标准循环神经网络记忆差怎么破
Posted 人工智能与大数据生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了标准循环神经网络记忆差怎么破相关的知识,希望对你有一定的参考价值。
前面介绍的是循环神经网络, 这篇文章介绍的是长短记忆网络。
转换矩阵必然削弱信号
需要一种可以在多个步骤中保持一些维度不变的结构
这个算是循环神经网络的一个升级,解决了循环神经网络致命的问题,梯度消失问题,对长距离会记不住信息。如何解决这两个问题,往下看。
通过内部更新机制,引入了三个门,通过这些门,怎么记住信息?默认情况下LSTM会记住最后一步的信息。
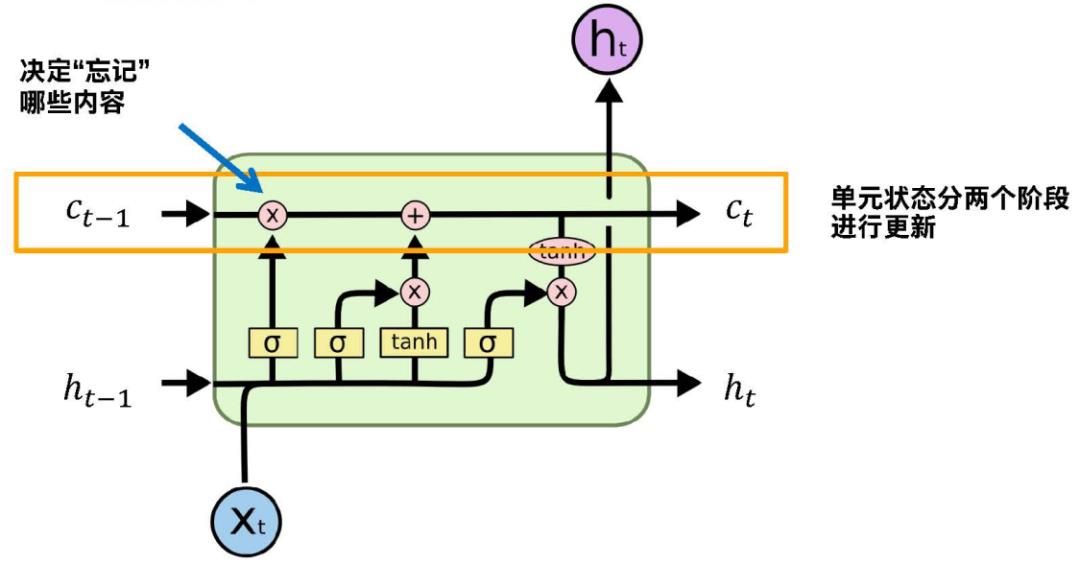
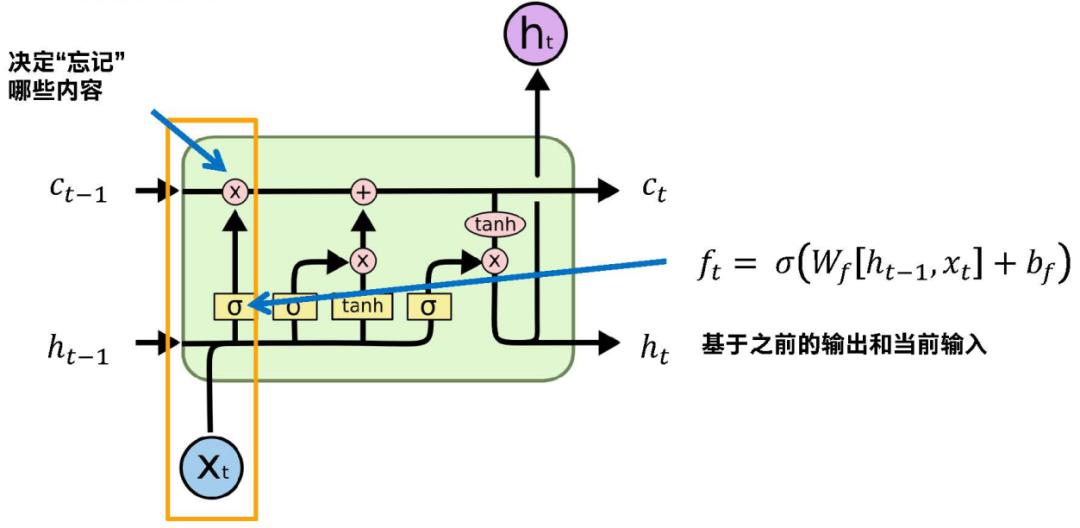
这个其实是小的单元,Xt第t时刻元素输入,前面有两个输入。这个和经典的循环神经网络不一样的是它有两个输入,两个输出。这里我们看到的都是状态,没有把每个节点的输出给出来,C和h都是当前状态的输出状态,或者输入上一层的状态。
