牛津大学博士后试图撬开深度神经网络黑箱,发长篇论文解析
Posted DeepTech深科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了牛津大学博士后试图撬开深度神经网络黑箱,发长篇论文解析相关的知识,希望对你有一定的参考价值。
无疑,深度神经网络(DNN)在计算机视觉、自然语言处理和语音识别等各个领域的应用都取得了成功。
然而,DNN 模型的决策过程却通常无法很好地呈现给使用者,即可解释性较差,是个黑箱。
这一点在医疗、金融或法律等领域显得尤为重要,有的时候为了弄清楚模型得出每一步结论的原因,开发者甚至不得不使用更简单的模型(线性模型或决策树)。
近期,牛津大学博士后研究员瓦娜(Oana-Maria Camburu),发表了一篇名为 “Explaining Deep Neural Networks” 的预印本论文,使用一百多页的篇幅对这个话题展开了详细研究。
论文中,瓦娜研究了解释深度神经网络的两个主要方向。
第一种方法,“事后”解释。
一般适合于解释已经训练和固定后的模型,该方法让模型在给出结果的同时,同时罗列影响决策的关键特征信息,如词组(Token)、超像素(Superpixels)。

图 | 两个解释器分别给出至少两个基于特征的解释示例,这也说明了其 “忠实解释” 的不唯一性。
第二种方法,自解释(内置解释模型)。即将能使用自然语言输出解释内容的神经网络模型内置到需要解释模型中。
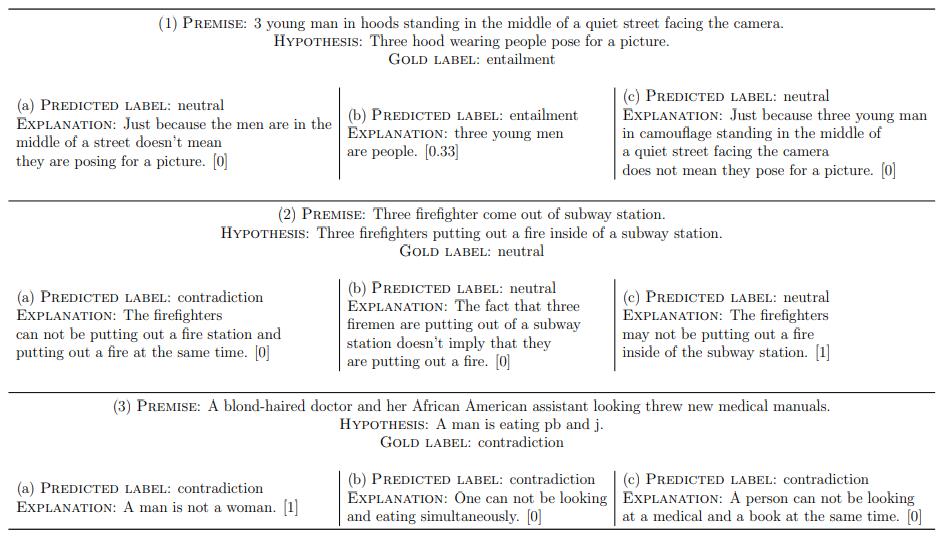
图 | a:BiLSTMMax-PredExpl;b:BiLSTM-Max-ExplPred-Seq2Seq;c:BiLSTMMax-ExplPred-Att 的预测标签和生成解释的例子,方括号中为正确性评分。
瓦娜在论文中深入剖析了这两个方向,并分别给出了各自的优劣势。
首先,作者阐述了仅使用输入特征解释模型的局限性,即便是非常简单的模型也是如此。
大多数的情况,对于同一种结果的 “忠实解释” 并非只有一种。例如,一个人愉悦的原因有很多,而当仅仅凭愉悦的结果和输入的词组去 “推测” 时,这样的解释往往离题甚远,可能会导致严重的判断失误。
瓦娜展示了两种有影响力的解释器,Shapley 解释器和最小子集(minimal sufficient subsets)解释器,它们分别擅长解释不同类型的模型。但在论文中,它们的表现都不够完美,某些情况下,它们都不足以提供决策的完整视图。
其次,作者介绍了一个用于自动验证 “事后” 解释真实性的框架。
该框架依赖特定类型的模型,它有望提供其决策过程的全部细节。作者分析了这种方法的潜在局限性,并介绍了缓解这些局限性的方法。
瓦娜引入的验证框架是通用的,可以在不同的任务和域上实例化,以提供现成的健全性测试(sanity test)。
最后,关于生成自解释神经模型的方向(模型为结果提供自然语言解释),作者在斯坦福自然语言推理(SNLI)数据集的基础之上,收集了约 570K 的人类书面自然语言组成了解释的大型数据集——e-SNLI。

图 | e-SNLI 数据集的示例。注释中提供了前提、假设和标签,强调了对标签高权重词语,并提供了解释。
作者进行了一系列实验,研究了 DNN 模型在测试时生成正确的自然语言解释的能力,以及在训练时提供自然语言解释的好处。
她证明了当前的自解释模型为预测生成自然语言解释时,可能会产生不一致的解释,例如 “图像中有一条狗” 和“ 图像中没有狗”。不一致的解释表明,要么解释没有如实地描述模型的决策过程,要么是模型学习了有缺陷的决策过程。
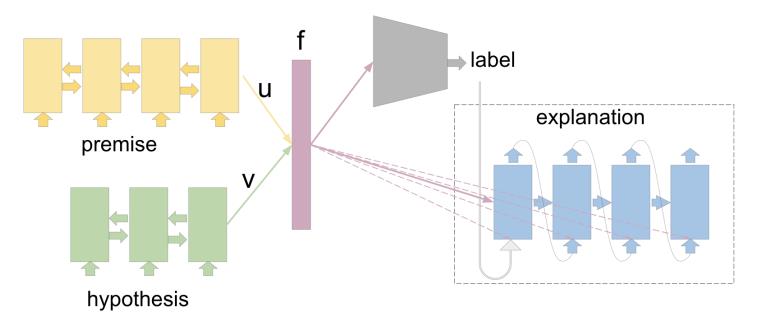
图 | 自解释模型 BiLSTM-Max-PredExpl 架构图
-End-
参考:
https://arxiv.org/abs/2010.01496
以上是关于牛津大学博士后试图撬开深度神经网络黑箱,发长篇论文解析的主要内容,如果未能解决你的问题,请参考以下文章