专栏 | 蒙特卡洛树搜索在黑盒优化和神经网络结构搜索中的应用 Posted 2021-04-26 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专栏 | 蒙特卡洛树搜索在黑盒优化和神经网络结构搜索中的应用相关的知识,希望对你有一定的参考价值。
布朗大学在读博士王林楠在本文中介绍了他与 Facebook 田渊栋团队合作,在 2020 年 NeurIPS 取得亮眼表现的新算法,以及其在神经网络结构搜索中的应用。
现实世界的大多数系统是没有办法给出一个确切的函数定义,比如机器学习模型中的调参,大规模数据中心的冷藏策略等问题。这类问题统统被定义为黑盒优化。黑盒优化是在没办法求解梯度的情况下,通过观察输入和输出,去猜测优化变量的最优解。在过去的几十年发展中,遗传算法和贝叶斯优化一直是黑盒优化最热门的方法。不同于主流算法,本文介绍一个基于蒙特卡洛树搜索(MCTS)的全新黑盒优化算法,隐动作集蒙特卡洛树搜索 (LA-MCTS)。LA-MCTS 发表在 2020 年的 NeurIPS,仅仅在文章公开几个月后,就被来自俄罗斯 JetBrains 和韩国的 KAIST 的队伍独立复现,并用来参加 2020 年 NeurIPS 的黑盒优化挑战,分别取得了第三名和第八名的好成绩 [10][11]。
黑盒优化是一个已经发展了几十年的领域了,在跟很多人交流我们工作的时候,我被问到最多的问题就是,我们算法和遗传算法以及贝叶斯优化有什么优势?为了更好的理解这个问题,首先让我们来看看遗传算法和贝叶斯优化是如何工作的。
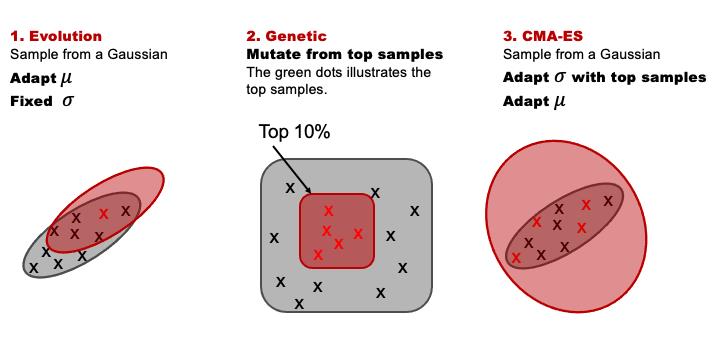
遗传算法 :遗传算法有很多变种,但是大体上是这图上这 3 类。
1)
Evolution
: 首先是用一个固定的 multi-variate gaussian 来建模下一步从哪儿去采样(如上图的 Evolution)。在当下的 iteration 撒一堆点,然后找出这堆点当下最优的解,然后把这个 multi-variate gaussian 的均值重新放到这个最优解。由于不变,所以下一个 iteration 做采样的时候那个 region 的样子也不变。
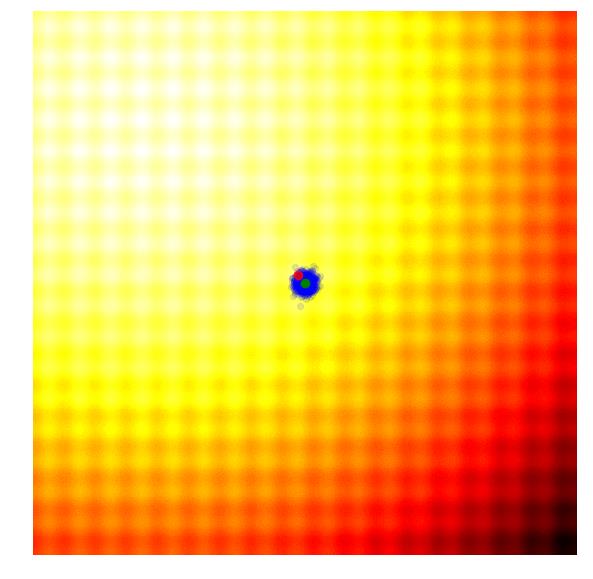
这里我们给出了一个优化 2 维 Rastrigin 的例子。Rastrigin 函数如下图,
下图呈现了 Evolution 算法的优化过程。由于 σ 不变,每次采样出来的蓝色的点的分布在每个 iteration 都是差不多的。并且当下 iteration 中,采样分布所用的 μ
,是上一个 iteration 中采样出来的最好的点,即图中红色的点。
2)
Genetic
