神经网络中的损失函数正则化和 Dropout 并手写代码实现
Posted 计算机与AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络中的损失函数正则化和 Dropout 并手写代码实现相关的知识,希望对你有一定的参考价值。
在深度神经网络中最常用的方法是Regularization和dropout。在本文中,我们将一起理解这两种方法并在python中实现它们
Regularization 正则化
正则化通过在损失函数的末尾添加额外的惩罚项来帮助防止模型过度拟合。

其中m是批次大小。所示的正则化称为L2正则化,而L2对权重应用平方,而L1正则化则采用绝对值,其形式为| W |。
当权重过多或权重太大时,附加的额外项会增加损失,并且可调整因子λ着重说明了我们要对权重进行多少惩罚。
为什么添加惩罚会有助于防止过度拟合?
直观的理解是,在最小化新损失函数的过程中,某些权重将减小至接近零,因此相应的神经元将对我们的结果产生非常小的影响,就好像我们正在使用 更少的神经元。
前向传播:在前进过程中,我们只需更改损失函数。
def compute_loss(A, Y, parameters, reg=True, lambd=.2):
"""
With L2 regularization
parameters: dict with 'W1', 'b1', 'W2', ...
"""
assert A.shape == Y.shape
n_layer = len(parameters)//2
m = A.shape[1]
s = np.dot(Y, np.log(A.T)) + np.dot(1-Y, np.log((1 - A).T))
loss = -s/m
if reg:
p = 0
for i in range(1, n_layer+1):
p += np.sum(np.square(parameters['W'+str(i)]))
loss += (1/m)*(lambd/2)*p
return np.squeeze(loss)
反向传播:L2正则化的反向传播实际上是直接的,我们只需要添加L2项的梯度即可。
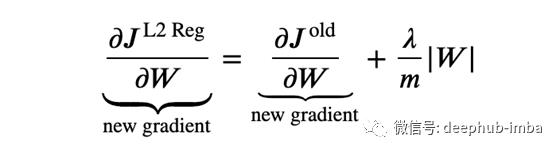
def backward(params, cache, X, Y, lambd=0.2):
"""
params: weight [W, b]
cache: result [A, Z]
Y: shape (1, m)
"""
grad = {}
n_layers = int(len(params)/2)
m = Y.shape[1]
cache['A0'] = X
for l in range(n_layers, 0, -1):
A, A_prev, Z = cache['A' + str(l)], cache['A' + str(l-1)], cache['Z' + str(l)]
W = params['W'+str(l)]
if l == n_layers:
dA = -np.divide(Y, A) + np.divide(1 - Y, 1 - A)
if l == n_layers:
dZ = np.multiply(dA, sigmoid_grad(A, Z))
else:
dZ = np.multiply(dA, relu_grad(A, Z))
# with an extra gradient at the end, other terms would remain the same
dW = np.dot(dZ, A_prev.T)/m + (lambd/m)*W
db = np.sum(dZ, axis=1, keepdims=True)/m
dA = np.dot(W.T, dZ)
grad['dW'+str(l)] = dW
grad['db'+str(l)] = db
return grad
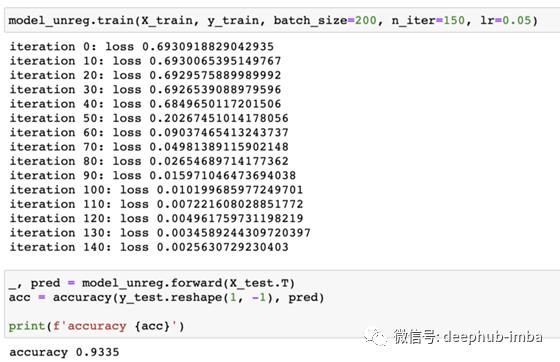
训练过程:像往常一样,我们在二元分类的情况下测试我们的模型,并比较有无正则化的模型。
没有正则化的模型
有正则化的模型
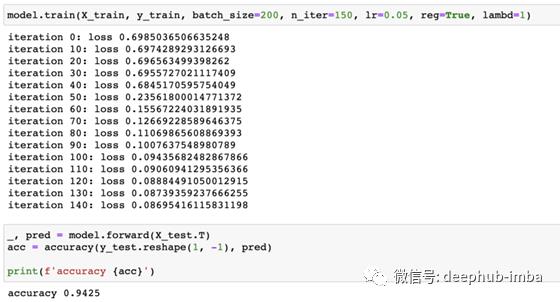
实际上,当迭代次数增加时,该模型将继续过拟合,从而导致除法运算出错,造成这种问题的原因可能是在正向过程中,结果A太接近于0。
相反,具有正则化的模型不会过拟合。
Dropout
Dropout通过随机关闭某些输出单元来防止过度拟合。
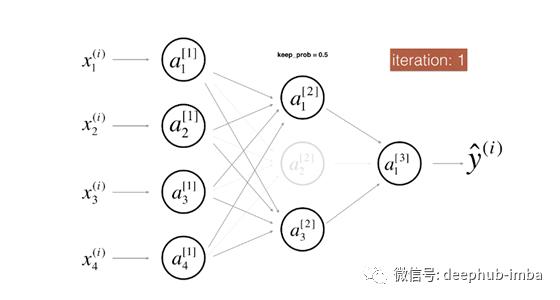
在上述过程中,在每次迭代中,层[2]上的某些单元将被随机关闭,这意味着在正向过程中将工作的神经元更少,因此简化了神经网络的整体结构。
同时,训练后的模型将更加健壮,因为该模型不再可以依赖任何特定的神经元(因为在此过程中它们可能会被静音),因此所有其他神经元都需要在训练中学习。
前向传播:你可以理解为Dropout是在前向传播过程中增加了一层。
一般情况下,正向传播方程如下:
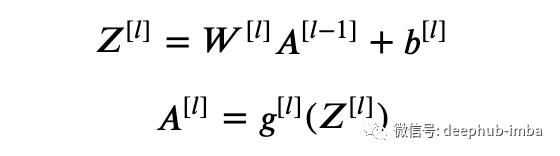
其中g是激活函数。现在,通过Dropout将一个额外的图层应用于A ^ [l]。