这个是长短记忆网络最核心部分,也叫记忆单元、状态单元,因为有了它就解决了记忆问题,也解决了消失问题。它就贯通神经网络节点,它的信息会没有阻断向前传播,更新也不会有任何消失。
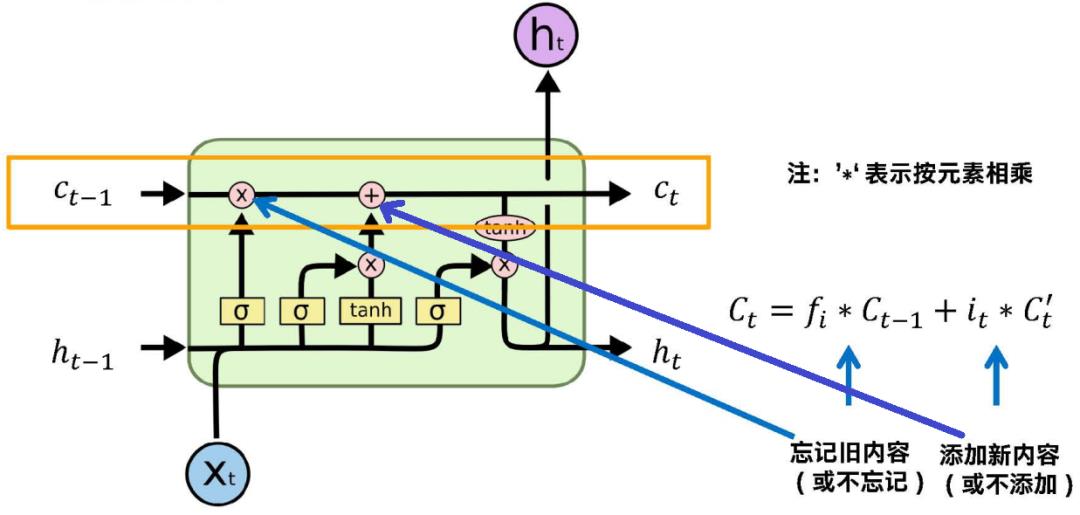
分两个阶段更新,结合两个图,前面是忘记后边是添加,得到一个新的状态,Ct-1是上一层的单元状态,记录的是前面穿过来的信息,通过忘记信息,再添加新的信息,最后更新新的状态。
我们看它是怎么忘记,怎么添加的?ht-1和Ct-1之间有什么关系?在循环神经网络中就只有一个ht-1,就是上一层的状态,这里它有两个状态,它们分工还算明确,Ct-1是保证信息的传输,ht-1是通过Ct-1通过输出门进一步过滤得到的一个状态值,是用来参与具体的循环概念上上一层状态的计算。ht可以对应经典循环网络上一层的状态,Ct是额外附加的,贯穿整个信息的。
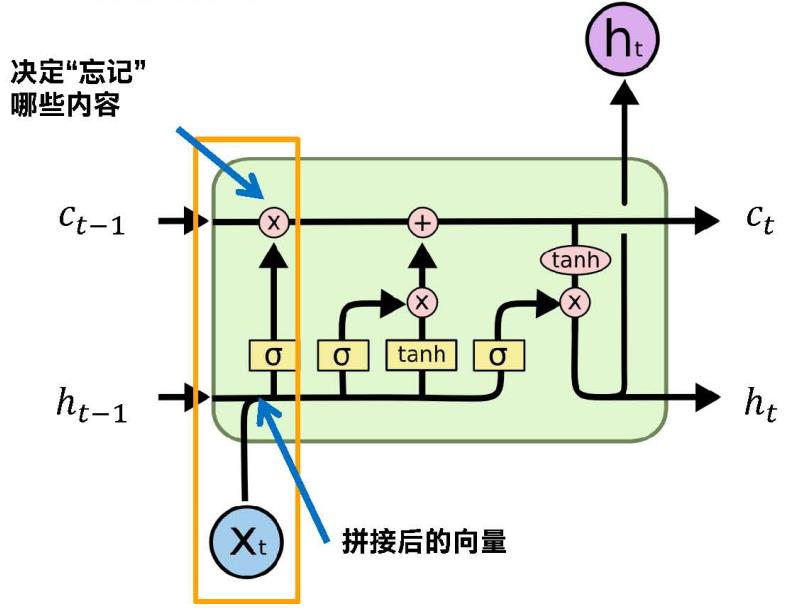
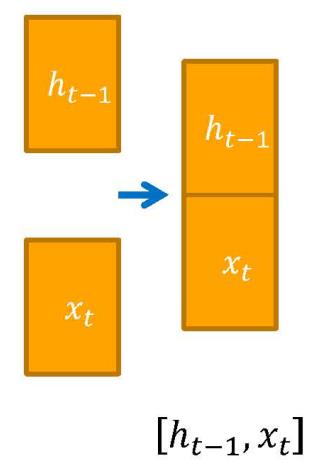