: 这个核心思想就是抽取一个 pool 来追踪当下样本中的 top 10%(可以设置的超参变量),然后在这个 pool 里进行变异。同样下图可视化了该算法在 2 维 Rastrigin 的优化过程。图中绿色的点就是当下 top samples,在下一个 iteration 中的蓝色 samples 都是由上一个 iteration 中的绿色的 samples 变异而来。
3)
CMA-ES
: 和 Evolution 相比,它不光变 μ
,而且同时变 σ
。其核心思想是同样追踪当下 top samples,然后用 top samples 来更新 μ
和 σ
,而不是像 evolution 里只把 μ 改到了当下最优的 sample 上。所以这里的采样区间会动态的变化,特别是 top samples 分布比较分散的话,采样区间就会很大。当 top samples 收敛到一个最优解附近时候,采样空间就自动减小了,因为 top samples 之间的 variance 小了。
同样我们可视化了 CMA-ES 在优化二维 Rastrigin 函数的过程。一开始采样区域迅速增大,那是因为 top samples (图中紫色的点) 的分布越来越散,导致用来采样的 gaussian 的 σ
增大,所以采样区域不过往最优解附近靠近(通过更新 μ
), 而且采样空间也迅速增大。但是到了后期采样,由于紫色的点慢慢靠拢,所以 σ
减小,同时也导致采样空间缩小。
遗传算法的问题 :由此可以看出,遗传算法并不是特别适合 NAS,因为他每个 iteration 需要撒很多的神经网络来更新采样分布。然而来评估一个神经是非常耗时的,无论是重头训练一遍,还是用 supernet。
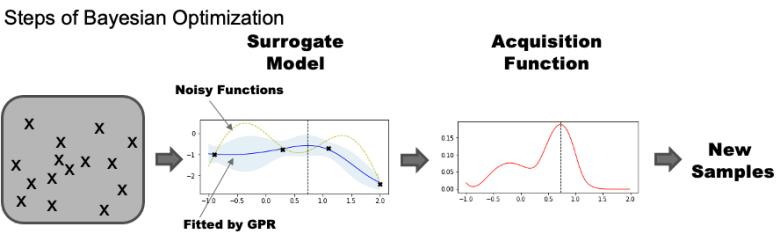
贝叶斯优化 :同样贝叶斯优化有很多变种,但是大体上算法可以归为下来几步。
1)
Surrogate Model
: 这一步利用一个函数拟合器,根据当下现有的采样,来 fit 一个黑盒函数。
2)
Acquisition Function
: 这一步就是贝叶斯优化的探索(exploration)和利用 (exploitation) 机制。他利用 Surrogate Model 和当下采样的分布,来选择下一个采样的位置。
同样是优化二维的 Rastrigin 函数,贝叶斯优化的采样效率会比遗传算法好很多,如下图。图中的每一个点都对应的一个采样,红色的点代表最优解。因为贝叶斯优化里利用了一个 Surrogate Model 去猜那里比较好,所以采样效率会高很多。
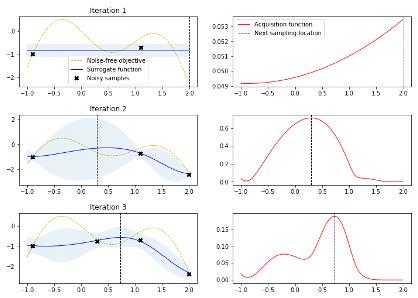
贝叶斯优化的问题 :但是在高纬问题中,贝叶斯优化会过度的探索边界,导致大量的样本被浪费[8][9]。为了理解这个问题,我们来看下面优化一个一维函数的例子。左图中的 x 是从 iteration 1-> iteration3 的采样,右图是 acquisition function,最高的地方即是采样点。可以看出前几个 iteration 基本在探索那些附近没有样本的区域。
