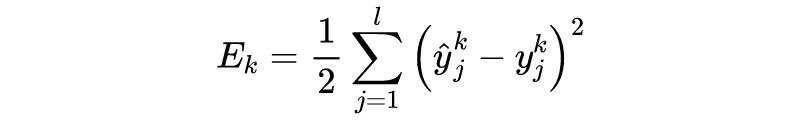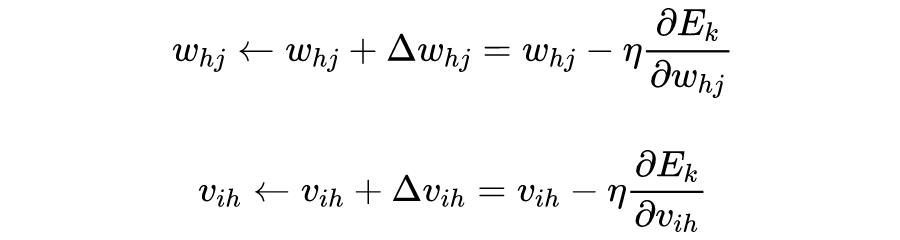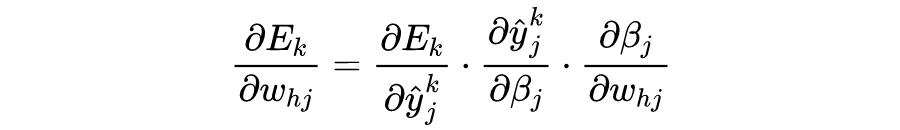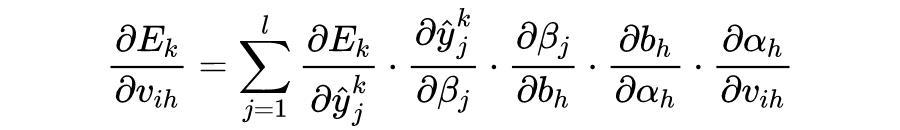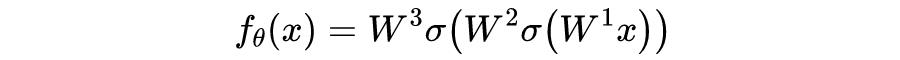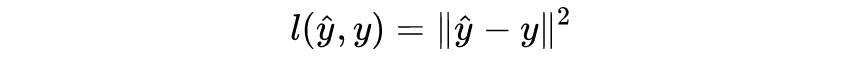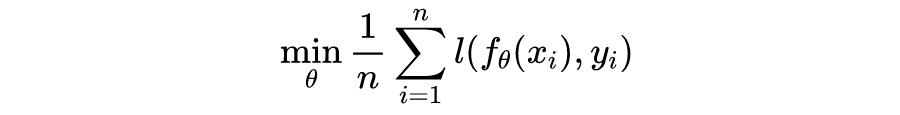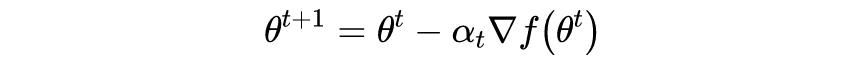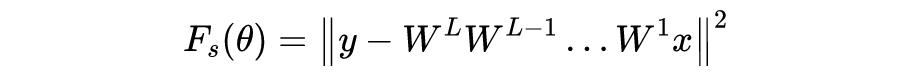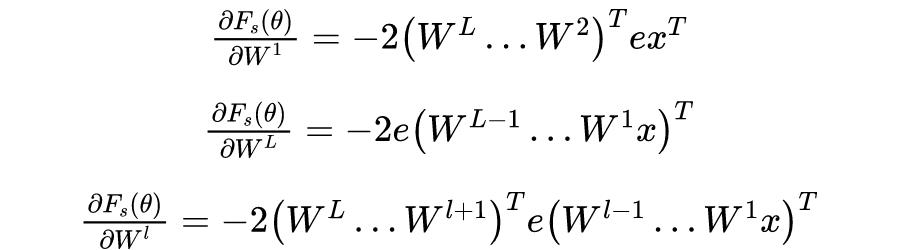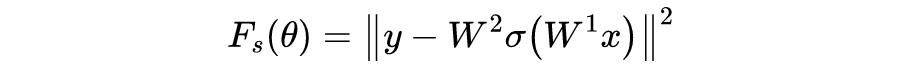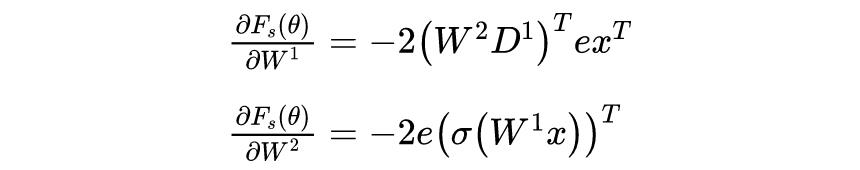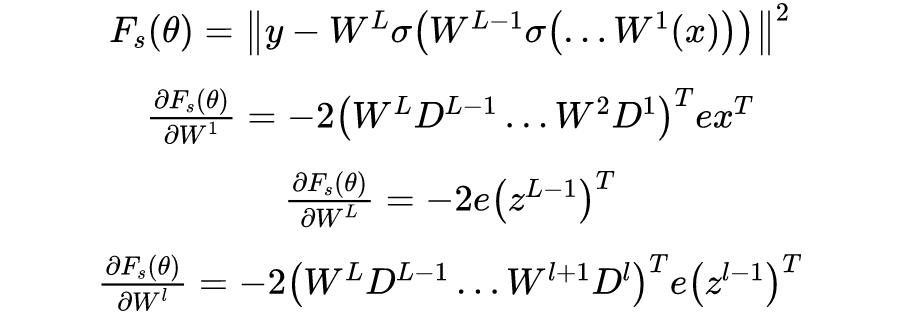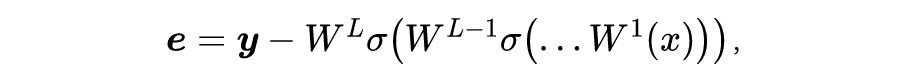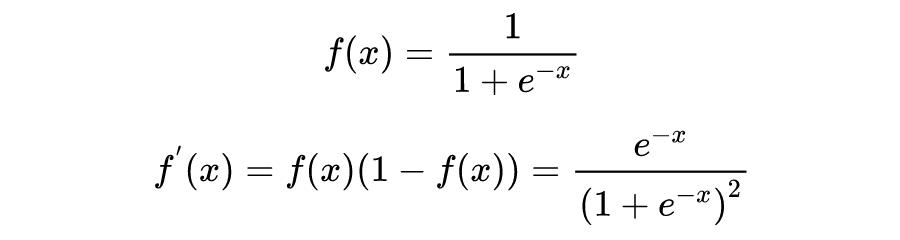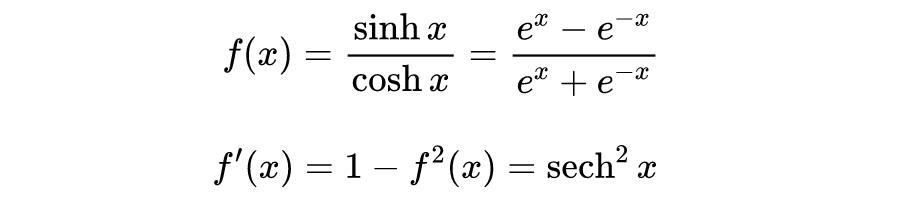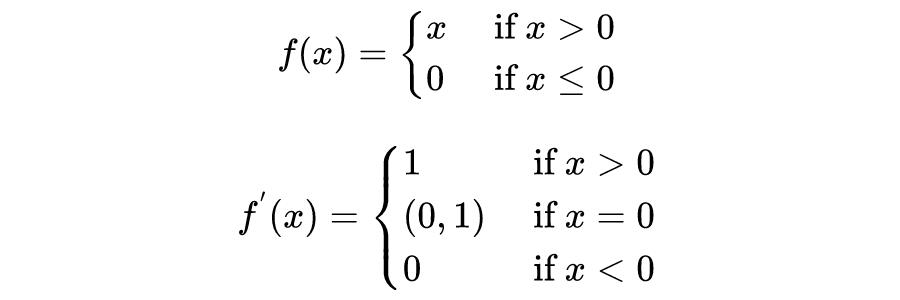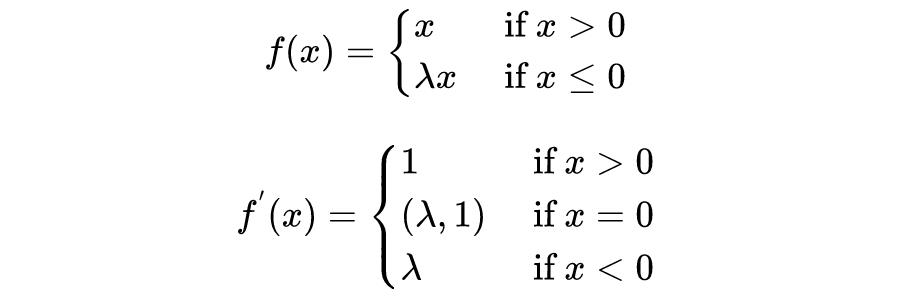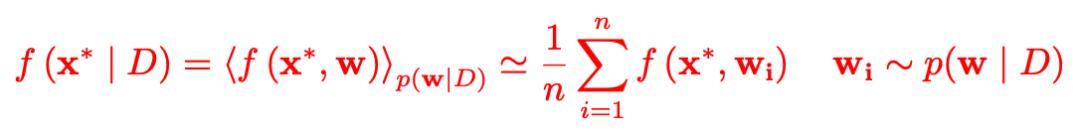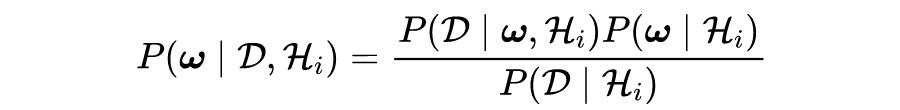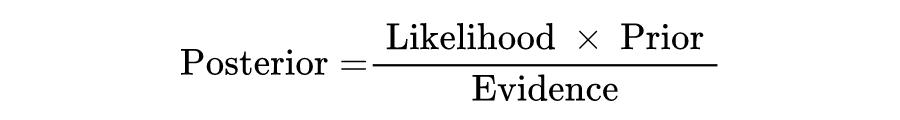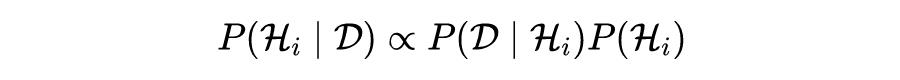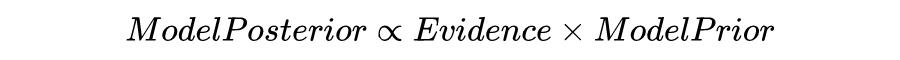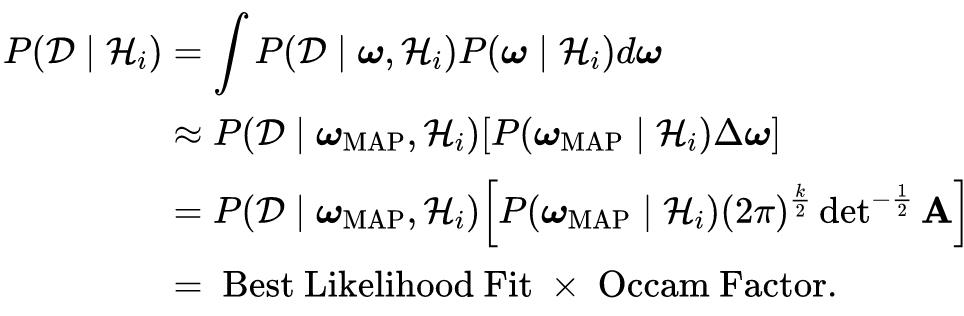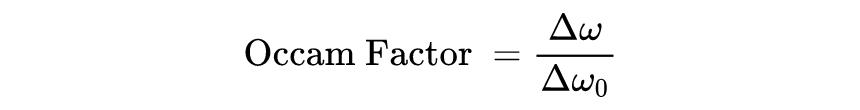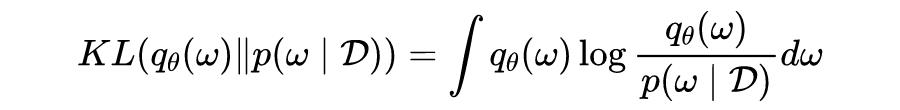