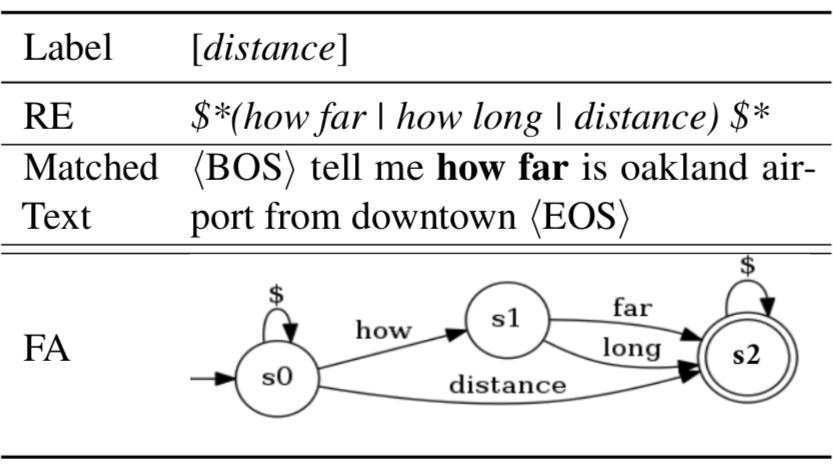
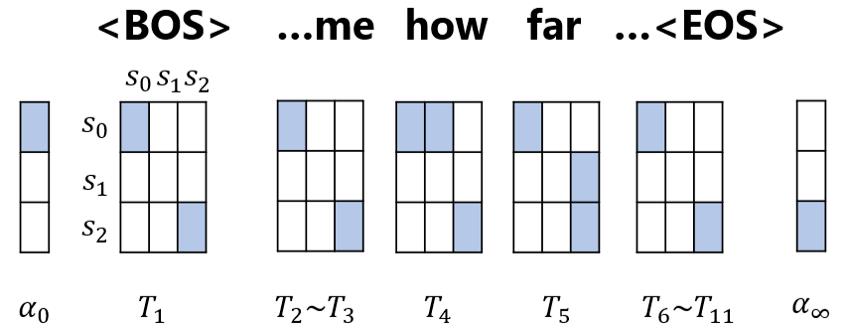
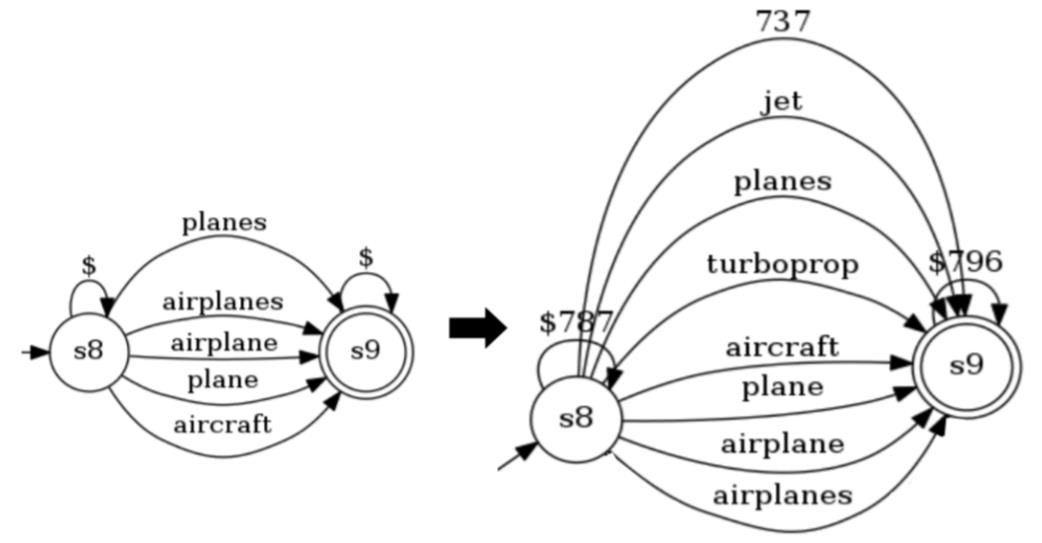
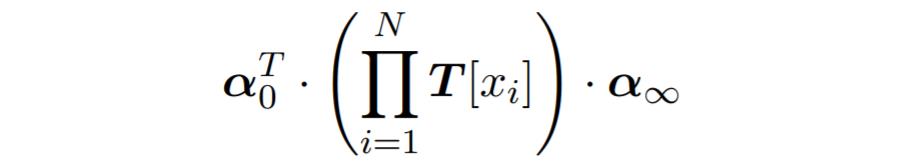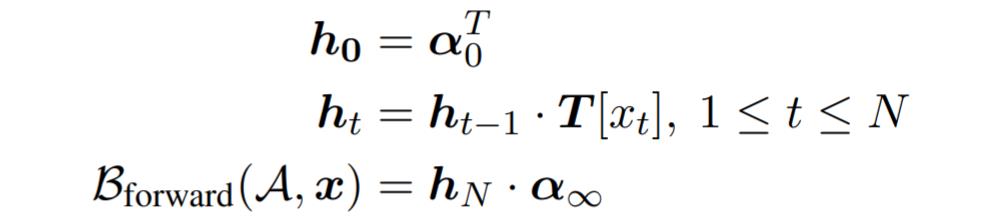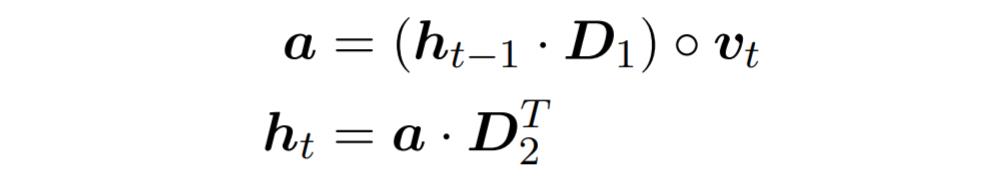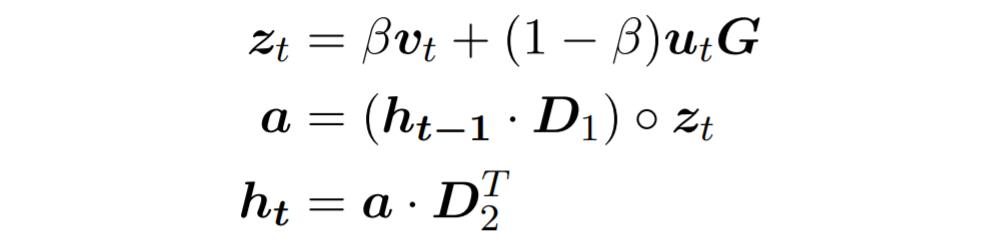我们会发现,这个有限状态自动机可以用一个三维张量,以及两个向量表示,张量的三个纬度分别是词表大小 V,自动机状态数 S,以及状态数 S,可以看成是由每个单词对应的转移矩阵 stack 起来组成。两个向量分别表示了自动机的初始状态以及结束状态。 如下图所示,对于一个句子,我们可以得到每一个单词的转移矩阵,若该矩阵的第 i 行第 j 列为 1,则表示可以通过该单词从状态 si 转移到 sj。因此,我们可以用前向算法(forward algorithm)或者维特比算法(viterbi algorithm)来计算句子被该自动机接受的分数。
▲ 图一
我们以前向算法为例:读完整个句子之后,从开始状态到达任一结束状态的路径数可以表示为:
我们只要改换一下 notation 以及公式的形式,这个计算过程就可以被看成一个 RNN。其中 A 是指自动机(automata),x 为句子。
