神经网络的可逆形式
Posted CV论文阅读专栏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络的可逆形式相关的知识,希望对你有一定的参考价值。
神经网络的可逆形式
最近在积累,好久没有写文章回顾一下了,近来我迷上了可逆网络,一开始是从CrevNet入坑的,这是一篇关于用了可逆网络的视频预测的方法。
其实简单的解释这个模型就是在预测生成模型之前把图片编码了一遍,如下图所示:
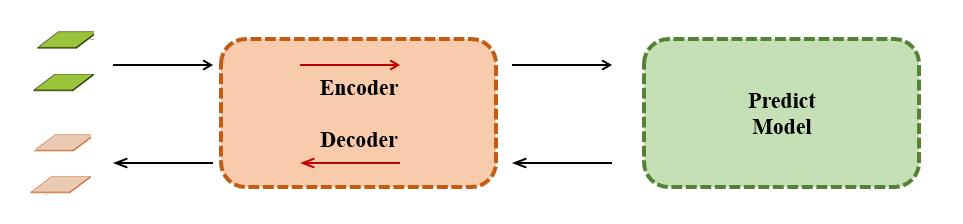
其中比较神奇的地方就是这个编解码器,这个编解码器就是由可逆网络的各个可逆模块构成的,同一个网络权重,既可以编码也可以解码。需要了解可逆网络最常用的设计,就能清楚地知道图片是如何编码成不同的形态,又能无损的解码回来。
可逆编解码
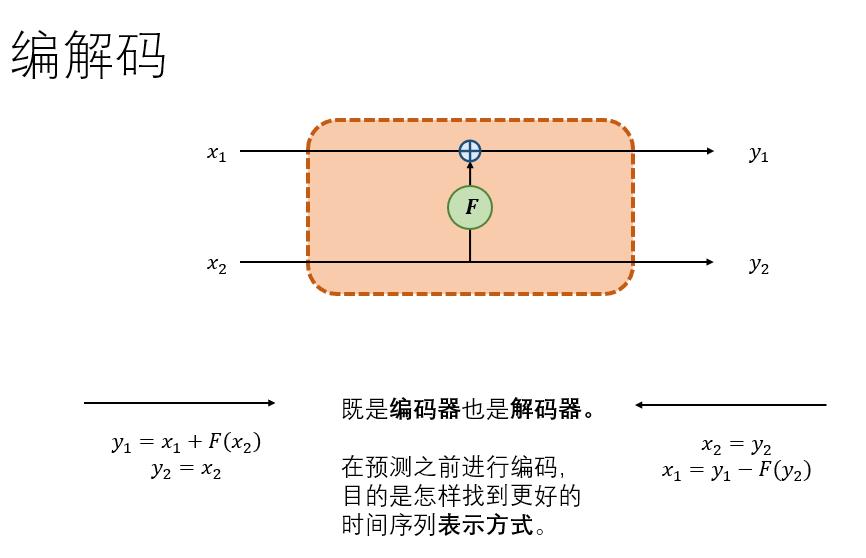
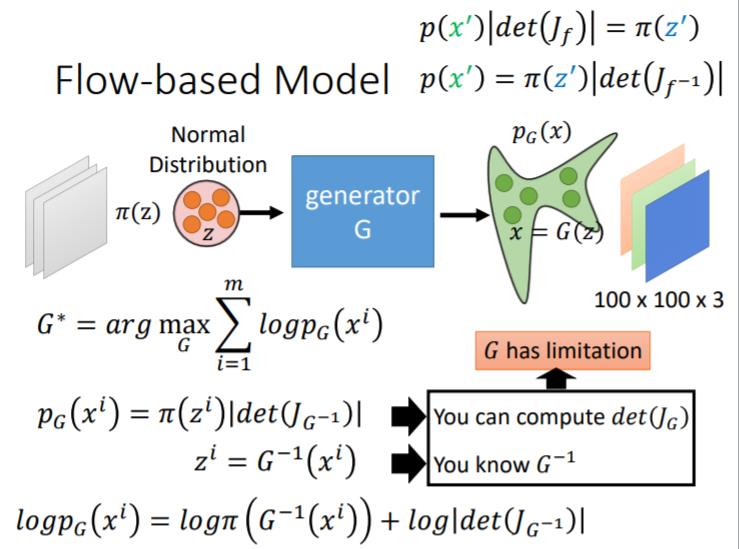
像是最常见的autoencoder,是由两个神经网络构成的,一个编码器,一个解码器。这里我介绍一种最简单的可逆编解码形式,如上图。
右侧方向为编码,假如数据一分为二 ,其编码公式如下:
其解码公式如下:
我们深入浅出的说,这里编码过程和解码过程很容易看懂,只要保留一部分数据其实就可以复原另一部分。这里的F可以任意复杂函数,可以是卷积,或者其他网络。