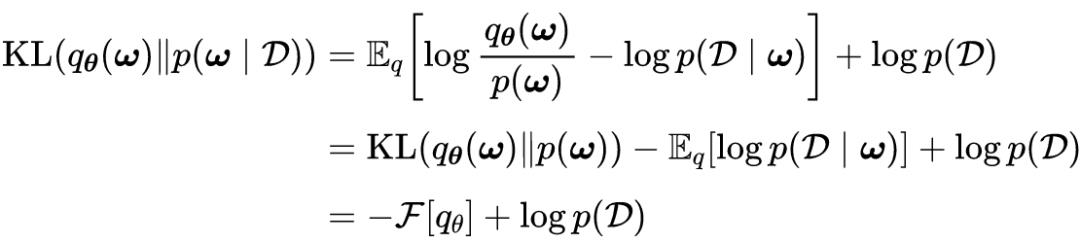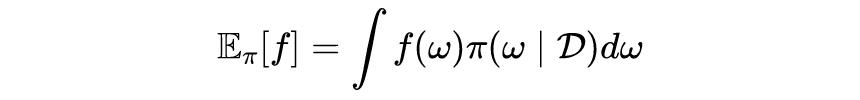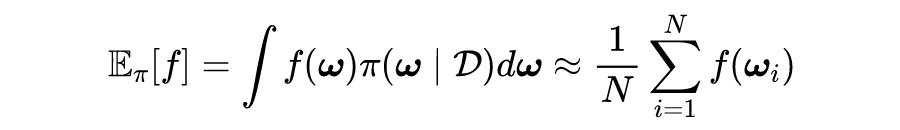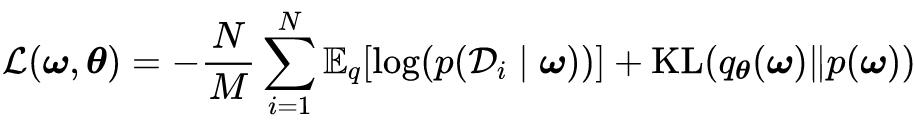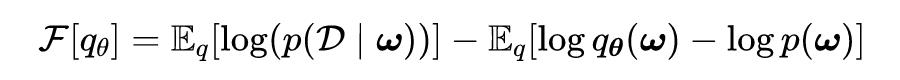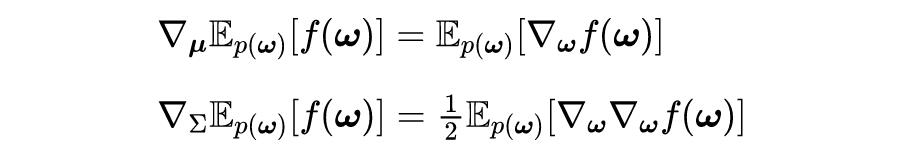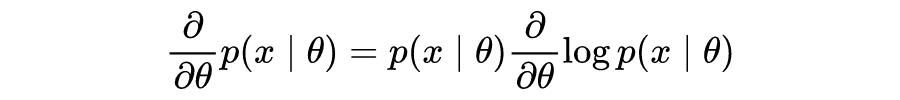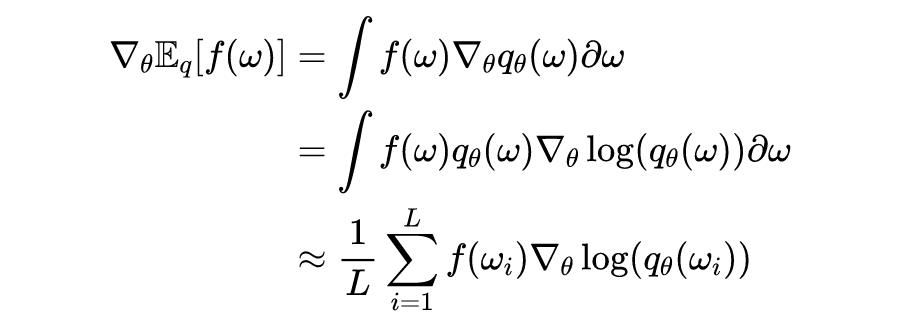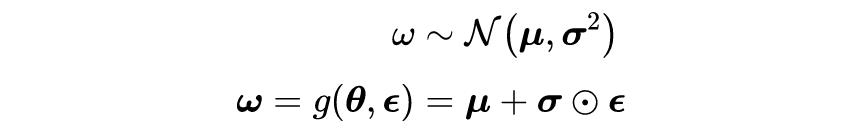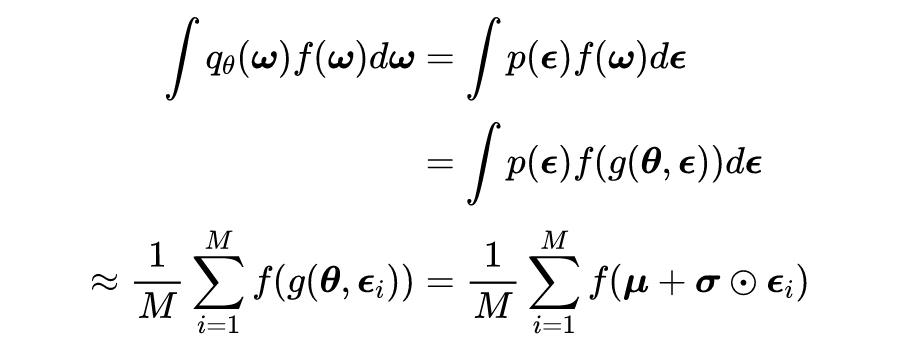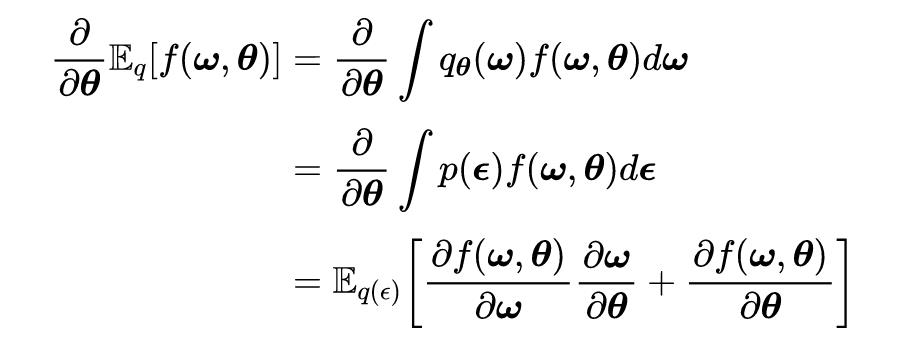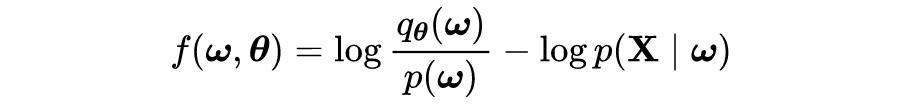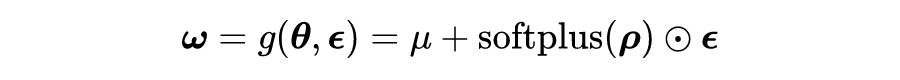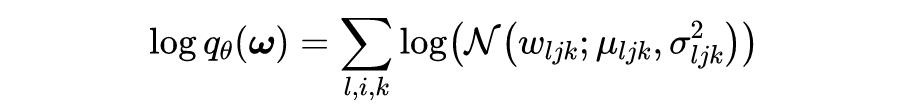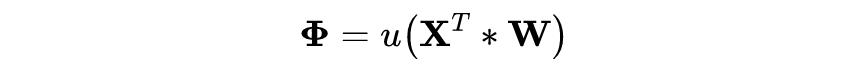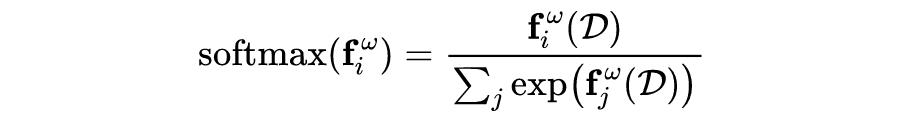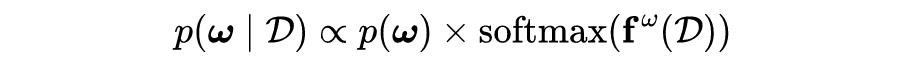©PaperWeekly 原创 · 作者|尹娟
学校|北京理工大学博士生
研究方向|随机过程、复杂网络
论文标题: Bayesian Neural Networks: An Introduction and Survey
论文链接: https://arxiv.org/abs/2006.12024
引言
下一代神经网络的演化方向是什么?最近两年在北京举行的智源大会都谈到了这个问题,可能性的一个答案是贝叶斯神经网络,因为它可以对已有的知识进行推断。逻辑推理作用就是可以对已有的知识进行延伸扩展。
举个例子,如果询问训练完善的 AI 模型的一个问题,“在乌克兰,新西兰,新加坡,阿尔及利亚这四个国家里,哪一个国家位于中国的最西边”,这个问题的难点就在于那个“最”字,如果是传统的 AI 模型可能会蒙圈,因为乌克兰和阿尔及利亚都是在中国的西边,因为现有的训练的知识并不足以告诉它哪个是最西边,经过 BNN(贝叶斯神经网络)训练的模型可能会从经纬度,气温等其他信息进行推断得出一个阿尔及利亚在中国的最西边这个答案。
