“黑”掉神经网络:腾讯披露新型AI攻击手法,主流机器学习框架受影响
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“黑”掉神经网络:腾讯披露新型AI攻击手法,主流机器学习框架受影响相关的知识,希望对你有一定的参考价值。
8 月 19 日,第 19 届 XCon 安全焦点信息安全技术峰会于北京举行,腾讯朱雀实验室首度亮相。据介绍, 朱雀实验室专注于实战级综合攻击研究及 AI 安全技术研究,以攻促防 。
会上,腾讯朱雀实验室高级安全研究员 nEINEI 分享了 AI 安全方向的最新研究成果:模拟实战中的黑客攻击路径,摆脱传统利用“样本投毒”的 AI 攻击方式,直接控制 AI 模型的神经元,为模型“植入后门”,在几乎无感的情况下,可实现完整的攻击验证。
据称,这是国内首个利用 AI 模型文件直接产生后门效果的攻击研究。该手法更贴近 AI 攻击实战场景,对于唤醒大众对 AI 模型安全问题的重视、进行针对性防御建设具有重要意义。
腾讯安全平台部负责人杨勇表示,当前 AI 已融入各行各业,安全从业者面临着更复杂、更多变的网络环境,我们已经看到了网络攻击武器 AI 化的趋势,除了框架这样的 AI 基础设施,数据、模型、算法,任何一个环节都是攻防的前线。作为安全工作者,必须走在业务之前,做到技术的与时俱进。
随着人工智能成为“新基建”七大版块中的重要一项,AI 产业应用进一步驶入深水区,并与诸多技术领域广泛交叉。
然而,人工智能在带来便利之余,却也暗含巨大的安全隐患:几句含糊不清的噪音,智能音箱或许就能被恶意操控使得家门大开;一个交通指示牌上的小标记,就可能让自动驾驶车辆出现严重事故。在工业、农业、医疗、交通等各行业与 AI 深度融合的今天,如果 AI 被“攻陷”,后果将不堪设想。
实际上,AI 被黑的难度并不大,典型的就是对抗样本现象的存在。而以深度学习为代表的人工智能技术,亦或是强化学习,都存在被“愚弄”的情况。据腾讯朱雀实验室介绍,当前人工智能场景的实现依赖于大量数据样本,通过算法解析数据并从中学习,从而实现机器对真实世界情况的决策和预测。但数据却可能被污染,即“数据投毒,使算法模型出现偏差”。已有大量研究者通过数据投毒的方式,实现了对 AI 的攻击模拟。当前 AI 的安全风险主要集中在数据搜集阶段和预测阶段,模型部署、模型架构方面的安全问题还不是十分突出。