但是其中的原理是非常深奥的,从一系列的flow-based模型,NICE,RealNVP,Glow的提出,可以看到他们在生成领域的效果非常接近GAN模型了,但是确实还欠缺了一些。

在生成效果上他的不足主要是对模型限制很大,为什么这么说,这就要指出可逆网络的性质:
-
网络的输入输出shape必须一致(C x H x W,乘积一致) -
网络的雅可比行列式不为0
为什么神经网络会与雅可比行列式有关系?这里我借用李宏毅老师的ppt,想看视频的可以到b站上看。
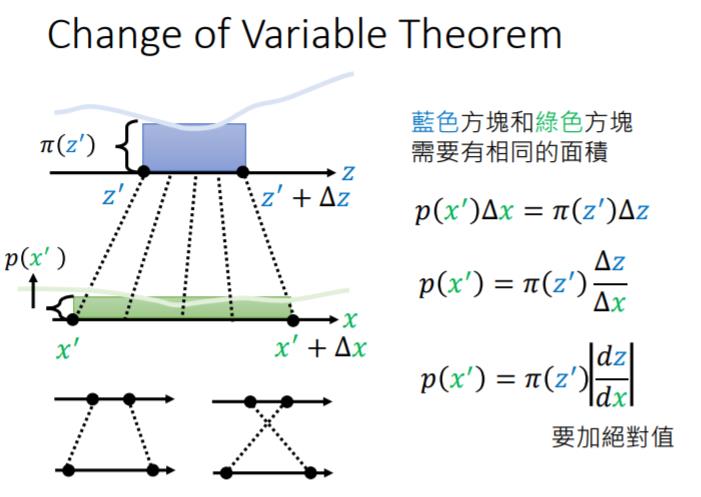
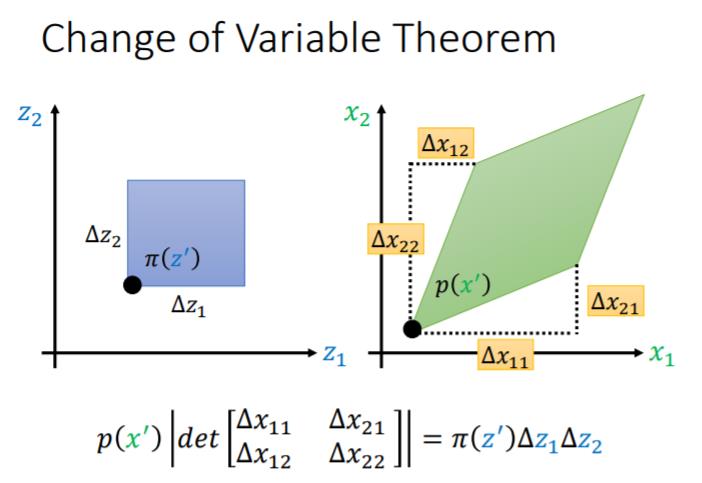
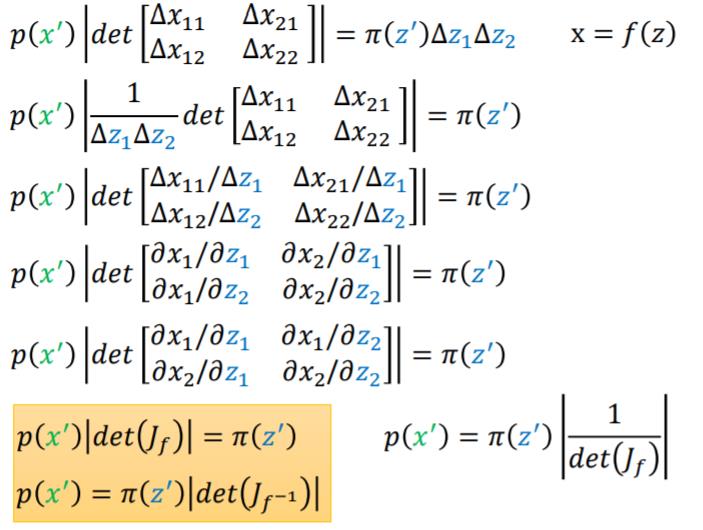
简单的来讲就是 ,他们的分布之间的关系就变为 ,
又因为有 ,所以 这个网络的雅可比行列式不为0才行。
顺便提一下,flow-based Model优化的损失函数如下:
其实这里跟矩阵运算很像,矩阵可逆的条件也是矩阵的雅可比行列式不为0,雅可比矩阵可以理解为矩阵的一阶导数。
回到一开始的可逆网络:
它的雅可比矩阵为:
其行列式为1。
可逆形式
但是有一些可逆网络的论文,算出来的的雅可比矩阵并不是恰好为1,很难证明恒不等于0,但是仍然有用的设计方法,如[The Reversible Residual Network:
Backpropagation Without Storing Activations](https://arxiv.org/abs/1707.04585):
