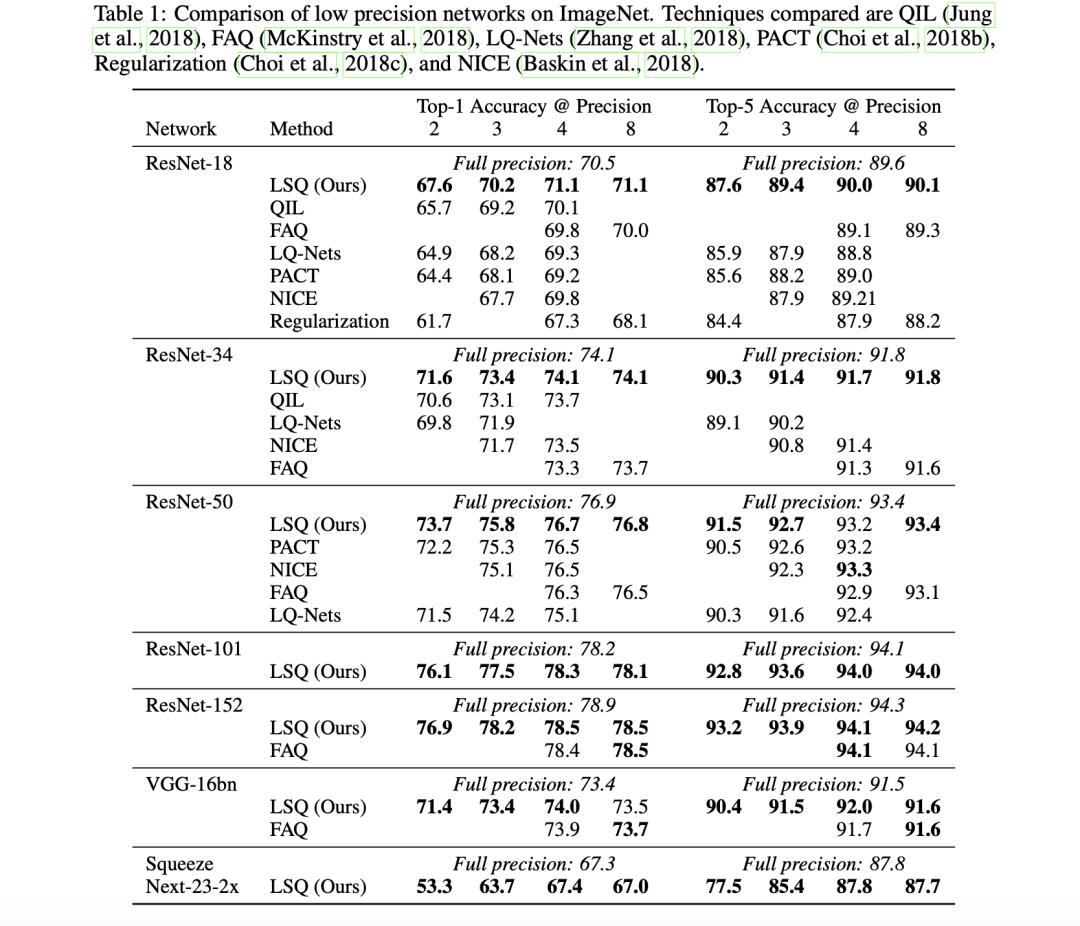
ImageNet
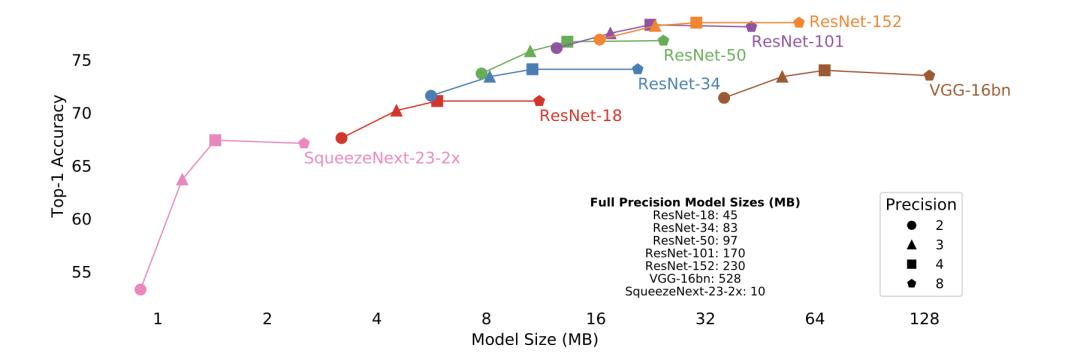
Accuracy VS. Model Size
消融实验
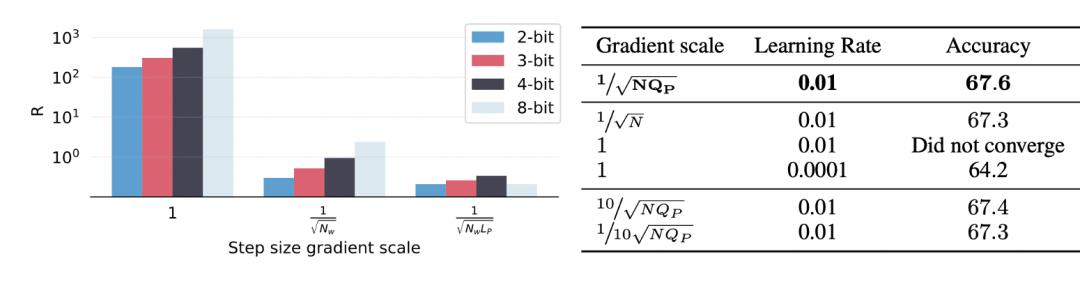
Step Size Gradient Scale Impact
添加知识蒸馏提高精度
以上是关于神经网络低比特量化——LSQ的主要内容,如果未能解决你的问题,请参考以下文章