ht 类似 RNN 中的隐状态向量,他的维度等于自动机状态数。ht 的每一个维度就表示:在读了 t 个单词之后,有多少条路径能够从开始状态到该维度对应的自动机状态。
1.2 规则的文本分类系统
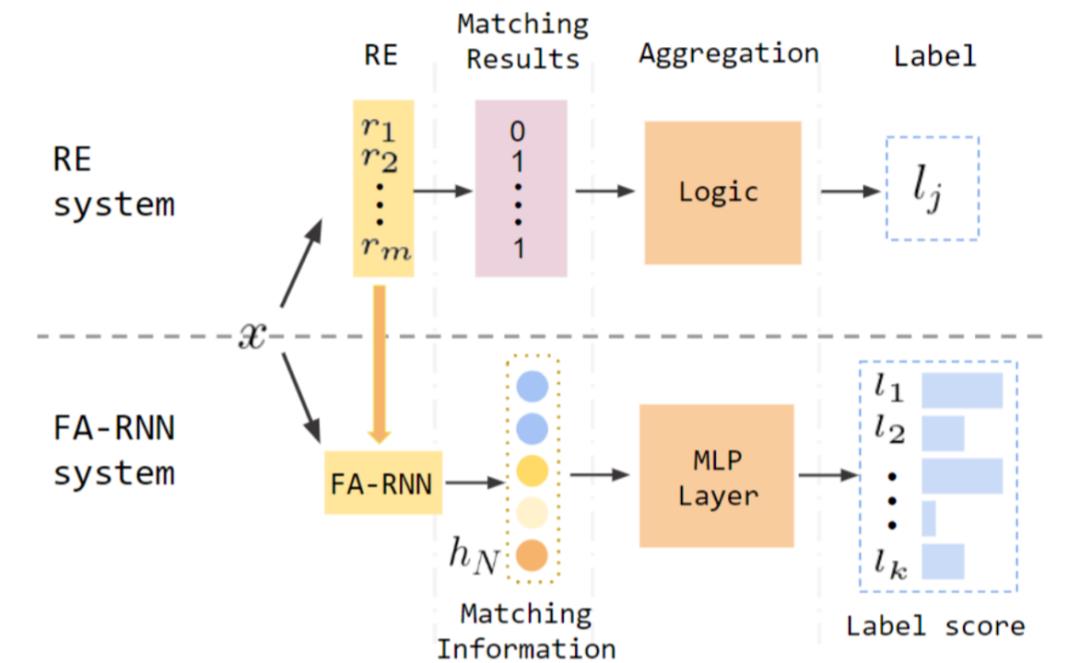
接下来我们描述一个基于正则表达式的文本分类系统。如下图的上半部分所示,我们针对输入句子运行所有的正则表达式,得到匹配结果,然后通过一些逻辑操作,将匹配的结果整合。 例如,如果一句话只被针对 A 类别的正则表达式匹配,那么他的标签是 A 类别;如果这句话被 A,B 两个类别都匹配,那么我们可以通过事先定义一个优先级关系来选出更可能的类别。这些都可以用逻辑操作来实现。 所以,正则表达式的分类系统先匹配(matching),再整合匹配结果(aggregation)来得到句子的标签。
记 t 时刻的输入为 x_t, 我们可以把 ER 看成一个只包含规则信息的词嵌入矩阵,vt 则是 ER 矩阵的对应行选出的 R 维词向量。由此,我们模型的参数量大大减少,相当甚至更少于 LSTM, GRU 等循环神经网络。接下来我们介绍我们结合词向量(如:glove)的方法。为了结合 D 维度的词向量,我们利用一个 DxR 的矩阵 G 将词向量从 D 映射到 R 维空间,这个矩阵 G 可以初始化为词嵌入矩阵 Ew 的违逆乘上 ER。我们再引入一个 0,1 之间的超参数来结合 vt 与 G 映射后的两个 R 纬词向量,控制接受多少词向量语义的信息,更新公式变为如下:
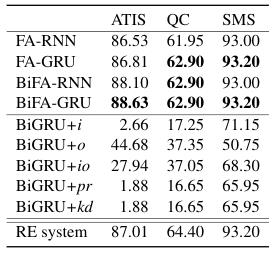
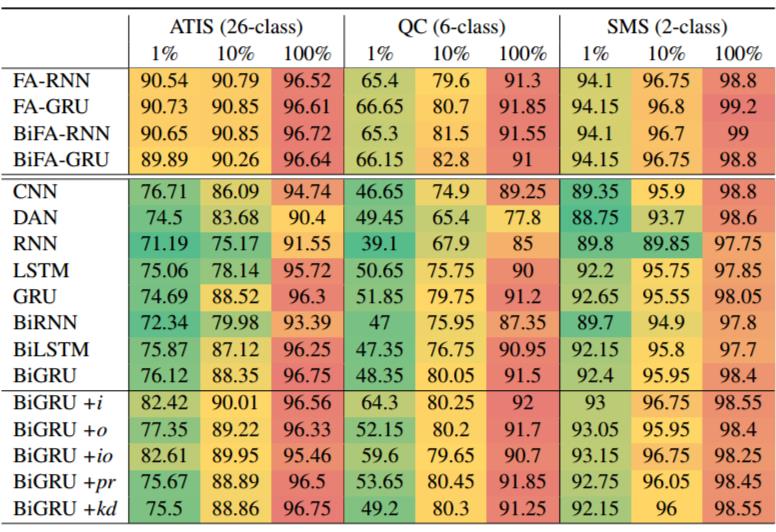
我们比较了结构对应的传统神经网络。具体结构为 BiRNN / BiGRU / BiLSTM / CNN / DAN 给句子做 encoding,用 Linear 层输出每个 label 的 score。除此之外,我们使用了一些已有方法将规则与传统神经网络结合。 分别是 Luo et, al 提出的三种利用正则表达式匹配结果的方式(+i: 将正则表达式匹配结果作为额外的特征输入,+o: 利用 RE 结果直接改变输出 logits, +io 前两者结合),以及两种基于知识蒸馏的方式,分别记为 +kd(Hinton et al., 2015)以及 +pr(Hu et al. 2016)。
3.2 数据集
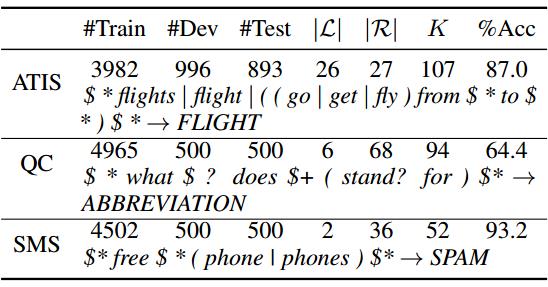
我们在三个文本分类数据集上实验,分别是 ATIS (Hemphill et al., 1990), Question Classification (QC) (Li and Roth,2002) 以及 SMS (Alberto et al.,2015). 我们使用了 glove 词向量。下表显示了数据集以及规则的统计信息以及样例。