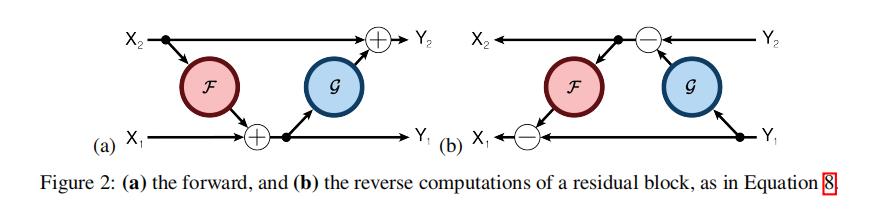
其编码公式如下:
其解码公式如下:
为了计算雅可比矩阵,我们更直观的写成下面的编码公式:
它的雅可比矩阵为:
其行列式就很难证明不为0了,姑且算为一种可以可逆的网络设计方式,也就是一种可逆形式。
另外最新的一篇ECCV2020的Invertible-Image-Rescaling(图像可逆缩放)的可逆形式的设计也让我觉得无法证明雅可比行列式为0,但是作者也说了这里并不是用作生成模型,只是作为图像缩放的工具。这篇论文的观点是非常新颖的,让我对这个方向有点新的感悟。
他是用在了SR(超分辨重构)的任务上,但是最后对比实验并不是真正的SR。他的insight是把误差给分离量化出来,用可逆网络的上下两个通路表达为误差和缩放后的图,反向传递的时候就是把误差从正态分布中采样,与LR图反向生成HR图。
这里为什么说不是SR任务呢,因为他这里的LR是由HR直接生成了又反向传递回去,而与之对比的是生活中产生的LR图想要得到HR图,或者说是Bicubic-based LR 想得到HR图,所以与之对比的是有些不公平。
但是作者解释道,这个可逆网络主要用在有HR图想要在传输时降低分辨,这确实可以解释地通,但是我觉得想要传输时其实直接压缩就好了,他这个既不是压缩也不是SR就有点奇怪。
以上是关于神经网络的可逆形式的主要内容,如果未能解决你的问题,请参考以下文章