神经网络的反向传播算法—ML Note 52
Posted 讲编程的高老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络的反向传播算法—ML Note 52相关的知识,希望对你有一定的参考价值。
本文是吴恩达《机器学习》视频笔记第52篇,对应第5周第2个视频。
“Neural Networks: Learning——Backpropagation algorithm”
01
—
笔记
上一小节讲了神经网络的代价函数,这一小节讲解一个让代价函数最小化的算法:反向传播算法。
算法目标
找到合适的参数,让代价函数最小。那我们要怎么做呢?
我们需要有一种能够用编码实现的算法,梯度下降也好、其它更高级的算法也好,我们需要能够通过一种迭代的办法不停改变这些参数\theta的值,使得代价函数最小。而参数每次改变的大小,需要计算偏导数,通过偏导数的值来确定每一步参数改变的大小和正负。
也就是说,我们把代价函数的值作为了函数的因变量,把参数作为自变量来进行求函数最小值。
前向传播
假设我们有一组训练样本(x,y),神经网络如何计算得出输出结果的呢?如下图,它是从最左边的输入层一层一层的算到输出层,然后给出一组结果的。
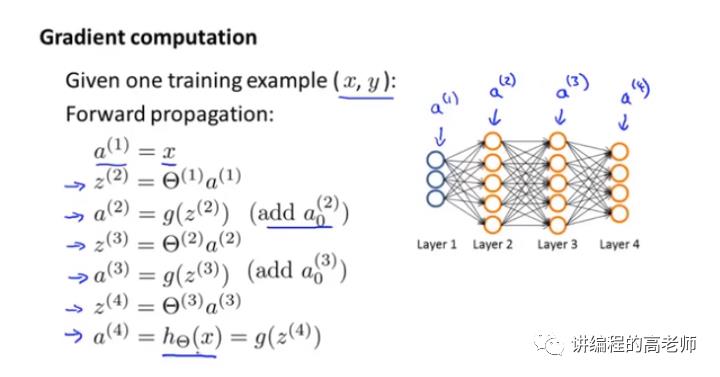
这样的运算过程,我们叫做前向传播。
前向传播的含义,就是从输入层向前逐层向前运算最后得到输出。
反向传播
反向传播,直观上我们是想要算出“真实值和神经网络的计算值之间的差”。

我们从神经网络的外面当然是只能看到输出层上,实际值和计算值之间的差值。但是,我们也知道最后输出上计算值和实际值之间的差值,是由前面从输入层到每个隐藏层慢慢地把这个误差给积累下来的。那我们该怎么算每一层上的误差呢?
我们先从输出层上开始做,将输出层上的每个神经元的计算结果和这个分量上训练样本实际的结果之间求差值。这就是输出层上的误差:

有了输出层的误差,倒数第二层的误差该怎么计算呢?本质上,输出层的误差是由上一层的误差经过输出层上的运算之后得到的,那我们再经过一次逆反运算就可以算出来了。
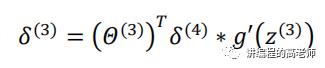
上式中,后面的一项是激活函数的导数。
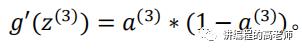
前面一项,是权重导致的误差的和。
类似的,可以把第二层的也给算出来。这样,我们就有了每一层上的误差函数:
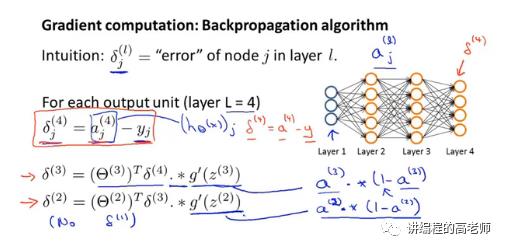
因为最左边的是输入层,没有误差,所以这里有3层的误差函数。
通过上面的计算过程,我们就知道这个算法为什么叫做反向传播算法了。
有一大堆的训练样本的时候,我们该怎么做?
假设有m组训练样本,反向传播算法的步骤如下图:

其实,上图中迭代更新的式子中,我们把当前样本的输入作为常量,把权值作为自变量来求偏导的,这样就和前面学习过的梯度下降类似了。
我们学了那么久,这一小节是第一次真正的挑战,因为在反向传播那个地方,这里跳过了很多的中间过程。不明白的同学,可以找一些BP网络原理的资料来看看。
以上是关于神经网络的反向传播算法—ML Note 52的主要内容,如果未能解决你的问题,请参考以下文章