BNN 的最新进展值得每个 AI 研究者紧密关注,本文就是一篇新鲜出炉的关于 BNN 的综述,为了方便读者的阅读,我按照自己的节奏和想法重新梳理了一下这篇文章。
神经网络
先回顾一下传统神经网络,论文限于篇幅的原因有一些重要的细节没有展开,而且我一直觉得神经网络中一个完善的形式应该是通过矩阵的形式表现出来,同理矩阵形式 BP 反向传播原理也能一目了然。
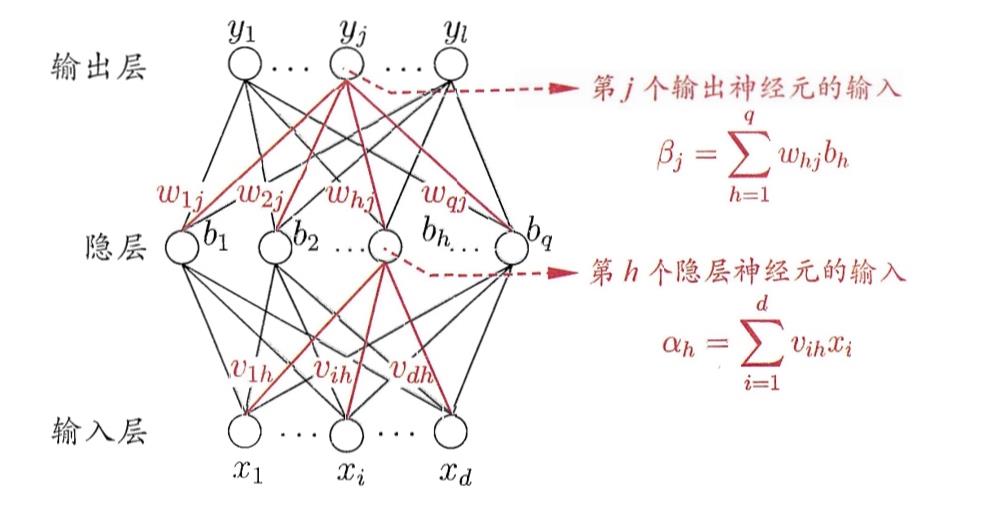
下图为标量形式的神经网络,并且为了说明方便不考虑偏置项。
根据梯度下降法更新模型的参数,则各个参数的更新公式为:
可以发现标量视角下的神经网络更新参数求解梯度会给人一种很混乱的感觉。
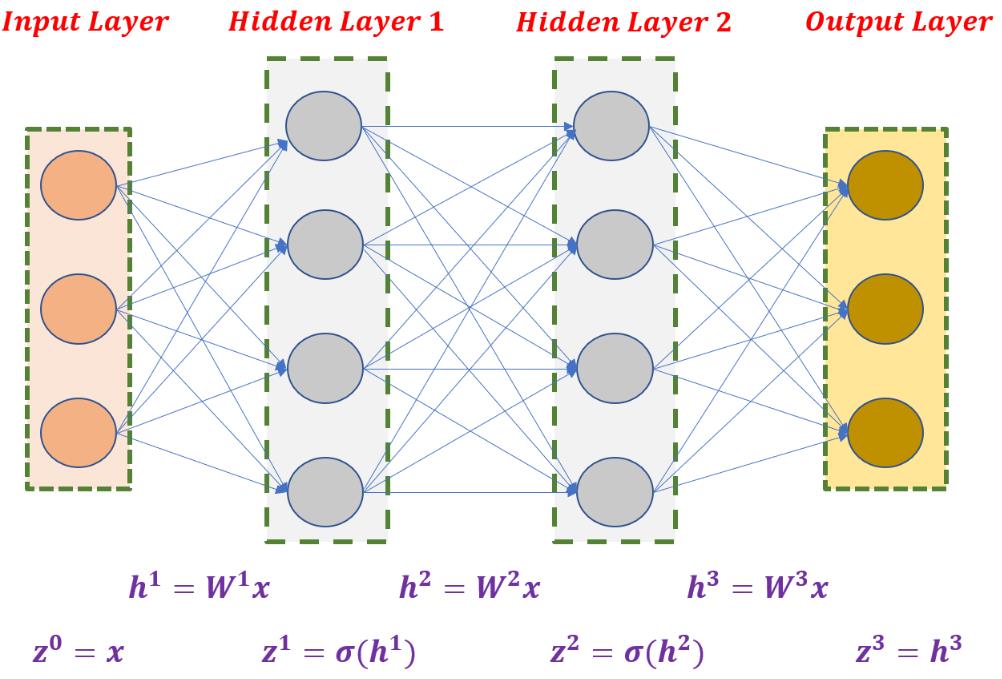
2.2 矩阵形式的神经网络
下图为 3 层不考虑偏置项的全连接神经网络示意图:
上图可以描述为如下公式:
损失函数如下所示:
优化的目标函数为:
采用随机梯度下降法求解优化深度神经网络的问题,如下式所示:
上式中,主要的问题是在于计算
,通常采用的方法是链式法则求导。而反向传播就是一种很特殊的链式法则的方法。反向传播非常有效的避免大量的重复性的计算。
2.2.2 无激活函数的神经网络
2.2.3 含有激活函数的神经网络
首先,考虑 2 层的有激活函数的神经网络,目标函数定义为:
其中,
,
,
是
导数。再考虑 L 层有激活函数的神经网络,目标函数定义为:
其中,
我们可以发现矩阵形式的求解参数梯度感官上更加的简便明了(公式推导会让人头大,不过推导过程是严格的)。
2.3 激活函数
神经网络中激活函数的作用是用来加入非线性因素以此来提高模型的表达能力,因为没有激活函数神经网络训练出来的模型是一种线性模型,这样对于回归和分类任务来说其表达能力不够。
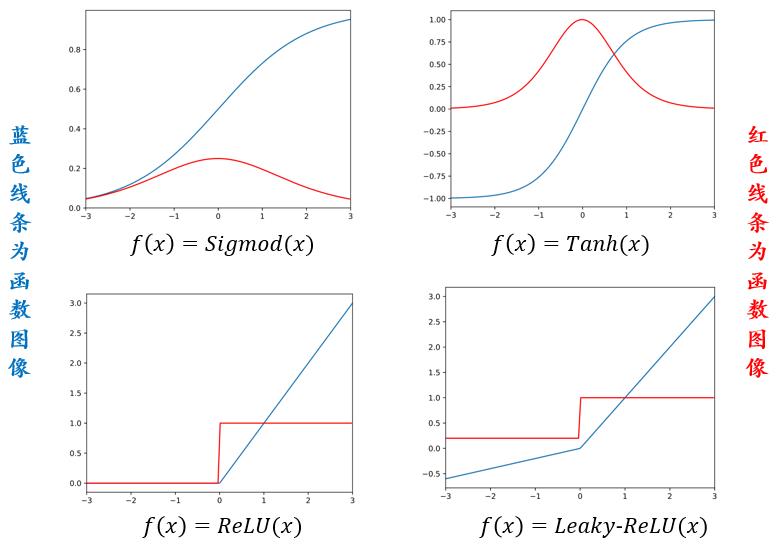
下图为神经网络中常用的激活函数示例,其中蓝色线条为激活函数图像,红色线条为激活函数的导数图像。这些函数分别是 Sigmoid(x),Tanh(x),ReLU(x),Leaky-ReLU(x)。
Sigmod 函数定义域为
,值域为
,过(0,1)点,单调递增,其函数和导数形式分别为:
