EMNLP2020论文 利用图神经网络和文本事实结构的机器生成文本检测 (Deepfake Detection)
Posted 智能优化与学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EMNLP2020论文 利用图神经网络和文本事实结构的机器生成文本检测 (Deepfake Detection)相关的知识,希望对你有一定的参考价值。
欢迎关注智能优化与学习实验室
导读
本文介绍实验室与微软亚洲研究院联合培养博士生钟宛君同学在EMNLP 2020上发表的论文:Neural deepfake detection with factual structure of text, The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online, November 16-20, 2020.
Deepfake检测是旨在自动识别机器生成文本的任务。随着自然语言生成模型的快速发展,判别一篇文章是人写的还是机器生成的变得愈发重要。现存的deepfake检测方法基本上用粗粒度的表示去编码文章,无法建模文章中蕴含的事实结构。根据我们的数据分析,文章中的事实结构是区分人写的文章和机器生成文章的重要判别性因素,因此我们提出了一个基于图的模型去建模文章中的事实结构。给定一篇文章,我们用一个实体图去表示它的事实结构,然后使用图神经网络去计算句子的表示。进一步,我们建模了句子之间的连续性,把句子表示组合成文章级别的表示去做最终的预测。整个算法的框架如图1所示:
图1. 算法框架:给定一篇文章,我们使用RoBERTa去计算文章中词的上下文表示,并且用图去表示文章的事实结构。然后,我们用图神经网络去计算句子的表示。最后,我们建模了连续句子之间的关联性,把句子表示组合成文档表示,并做最终的预测。
我们的方法在两个公开数据集上都显著超越了基准模型RoBERTa。图2给出了一个样例分析,表明我们的模型可以区分出人写的文章和机器生成的文章在事实结构上的差异性。
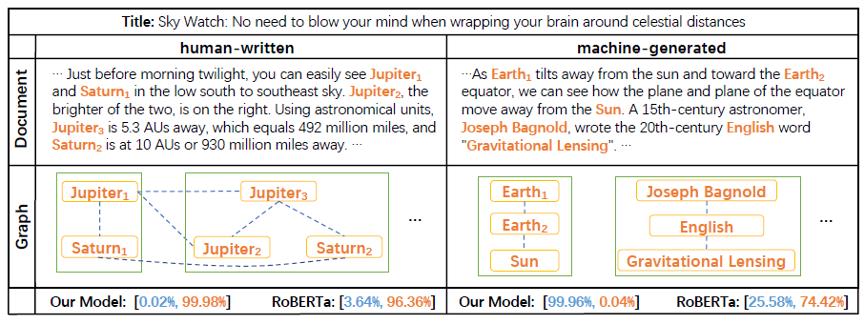
图2. 方法样例分析:连续的单词(橙色)代表抽取出来的一个实体。每个绿色方框代表对应于一个句子的子图。蓝色虚线代表语义相关的实体对之间的边。橙色和蓝色的数字分别代表判别为人写的文章和机器生成文章的概率。
撰稿:钟宛君
发布:梁智威
以上是关于EMNLP2020论文 利用图神经网络和文本事实结构的机器生成文本检测 (Deepfake Detection)的主要内容,如果未能解决你的问题,请参考以下文章