添加了Dropout如下:
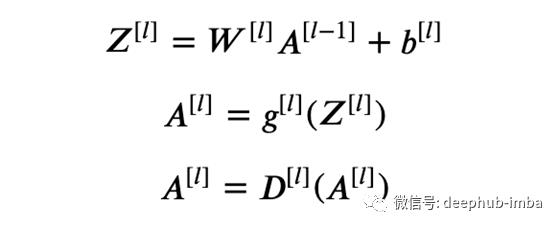
其中D是Dropout层。Dropout层中的关键因素是keep_prob参数,该参数指定保留每个单元的可能性。假设keep_prob = 0.8,我们将有80%的机会保持每个输出单位不变,而有20%的机会将其设置为0。
该实现将为结果A添加一个额外的掩码。假设我们有一个包含四个元素的输出A ^ {[l]},如下所示,
我们希望在保持其余部分不变的情况下使第三个单元关闭,我们需要的是形状相同的矩阵,并按以下方式进行元素逐次乘法,
前向传播:
def forward(X):
# intermediate layer use relu as activation
# last layer use sigmoid
n_layers = int(len(params)/2)
A = X
cache = {}
for i in range(1, n_layers):
W, b = params['W'+str(i)], params['b'+str(i)]
Z = np.dot(W, A) + b
A = relu(Z)
# dropout
keep_prob = keep_probs[i-1]
D = np.random.rand(A.shape[0], A.shape[1])
D = (D < keep_prob).astype(int)
A = np.multiply(D, A)
# rescale
A = A/keep_prob
cache['Z'+str(i)] = Z
cache['A'+str(i)] = A
cache['D'+str(i)] = D
# last layer
W, b = params['W'+str(i+1)], params['b'+str(i+1)]
Z = np.dot(W, A) + b
A = sigmoid(Z)
cache['Z'+str(i+1)] = Z
cache['A'+str(i+1)] = A
return cache, A
在这里,我们将D初始化为与A相同的形状,并根据keep_prob将其转换为0和1矩阵。
请注意,dropout后,结果A需要重新缩放!由于在此过程中某些神经元被静音,因此需要增加左神经元以匹配预期值。
反向传播:过程是将相同的函数D屏蔽为相应的dA。
# dummy code, full version needs to be inside a Class
def backward(self, cache, X, Y, keep_probs):
"""
cache: result [A, Z]
Y: shape (1, m)
"""
grad = {}
n_layers = int(len(self.params)/2)
m = Y.shape[1]
cache['A0'] = X
for l in range(n_layers, 0, -1):
A, A_prev, Z = cache['A' + str(l)], cache['A' + str(l-1)], cache['Z' + str(l)]
W = self.params['W'+str(l)]
if l == n_layers:
dA = -np.divide(Y, A) + np.divide(1 - Y, 1 - A)
if l == n_layers:
dZ = np.multiply(dA, self.sigmoid_grad(A, Z))
else:
# dropout version
D = cache['D' + str(l)]
dA = np.multiply(dA, D)
# rescale
dA = dA/keep_probs[l-1]
dZ = np.multiply(dA, self.relu_grad(A, Z))
dW = np.dot(dZ, A_prev.T)/m
db = np.sum(dZ, axis=1, keepdims=True)/m
dA = np.dot(W.T, dZ)
grad['dW'+str(l)] = dW
grad['db'+str(l)] = db
return grad
反向传播方程式与一般的神经网络网络中引入的方程式相同。唯一的区别在于矩阵D。除最后一层外,所有其他具有丢失的层将对dA施加相应的蒙版D。
注意,在反向传播中,dA也需要重新缩放。
结论
正则化和dropout都被广泛采用以防止过度拟合,正则化通过在损失函数的末尾添加一个额外的惩罚项来实现,并通过在正向过程中随机地使某些神经元静音来使其退出以使网络更加简洁来实现正则化。
最后所有的代码都可以在这里找到:https://github.com/MJeremy2017/deep-learning/tree/main/regularization
作者:Jeremy Zhang
deephub翻译组
以上是关于神经网络中的损失函数正则化和 Dropout 并手写代码实现的主要内容,如果未能解决你的问题,请参考以下文章
激活函数,Batch Normalization和Dropout
dropout是什么?为什么dropout管用?测试集上是否需要使用dropout?说明为什么神经网络中的dropout可以作为正则化?