可能是最简单的AI实践之神经网络如何预测未知
Posted 大鹏杂谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可能是最简单的AI实践之神经网络如何预测未知相关的知识,希望对你有一定的参考价值。
上篇我们在人工智能基础概念剖析中介绍了与人工智能相关的机器学习、深度学习、神经网络等概念,而我个人对神经网络是否能练出金丹还是保持乐观态度,本文我将结合个人学习总结,阐述下人工智能为何可以练出金丹,预测未知。
如何将大象装进冰箱
首先引用一个经典的思维模式来博各位一乐,本山大叔曾经在春晚演过一个小品,宋丹丹扮演的钟点工给本山大叔讲了一个笑话,怎么把大象装进冰箱里?正当本山大叔犹豫时,宋丹丹笑答分三步,第一步,把冰箱门打开。第二步,把大象装进去,第三步,把冰箱门关上 。欧了……
你可能会对这种思维逻辑感到有点搞笑,但是往往这就是最直接有效的方式,因为只要完成了这三步,就说明任务完成了,步骤划分也完全符合操作逻辑,而且这个步骤划分是不受“大象和冰箱的实际体积”所影响的(通用模型)。而且无论是装猛犸象、非洲象、亚洲象还是使用海尔、西门子、美的、容声、三星哪个牌子的冰箱,我都能按这个步骤来实施(穷尽所有可能)。
其实神经网络的训练过程也是如此。参考大象如何装进冰箱的例子,可以帮助我们更好的理解神经网络的分层概念,我们也可以将神经网络如何闭环这个话题拆分成三步
第一步:准备好可以被输入的特征向量数据
第二步:使用特征向量数据不断训练和调优识别模型
第三步:输出判断预测结果
神经网络数据输入转换
像所有传统计算机程序一样,我们首先需要弄懂的第一步就是如何将数据输入到神经网络中。参照现在图像识别市场如火如荼,我们拿图片识别的例子解释下如何将一张猫咪图片输入到神经网络中。
显然计算机是不能直接读取猫咪图片的,但是按照图像的原理,我们可以将图片进行拆解变成很多像素点,每个像素点的颜色又可以通过RGB(红色、绿色和蓝色)合成(比如RGB为255,255,255,那么这个颜色点就是白色),因此一张图片可以拆解为R、G、B三张不同颜色的底图,每张底图实际上都是一个二维矩阵数组,假设这个猫咪图片大小是5 * 4个像素,那么图片转换后数据就应该是3个5 * 4的矩阵。为了简化计算,通常大家又会把这3个5 * 4的矩阵转化成1个向量,那么这个向量X的总维数就是5 * 4 * 3 = 60。
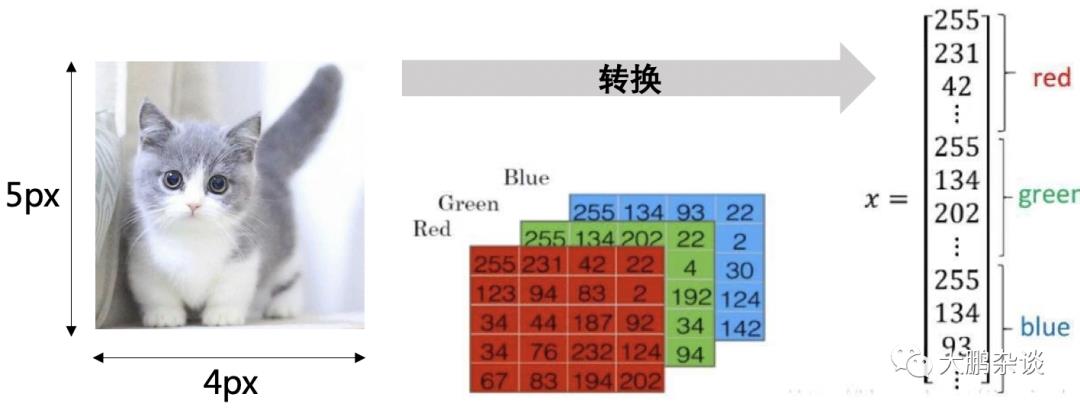
神经网络预测处理逻辑
在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征,那么上面的这张图像中就有60个特征,也被称为60个特征向量。神经网络接收这些个特征向量X作为输入,并在隐藏层进行分解和预测,那么隐藏层如何知道这张图片是不是猫咪呢?这就涉及到一个解决分类问题的公式(逻辑回归):
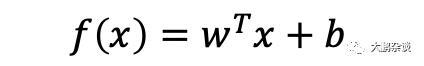
为了理解更加简单,我们去掉实际运算中需要w的转置矩阵可以得到:
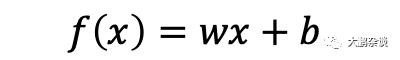
由于识别猫的需要的特征向量较多也较为复杂,因此我们拿日常运维中大家比较关注的基础设施指标出现故障是否会影响业务指标来举例:
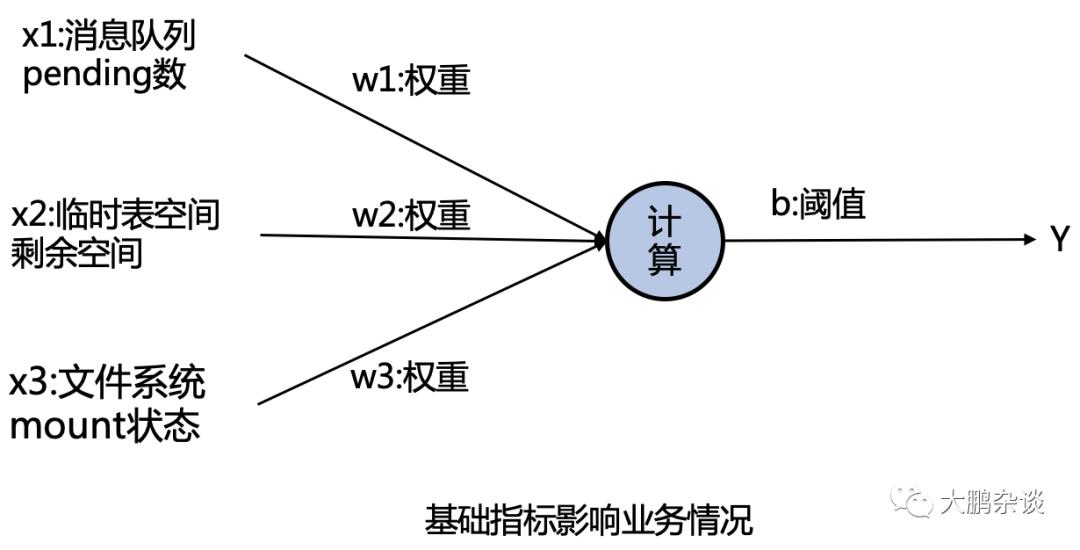
假设某个应用系统同时有三个指标发生异常告警,分别是x1:消息队列pending数、x2:临时表空间剩余空间、x3:文件系统mount状态,我们假设这个三个告警的特征向量(x1,x2,x3)分别为(1,1,0)
我们假设这个三个指标告警(x1,x2,x3)对交易响应时间的权重(w1,w2,w3)分别为(80%,60%,40%),实际上权重值需要神经网络自己学习得到
对于计算后的结果我们再假设一个结果的准确性的阈值b为0(实际上b值需要学习得到),按照公式我们可以得到Y = (x1 * w1 + x2 * w2 + x3 * w3) + b = (1 * 0.8 + 1 * 0.6 + 0 * 0.5) + (0) = 1.4
由于我们通过求导的线性函数模型值域是(-∞,∞),而概率是属于[0,1]区间,因此为了便于我们理解,需要找到一个值域刚好在[0,1]区间,同时要足够好用的模型。大家普遍选择的是sigmoid函数它的表达式和曲线为: 
通过将结果Y代入到sigmoid函数中,最终我们可以得到0.8的影响概率,从上图可以看出,Y越大那么结果值就越靠近1,也就代表指标对业务的影响可能性越大。
同理识别图片中是否包含猫的过程也是如此,只需要查看最终的代入的结果值即可知道概率。那80%的概率是不是就代表神经网络预测的结果就是正确答案呢?未必…..
神经网络预测模型调优
不同的对象和物体由于其特征维度、差异较小,因此哪怕有80%的概率也不代表其准确性很高,比如说与猫外观很像的兔狲很可能经过神经网络计算得出的概率就超过80%,但是它还不是猫。
因此,我们必须要让神经网络在模型训练时,知道自己预测的结果是否准确,只有这样不断调优模型参数,才能让预测结果越来越准确,这就是神经网络学习的过程。而要验证每个样本的学习成果,判断预测结果是否准确,就需要使用到损失函数(loss function )来解决。
根据上述公式,将单个样本的预测值Y和真实值y经过损失函数运算后,如果两者结果偏离越大,那么就意味预测精度越差。如果要算整个训练集的预测精度,就需要对每个样本的“损失”进行累加,然后求平均值。这种针对于整个训练集的损失函数称为成本函数(cost function )。同样它的计算结果越大,就说明成本越大,预测越不准确。
通往成功预测之路
如同我们自己学习不同学科一样会面对不同的规则、模式,神经网络面对不同的场景,需要识别的对象不同,因此输入计算机时表达形式也各不相同,但最终我们会将其转化成一个特征向量,再将其输入到神经网络中。然后再通过对特征向量进行训练权重值后得到一个模型,并且不断调优模型预测结果的准确性。最后当输入一个样本库之外的对象,即可得到一个尽可能准确的概率结果。
从上文的处理逻辑我们不难看出,人工智能并不是一门炼丹的玄学,而是统计和概率结合的学科,在初期模型尚未训练成熟之前,难免会出现误判错判,也是无可厚非,这也是人工智能类项目需要提升的地方。
虽然我们知道了神经网络似乎可以实现一些预测判断,但是从上文例子中不难发现有两个关键参数:权重w和阈值b,它们的值应该是多少预测才会准确呢?我们下篇接着聊...
以上是关于可能是最简单的AI实践之神经网络如何预测未知的主要内容,如果未能解决你的问题,请参考以下文章