因为我们这里看到的只是一维问题,当问题纬度扩展到 20d+,这个时候贝叶斯优化一开始就需要非常多的点来探索搜索空间。这也就是为什么很多人会观测到,在高纬度问题中,贝叶斯优化在少量样本下,会跟随机搜索差不多。
而这些一开始作为探索的样本,一般都会落在搜索空间的边界。至于为什么会是边界,这个跟欧几里得空间有关。简单来说,一个立方体,靠近边界部分的体积会远大与内核部分的体积。以此类推,在一个 n 维立方体里,大部分的搜索空间都在边界,所以探索一开始会探索边界。
Latent Action Monte Carlo Tree Search(LA-MCTS)
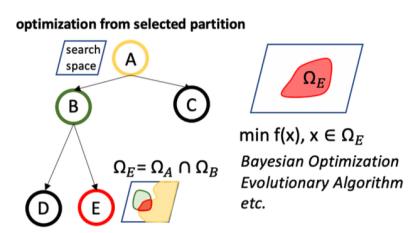
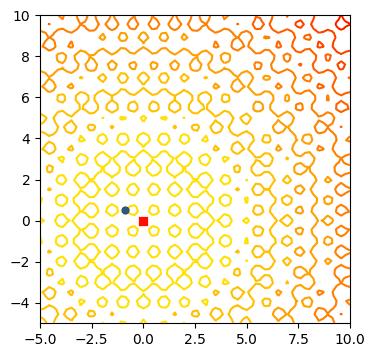
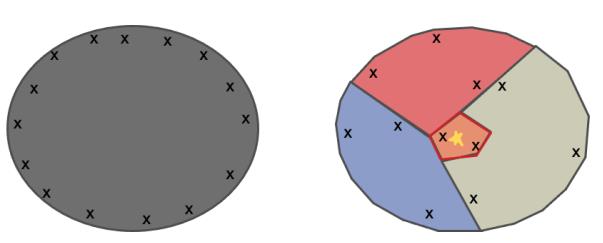
为了解决贝叶斯优化在高维空间过渡探索的问题,我们的解决方案是,去学习切割搜索空间。这里的核心动机如下图。当我们切分搜索空间后,把原问题划分为更小的子问题,然后用贝叶斯优化来解。虽然在子问题也会出现过度探索,但是这个时候的样本落点和原问题的样本落点很不一样,如下图。所以划分子空间后,可以从某种程度上减轻过度探索的问题。
LA-MCTS 的核心思想就是,我们希望学习一些边界去划分搜索空间。这些边界还能够自动去适应函数值的变化。当我们在划分出来的好的空间去采样的时候,出来的样本也期望是好的,同理在坏的空间,采样出来的样本也相对较差。
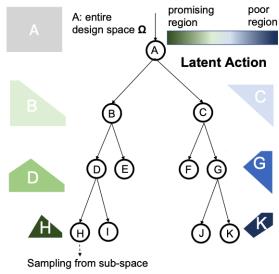
上图是我们算法的一个大体框架。在每一个树的节点上,我们想学到一个边界,根据当下的采样点(既 x 和 f(x)),能够把搜索空间分为一个好的子空间(左节点),和一个坏的子空间(右节点),如上图。而这里的隐动作集 (Latent Action) 就是,从当下节点选择去左 / 右孩子。至于动作的选择,在每个节点是根据 UCT 公式来决定。因为每个节点对应一个搜索空间,这个搜索空间上有相应的样本。每个孩子上对应搜索空间的样本的个数就是 UCT 里的 n,而这些样本性能的平均值就是 UCT 里的 v。当我们对搜索空间建立这样的一个搜索树,随着树深度的增加,在搜索空间找到好的区域也越来越精确。
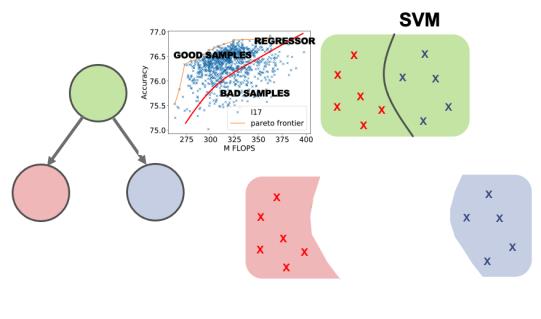
根据上述的定义,Latent Action 是把一个空间分成一个好的子空间,和一个坏的子空间。假设在任何一个节点上,我们首先学习一个 regressor 来把当下节点上的样本分为好样本和坏样本,然后我们通过 SVM 来学习出一个边界来把当下节点的搜索空间分为两个部分,一个好的搜索空间和一个坏的搜索空间。因为处在 regressor 上的样本 f(x)更高,所以分出来的空间是好空间。然后这两个子空间被两个子节点所代表,并且相应子空间上的样本也去相对应的节点。这就构成了我们整个树模型的最基本的单元。