随着技术研究的不断深入,安全专家也开始探索更高阶的攻击方式,通过模拟实战中的黑客攻击路径,从而针对性的进行防御建设。腾讯朱雀实验室发现,通过对 AI 模型文件的逆向分析,可绕过数据投毒环节,直接控制神经元,将 AI 模型改造为后门模型。甚至在保留正常功能的前提下,直接在 AI 模型文件中插入二进制攻击代码,或是改造模型文件为攻击载体来执行恶意代码,在隐秘、无感的情况下,进一步实现对神经网络的深层次攻击。
如果将 AI 模型比喻为一座城,安全工作人员就是守卫城池的士兵,对流入城池的水源、食物等都有严密监控。但黑客修改神经元模型,就好像跳过了这一步,直接在城内“空投”了一个木马,用意想不到的方式控制了城市,可能带来巨大灾难。
腾讯朱雀实验室在分享中展示了三种 AI 模型高阶攻击手法。
第一种攻击方式是“AI 供应链攻击”,通过逆向破解 AI 软件,植入恶意执行代码,AI 模型即变为大号“木马“,受攻击者控制。如被投放到开源社区等,则可造成大范围 AI 供应链被污染。
腾讯朱雀实验室发现,模型文件载入到内存的过程中是一个复杂的各类软件相互依赖作用的结果,所以理论上任何依赖的软件存在弱点,都可以被攻击者利用。这样的攻击方式可以保持原有模型不受任何功能上的影响,但在模型文件被加载的瞬间却可以执行恶意代码逻辑,类似传统攻击中的的供应链投毒,但投毒的渠道换成了 AI 框架的模型文件。
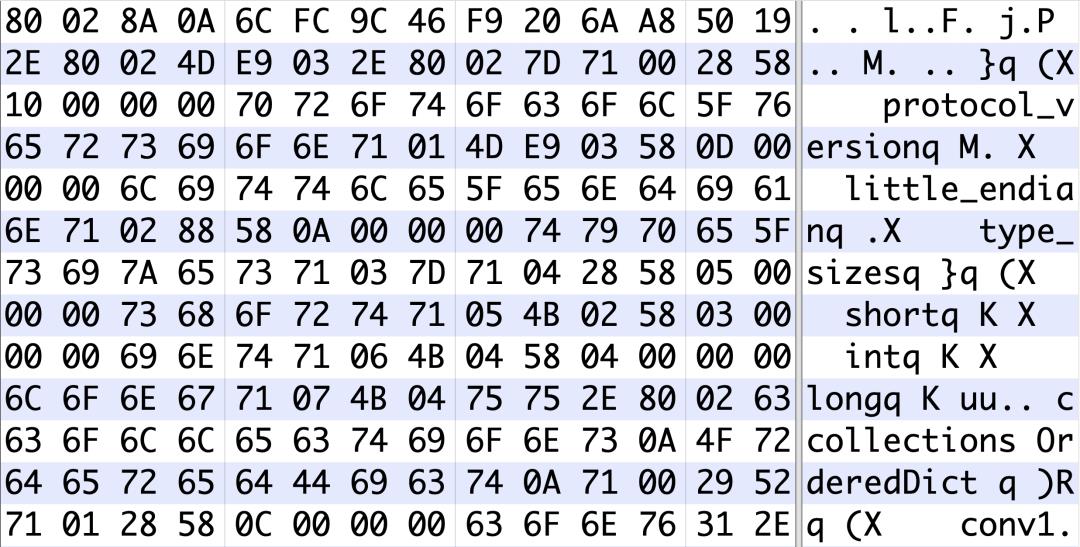
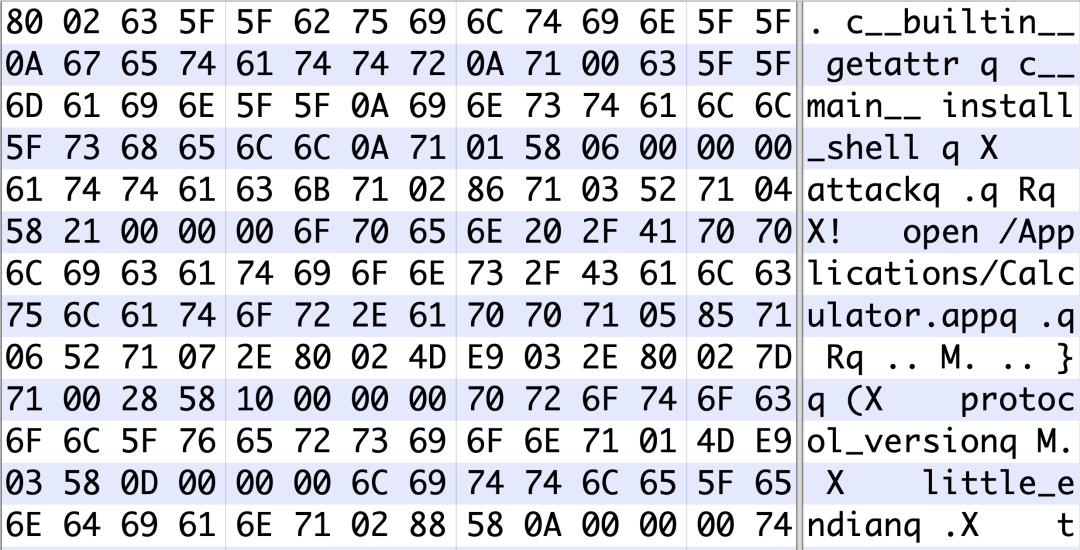
第二种攻击方式是“重构模型后门”,通过在供给端修改文件,直接操纵修改 AI 模型的神经元,给 AI 模型“植入后门”,保持对正常功能影响较小,但在特定 trigger 触发下模型会产生定向输出结果,达到模型后门的效果。
“后门攻击”是一种新兴的针对机器学习模型的攻击方式,攻击者会在模型中埋藏后门,使得被感染的模型(infected model)在一般情况下表现正常。但当后门触发器被激活时,模型的输出将变为攻击者预先设置的恶意目标。由于模型在后门未被触发之前表现正常,因此这种恶意的攻击行为很难被发现。
腾讯朱雀实验室从简单的线性回归模型和 MNIST 开始入手,利用启发算法分析模型网络哪些层的神经元相对后门特性敏感,最终验证了模型感染的攻击可能性。在保持模型功能的准确性下降很小幅度内(~2%),通过控制若干个神经元数据信息,即可产生后门效果,在更大样本集上验证规模更大的网络 CIFAR-10 也同样证实了这一猜想。
相比投毒,这种攻击方式更为隐蔽,在攻击端直接操纵修改 AI 模型的同时,还能将对模型正常功能的影响降至最低,只有在攻击者设定的某个关键点被触发时,才会扣下攻击的扳机。



第三种攻击手法是通过“数据木马”在模型中隐藏信息,最终通过隐藏信息实现把 AI 模型转换为可执行恶意代码的攻击载体。