下面那些都是通过ht-1和Xt,拼接成长的向量,下面的好几个门都是以它为输入的,所以说前面输入都是固定的,通过不同的输入输入到不同的网络中,得到不同的门。
下图看框起来的部分,通过这个公式,通过公式外层那个函数进行激活,把所有的元素约束到0-1之间,跟门是天然对应的,0-无,1-有。通过函数得到的ft得到的就是一个门控,对应信息是0就忘记这部分信息,这部分信息是1就保留。这些值在0-1之间,所以不是绝对的忘记,有量化程度,有一定的概率去忘记。
然后我们把这个计算的向量和上层的单元状态进行一对一相乘,就是上层含有信息的和ft控制门对应向量一一相乘。
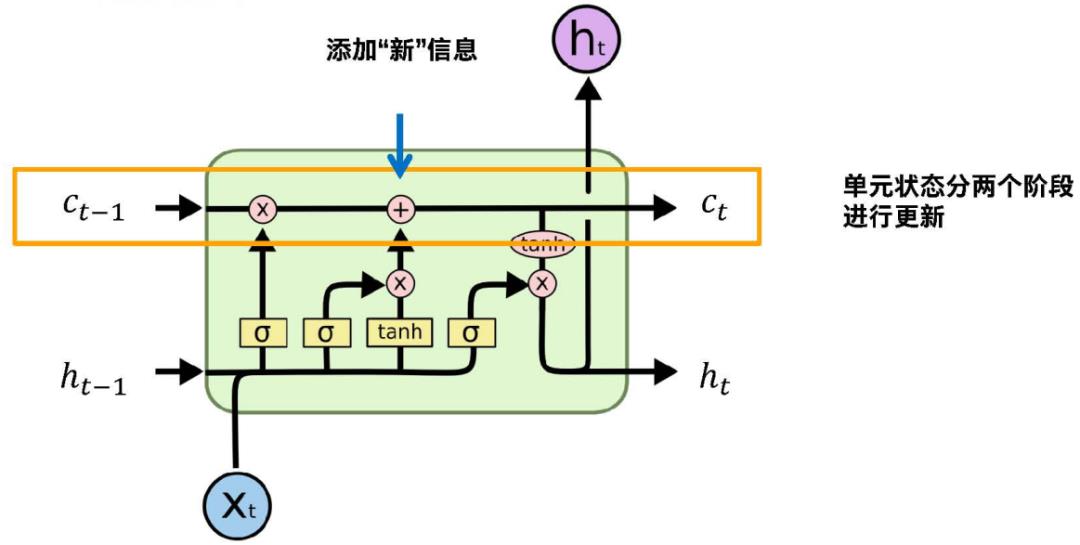
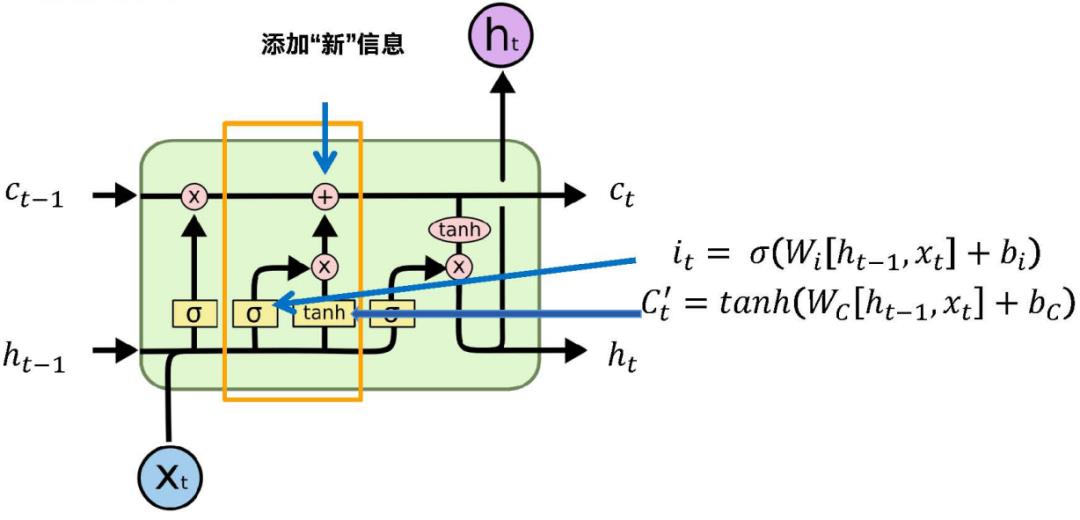
右边的公式是计算输入门,it是当前临时的状态,就是由当前的Xt和前一个状态ht-1计算得到的当前的信息。Ct这个信息是通过it输入门进行过滤,也是按位相乘,然后加到前面状态中。
Ct-1是上一个状态,跟忘记门按位一对一相乘,如果fi对应位置向量接近于0,对应信息选择忘记,然后得到一个信息,在这个基础上我们再加上it,输入门乘我们临时信息,也是按位相乘,对于对当前信息我们过滤掉一部分之后得到有用的信息,通过相加我们最终得到单元状态Ct。
我们有了Ct之后,可以算一个输出ht,是在Ct基础上得到的,又有一个门,总共三个门,忘记门、输入门、输出门。通过输出门对Ct再过滤,得到的ht才是作为下一步状态来传。
把内部复杂结构都去掉,其实就是循环神经网络,输入是Xt-1,输出是ht-1,是我们前面神经网络对应的状态,额外维护的是Ct,就是因为有了Ct才可以解决前面的梯度消失问题,长距离记忆问题。它只有过滤和相加操作,没有相乘,就尽量保证了长期信息,所以在Ct这条路上没有梯度消失,前面说梯度消失就是它会不断乘一个小于1的值,到最后,慢慢逼近0。
LSTM其实有很多不同类型,其实就是有复杂的门控机制,让复杂的神经网络解决了梯度消失问题,长距离问题。还有一个是GRU,相对LSTM结构较简单,没有LSTM流行。
LSTM不同的门不同的参数,所以参数比循环神经网络多很多,训练的时候时间很长,4倍吧。
持续输出干货有点累。。你的一个“点赞 分享”是我的动力
以上是关于标准循环神经网络记忆差怎么破的主要内容,如果未能解决你的问题,请参考以下文章