有了这个最基本的模型,下来介绍下算法的 3 个基本步骤。
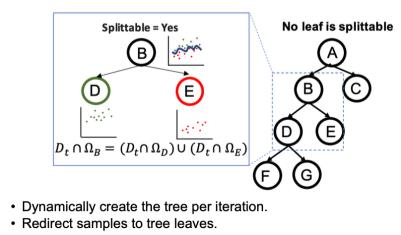
1)Learning and split: 在每个 iteration 开始,因为上个 iteration 有新的样本,我们需要重新构建一个树来分割搜索空间。同样,一开始的 root 节点包含所有的样本,同时并代表了整个搜索空间。我们这样递归的利用 latent action 来把一个节点分成两个节点,直到树上的叶子结点内,包含不超过 20(超参可以调)个样本。所以树的样子完全由样本决定的。下图描述了这个过程。
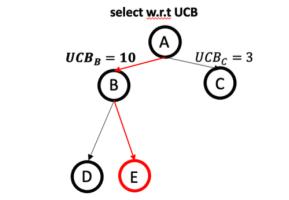
2) Select: 从树的根开始,我们计算出每个节点的 UCB 数值。访问次数就是当下 node 里有多少 samples,均值就是当下 node 里样本的均值,即 f(x)的均值。然后我们从跟节点到叶子,一直选 UCB 最大的。这个过程如下图。
3)Sampling: 根据我们选出来的一条路径,这个路径上的 SVM 就包裹出了一个子搜索空间,如下图的
。然后,我们只在这个子空间上进行贝叶斯优化即可。
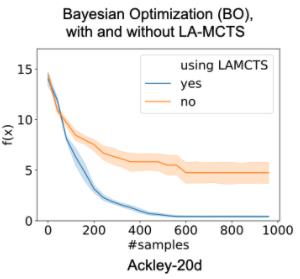
最后我们很快的来看一下 LA-MCTS 应用在贝叶斯优化的效果。更多的数据,请参考我们的文章。
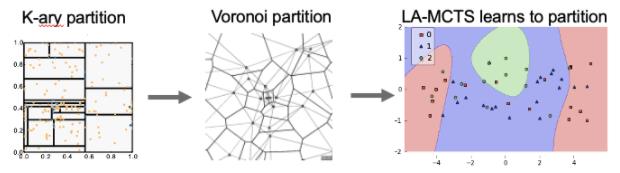
其实早在 2011 年,Rémi Munos (DeepMind) 提出利用 MCTS 来分割搜索空间用来优化一个黑盒函数 [4],然后,剑桥大学和 MIT,有很多工作把这种切分搜索空间的思想用在了高维贝叶斯优化 [5][6]。但是这些工作一般都会采用一个 k-ary 区块切分(如下图)。2020 年,MIT 的 Beomjoon Kim 在[7] 展示出利用沃罗诺伊图(Voronoi Graph)去切分搜索空间,结果会更好。我们的工作,LA-MCTS,则是利用了 learning 的法则,根据当下样本来学习分割方法,来提高搜索效率。
LA-MCTS 的一些有待改善的地方:目前我们观测到 UCB 中的 exploration 变量 c 对结果影响比较大,毕竟 Cp=0 的时候 LA-MCTS 就变成了一个 random 算法,而 Cp=1 的时候,就是一个纯 greedy 的算法了。目前我们发现大多数把 Cp = 0.1*max f(x) 工作的比较好,这里的 max f(x) 是猜测出来的函数最大值。当然在实际使用中,可以在 search space 先大概跑一跑,看什么样的 Cp 下降的比较快。如果大家在使用 LA-MCTS 感觉效果不太好,很可能是这里出了问题。