Tanh 函数是一种双曲正切函数,定义域为 R,值域为
,函数图像为过原点严格单调递增,其函数和导数形式分别为:
ReLU 函数又称线性整流函数其,定义域为 R,值域为
,其函数和导数形式为:
Leak-ReLU 函数是 ReLU 函数的改进版本,定义域为 R,值域为 R,其函数和导数形式为:
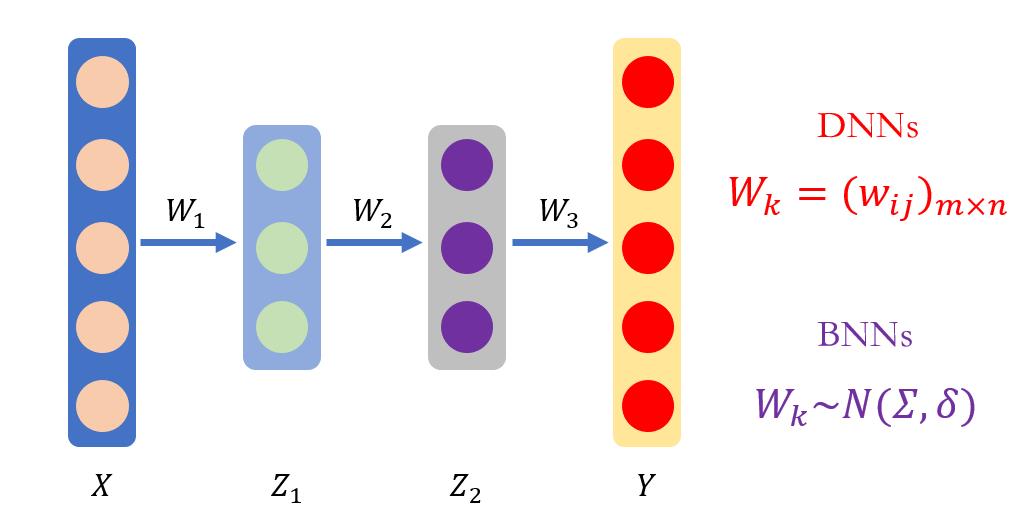
DNN和BNN的区别
BNN 跟 DNN 的不同之处在于,其权重参数是随机变量,而非确定的值,它是通过概率建模和神经网络结合起来,并能够给出预测结果的置信度。其先验用来描述关键参数,并作为神经网络的输入。
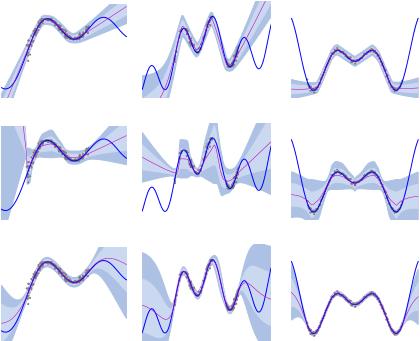
神经网络的输出用来描述特定的概率分布的似然。通过采样或者变分推断来计算后验分布。这对于很多问题来说非常关键,由于 BNN 具有不确定性量化能力,所以具有非常强的鲁棒性。如下图所示为 DNN 和 BNN 的之间的差异:
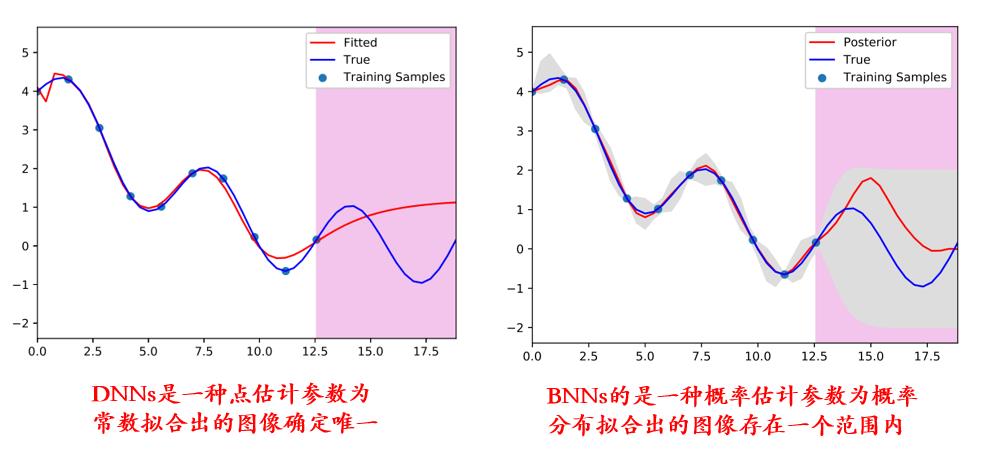
如下图所示贝叶斯神经网络的回归与简单的神经网络方法的回归的进行了比较,并说明了测量不确定度的重要性。
虽然这两种方法在训练数据的范围内都表现良好,在需要外推法的情况下,概率方法提供了函数输出的完整分布,而不是由神经网络提供的点估计。概率方法提供的输出分布允许开发可信的模型,因为它们可以识别预测中的不确定性。
贝叶斯模型可以通过预测器的集合来捕捉数据驱动模型的内在认知下的不确定性;它通过将算法参数(以及相应的预测)转化为随机变量来实现。
在神经网络中,对于具有输入
和网络权重参数
的神经网络
,则从网络权重
的先验度量开始。通过似然
评估权重为
的网络与数据
的拟合度。
贝叶斯推理通过 Bayes 定理将似然和先验相结合,得到权重空间
的后验测度。神经网络的标准训练可以看作是贝叶斯推理的一种近似。
对于 NNs 这样的非线性/非共轭模型来说,精确地获得后验分布是不可能的。后验分布的渐近精确样本可以通过蒙特卡洛模拟来获得,对于一个新输入的样本
贝叶斯预测都是从 n 个神经网络的集合中获得的,每个神经网络的权重都来自于其后验分布
:
论文中这这部分作者没有详细展开说明,不过可以从公式可以推测出来
表示的是已知训练数据集的情况下,贝叶斯神经网络给出的样本
的预测,
表示是不同权重参数的给出预测的期望,然后用蒙特卡洛模拟将期望形式转化成离散的平均加和的形式。