这种攻击手法是针对人工神经网络的训练与预测都是通过浮点运算(指浮点数参与浮点计算的运算,这种运算通常伴随着因为无法精确表示而进行的近似或舍入)的特性完成的。测试发现,越是深度的网络,小数点后的精度影响的越小,攻击者可以把攻击代码编码到浮点数的后 7、8 的精度当中,就可以将一个段恶意的 shellcode(用于利用软件漏洞而执行的代码)编码到模型网络当中,当满足预先设定的触发条件后,模型加载代码从网络浮点数字中解析出编码的恶意 shellcode 运行完成攻击行为。
据介绍,对于这一新型攻击手段,TensorFlow、PyTorch 等主流机器学习框架均可能受到影响。 这一攻击方式直接面对的是模型信息而不限于使用的是哪种模型框架,除了第一种攻击手法和具体的利用手段有关,后面两种攻击思路都会影响到当前流行的机器学习框架。
不过,开发者也不必过于草木皆兵。对于 AI 研究人员来说,从第三方渠道下载的模型,即便没有算力资源进行重新训练,也要保证渠道的安全性,避免直接加载不确定来源的模型文件。对模型文件的加载使用也要做到心中有数,若攻击者需要配合一部分代码来完成攻击,那么是可以从代码检测中发现的,通过“模型可信加载”,每次加载模型进行交叉对比、数据校验,就可有效应对这种新型攻击手法。
关于该攻击发现对未来 AI 安全防御的意义,腾讯朱雀实验室表示, 模型文件如今已经不能简单地被看待。过去大家一般认为模型文件包含辛苦训练的结果,有研究成果泄露的风险。但目前模型文件是存在攻击界面的,既可被传统的攻击所利用,也可以变相导致模型出现定向预测错误的风险。例如配合传统的漏洞利用技术,操作内存中的模型神经元就可以毒化 AI 模型,达到实战级别的一发命中效果。而作为硬件神经网络木马也已经有了相关技术研究,如果硬件神经网络木马改为动态设计,那么危害将会非常大。例如正常的模型网络可以在接受特定触发器后,动态调整神经元数值变成一个后门模型,执行后又恢复原有结果,难以被额外检测技术发现。
近几年我们已经看到网络攻击武器 AI 化的趋势, 腾讯朱雀实验室也将持续 研究相关的安全防御建设,特别是多方计算、共享模型的场景下,对模型文件的保护应该在研发阶段就提前考虑。
你也「在看」吗? 以上是关于“黑”掉神经网络:腾讯披露新型AI攻击手法,主流机器学习框架受影响的主要内容,如果未能解决你的问题,请参考以下文章 研究人员发现HTTP/2 新型计时侧信道攻击方式;Google统计上半年已披露11个在野利用0day 响尾蛇(SideWinder)组织利用WebSocket隧道的新型攻击活动披露