其次,SVM 在有些时候不是很稳定,比如 kernel type 的选择。还有,目前我们采样还是基于 sampling 的方法,未来可以考虑通过 LBFGS 来解一个 constrained optimization 问题,这里的 constrains 是 SVM 的边界。总而言之,未来还有很多需要解决的问题。
LA-MCTS 在 NeurIPS-2020 黑盒优化挑战的表现
当然文章里的数据是漂亮啦,但是要其他人复现出来同样说好那才好。在今年 NeurIPS-2020 中,Facebook, Twitter, SigOPT, 第四范式等活跃在黑盒优化领域内的公司,发起了一个黑盒优化挑战赛,试图去寻找当下最优的黑盒优化器。该挑战利用各个参赛团队提交的优化器,去解决 216 个不同领域的黑盒优化问题。当然,每个优化器在不同的问题上也是跑了很多次去取平均,来保证比赛的公正。更多这个比赛的详情,大家可以参照这里 https://bbochallenge.com/virtualroom。
总结一下,LA-MCTS 在这次比赛分别被第三名的 JetBrains 和第八名的 KAIST 团队独立复现我们的算法(因为当时还没有放出源代码),并参加这次比赛。值得一提的是,第一名和第二名的队伍均采用 ensemble 不同 solver 的方法(比如不同的 acquisition),而第三名只使用一种 solver。所以我个人认为未来探索 ensemble 和 learning search space partition 会是一个比较有意思的问题。最后,我个人很喜欢的一个黑盒优化算法 TuRBO,在前十名队伍中,被六个队伍所广泛采用。
更值得一提的是,在 NAS 方面发表出的很多 search 算法,比如用神经网络或者图神经网络做 predictor,或者 RL,SGD (finite difference 类),并没有在这次比赛中表现出非常优秀的成绩。
把 LA-MCTS 应用在神经网络结构搜索(NAS)
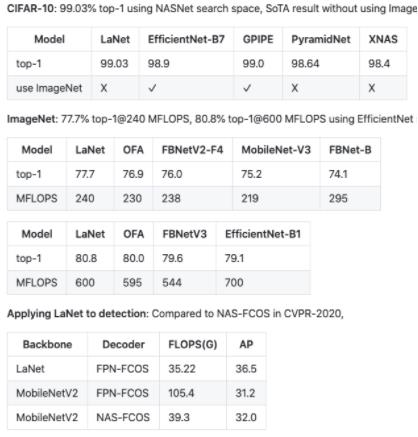
我们同时也把 LA-MCTS 应用在神经网络结构搜索给 CIFAR-10,ImageNet,Detection 等。下面是我们搜索出来的网络的结果。
1. 起源:应用蒙特卡洛树搜索在神经网络结构搜索。
2017 年初,我的导师从美国国防高级研究计划局的 D3M 项目拿到了一笔项目资金,开启了我们的 AutoML 研究。而我被分配的子任务,就是神经网络结构搜索 (NAS)。当时 NAS 研究的 2 篇文章,都是利用强化学习(谷歌的 policy gradients 和 MIT 的 Q-learning)。我们发现 Q-learning 的 epsilon greedy 非常简单的同等对待了所有的状态(states),并不考虑每个 states 过去探索了多少次,所以并不能很好的去平衡利用(exploitation) 和探索 (exploration)。从这点出发,我们考虑对每个状态去建模,来更好的平衡利用和探索,来提高搜索效率。而蒙特卡洛树搜索(MCTS) 正是对每一个状态建模,利用 UCT 来动态的平衡利用和探索。同时,AlphaGo 的成功证实 MCTS 在大规模状态空间下效果非常好。在这样的背景下,我们开发第一个基于 MCTS 的 NAS 算法,并命名为 AlphaX。