BNN的起源
MacKay 在 1992 年公布的文章《Bayesian interpolation》展示了贝叶斯框架如何自然地处理模型设计和通用统计模型比较的任务。在该工作中,描述了两个层次的推理:拟合模型的推理和评估模型适用性的推理。第一层推理是贝叶斯规则用于模型参数更新的典型应用。如下公式
其中
是一般统计模型中的一组参数,
是训练数据,
是用于这一水平推断的第 i 个模型。然后将其描述为:
这可以解释一种黎曼近似,具有代表证据峰值的最佳似然拟合,并且 Occam 因子是由高斯峰值周围的曲率表征的宽度。其中 Occam 因子的计算公式为:
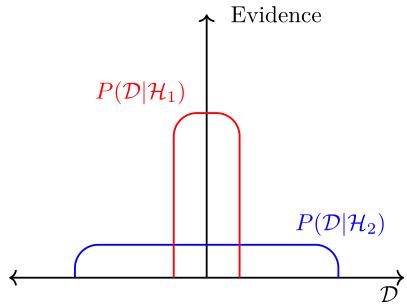
这意味着 Occam 因子是似然参数空间中前后变化的比率。下图以图形方式演示了这个概念。有了这种表示,一个能够表示大范围数据的复杂模型将具有更广泛的证据,从而具有更大的 Occam 因子。
一个简单的模型在捕捉复杂的生成过程方面的能力会较低,但是较小范围的数据将能够以更大的确定性进行建模,从而降低 Occam 因子。这导致了模型复杂性的自然正则化。
一个不必要的复杂模型通常会导致较大的后验概率,从而导致较大的 Occam 因子和较低的证据。类似地,一个广泛或信息量较少的先验将导致 Occam 因子的减少,从而为正则化的贝叶斯设置提供了进一步的直觉。
使用这种证据框架需要计算边际似然,这是贝叶斯建模中最关键的挑战。考虑到接近边际可能性所需的大量的计算成本,比较许多不同的体系结构可能是不可行的。
尽管如此,证据框架的使用可以用来评估 BNN 的解决方案。对于大多数感兴趣的神经网络结构,目标函数是非凸的,具有许多局部极小值。每一个局部极小都可以看作是推理问题的一个可能解。
BNN的早期变分推理
变分推理一种近似推理方法,它将贝叶斯推理过程中所需的边缘化作为一个优化问题。这是通过假设后验分布的形式来实现的,并进行优化以找到最接近真实的后验分布。这种假设简化了计算,并提供了一定程度的可操作性。
假定的后验分布
是参数
集上的一个合适的密度,它仅限于由
参数化的某一类分布。然后调整此变分分布的参数,以减少变分分布与真实后验分布
之间的差异。
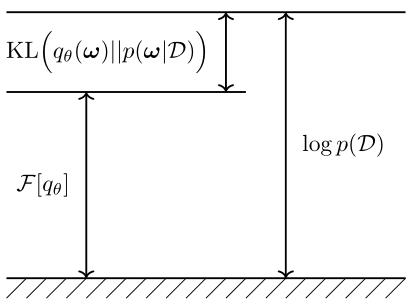
度量变分推理相似性的方法通常是变分分布和真分布之间的正向 KL 散度为:
如图所示说明了如何将近似分布和真实后验之间的关系示意图,由此可知通过近似对数似然逼近近似分布与真实分布之间的 KL 散度。
BNN的蒙特卡洛方法
贝叶斯神经网络的重点是寻找良好的后验分布近似值上,预测值和区间都是作为后验
的期望值来计算的,其中精确的预测依赖于对难以处理的后验概率的精确近似。具体的计算公式如下所示:
上面的积分公式的求解很困难,以前的方法是通过基于优化的方案,但优化方法中设置的限制通常会导致预测值不准确,所以基于优化的方案可以提供不准确的预测量。为了在有限的计算资源下做出准确的预测,通过使用马尔可夫链蒙特卡罗(MCMC)方法来求解上积分。
MCMC 是一种可以从从任意和难以处理的分布中进行采样的通用方法,会有如下公式:
传统的 MCMC 方法表现出一种随机游走行为,即序列是随机产生的。由于 BNNs 后验函数的复杂性和高维性,这种随机游走行为使得这些方法不适合在任何合理的时间内进行推理。为了避免随机行走行为,本文采用混合蒙特卡洛(HMC)方法用于将梯度信息合并到迭代行为中。
对于 BNNs,首先引入超先验分布
来模拟先验参数精度,其中先验参数服从高斯先验。
上的先验服从伽马分布,并且它是条件共轭的,这就使得吉布斯抽样可以用于对超参数进行推理,然后可以使用 HMC 来更新后验参数,最后从联合后验分布
进行取样。
现代BNN模型
考虑到网络的大规模性,强大的推理能力通常需要建立在大数据集上。对于大数据集,完全对数似然的评估在训练目的上变得不可行。为了解决这一问题,作者采用了随机梯度下降(SGD)方法,利用小批量的数据来近似似然项,这样变分目标就变成:
其中
,每个子集的大小为
。这为在训练期间使用大型数据集提供了一种有效的方法。在通过一个子集
后,应用反向传播来更新模型参数。SGD 是使用变分推理方法训练神经网络和贝叶斯神经网络的最常用方法。
Graves 在 2011 年发表了 BNN 研究的一篇重要论文《Practical variational inference for neural networks》。这项工作提出了一个 MFVB 处理使用因子高斯近似后验分布。这项工作的主要贡献是导数的计算。变分推理的目标可以看作是两个期望值的总和如下所示:
Opper 在 2009 年发表的《The variational gaussian approximation revisited Neural computation》中提出了利用高斯梯度特性来对参数进行更新操作,具体的如下所示:
上面两个公式用于近似平均参数和方差参数的梯度,并且该框架允许对 ELBO 进行优化,并且可以推广到任何的对数损失参数模型中。
已知分数函数估计依赖于对数导数性质,具体公式如下所示:
利用这个性质,可以对一个期望的导数形成蒙特卡罗估计,这在变分推理中是经常被使用,具体的推导过程如下所示:
变分推断的第二种梯度估计方法是通过路径导数估计值法。这项工作建立在“重新参数化技巧”的基础上,其中一个随机变量被表示为一个确定性和可微的表达式,具体形式如下所示:
其中
和
表示的是哈达玛积(Hadamard product)。使用这种方法可以有效地对期望值进行蒙特卡罗估计,具体的计算公式如下所示:
由于上式是可微的,所以可以使用梯度下降法来优化这种期望近似。这是变分推断中的一个重要属性,因为变分推断的目标的对数似然的期望值的求解困难很大。与分数函数估计量相比,路径估计值法更有利于降低方差。
Blundell 等人在论文《Bayes by Backprop》中提出了一种在 BNNs 中进行近似推理的方法。该方法利用重参数化技巧来说明如何找到期望导数的无偏估计。其期望导数的具体形式如下所示:
其中
可以看作是期望值的自变量,它是下界的一部分。
假设全因子高斯后验函数
,其中
用于确保标准差参数为正。由此,将网络中的权重
的分布重新参数化为:
在该 BNN 中,可训练参数为
和
。由于采用全因子分布,则近似后验概率的对数可以表示为:
综合上面提到的贝叶斯的反向传播算法的细节,会有如下完整的算法流程图。
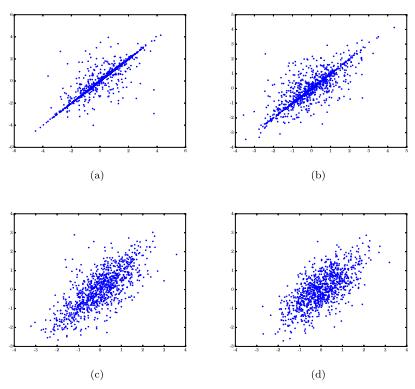
下图为当在参数上放置高斯先验时,随着网络规模的增加,先验在输出上诱导的图示。其中图中的每个点对应于一个网络的输出,参数从先验分布中进行采样。对于每个网络,隐藏单元的数量是图(a)对应着 1 个单元,图(b)对应着 3 个单元,图(c)对应着 10 个单元,图(d)对应着 100 个单元。
由此可知在中心极限定理下,随着隐层数 N 逐渐增大,输出服从高斯分布。由于输出被描述为基函数的无穷和,因此可以将输出看作高斯过程。高斯过程和具有单个隐藏层工作的无限宽网络之间的关系最近已扩展到深度神经网络的当中,这一联系的识别激发了 BNNs 的许多研究工作。
高斯过程提供了可靠的不确定性估计、可解释性和鲁棒性。但是高斯过程提供这些好处的代价是预测性能和随着数据集大小的增加所需的大量计算资源。高斯过程和 BNNs 之间的这种联系促使了两种建模方案的合并;既能维持神经网络的预测性能和灵活性,同时结合了高斯过程的的鲁棒性和概率性。
最近的研究已经确定了高斯过程属性不限于 MLP-BNN,而且在卷积中也可以应用该属性。因为 CNN 可以实现为 MLP,其结构在权重中被强制执行。Vander Wilk 等人在 2003 年发表的论文《Convolutional gaussian processes》中提出了卷积高斯过程,它实现了一种类似于 CNN 中的基于 patch 的操作来定义 GP 先验函数。
如下图所示,分析显示了高斯过程在预测偏差和方差方面的对比性能。用 Backprop 和一个因式高斯近似后验概率对 Bayes 模型进行训练,在训练数据分布的情况下,虽然训练数据区域外的方差与高斯过程相比显著低估,但预测结果是合理的。具有标度伯努利近似后验的 MC-Dropout 通常表现出更大的方差,尽管在训练数据的分布中保持不必要的高方差。
卷积BNN
虽然 MLP 是神经网络的基础,但最突出的神经网络架构是卷积神经网络。这些网络在具有挑战性的图像分类任务方面表现出色,其预测性能远远超过先前基于核或特征工程的方法。CNN 不同于典型的 MLP,它的应用是一个卷积型的算子,单个卷积层的输出可以表示为:
其中
是非线性激活,
表示类似卷积的运算。这里输入 X 和权重矩阵 W 不再局限于向量或矩阵,而是可以是多维数组。可以得到证明的是 cnn 可以编写成具有等效 MLP 模型,允许使用优化的线性代数包进行反向传播训练。
在现有研究方法的基础上,发展了一种新型的贝叶斯卷积神经网络(BCNN)。假设卷积层中的每个权重是独立的,允许对每个单独的参数进行因子分解,其中 BCNN 输出概率向量由 Softmax 函数表示:
作者做了相关的对比实验,BCNN 使用了流行的 LeNet 架构,并利用 BCNN 的平均输出进行分类,并使用可信区间来评估模型的不确定性。
在 MNIST 数据集中的 10000 个测试图像上,两个网络的总体预测性能显示出了比较好的性能。BCNN 的测试预测精度为 98.99%,香草网络的预测精度略有提高,预测精度为 99.92%。
虽然竞争性的预测性能是必不可少的,但 BCNN 的主要优点是可以提供有关预测不确定性的有价值的信息。从这些例子中,可以看到这些具有挑战性的图像存在大量的预测不确定性,这些不确定性可以用于在实际场景中做出更明智的决策。