AlphaX 构建网络和 MIT 的 Q-learning 算法相似。从一个空网络开始,根据动作集,比如添加一个 conv 或者 pooling,逐层构建一个网络架构(s→a→s’)。因为训练一个网络非常慢,AlphaX 提出利用一个价值函数预测器(value function predictor)来预测当下状态下的子网络们的性能。这个价值函数器输入就是一个网络架构,输出就是预测的该网络的精度。同时我们验证了,NAS 能够提升很多下游的视觉应用,比如风格迁移,目标检测等。详情请见[1]。
2. 学习蒙特卡洛树里的动作集,从 LaNAS 到 LA-MCTS。
基于 AlphaX,我 FB 的导师田渊栋洞察到动作集在 AlphaX 对搜索效率有着显著的影响。为了证实这个想法,我们设计了动作集 sequential 和 global。动作集 sequential 就是按照逐层构建网络的思路,一步步的增加 conv 或者 pooling,并指定每层的参数;而动作集 global 则首先划定网络的深度,比如 10 层网络。然后同时给这 10 层网络指定每层的种类,参数等。我们发现动作集 global 的搜索效率显著高于动作集 sequential,并且可视化了状态空间,如下图。
直观上而言,状态空间在 global 的动作集下,好的状态(深色)和差的状态(浅色)区分的很好,不像 sequential 混杂在一起。这样搜索算法可以很快找到一个好的区域,所以效率更高。基于这个观察,促使我们去给 MCTS 学习动作集,并提出了 Latent Action Monte Carlo Tree Search (LA-MCTS)。
我们最初把这个想法应用在了 NAS,并构建了一个 NAS 系统命名为 LaNAS[2]。对比贝叶斯优化和进化算法,LaNAS 在 NAS 的基准数据集 NASBench-101 上取得了显著的提升。所以我们又扩展了 LaNAS 成为了 LA-MCTS 去做应用更广的黑盒优化。从 LaNAS 到 LA-MCTS,核心更新有:1)LA-MCTS 把 LaNAS 里的边界扩展成一个非线性边界,2)LA-MCTS 在采样的时候利用贝叶斯优化来选择样本。最后,LA-MCTS 在各种测试函数和 MuJoCo 上取得了显著的提升,详见[3]。
我认为是重要的。以下是我观测到的一些趋势及我的思考。
1)最近有些文章展示随机搜索都可以达到很好的结果,那么是不是意味着搜索不重要了?
首先这些文章是说随机搜索得到的结果还不错,是一个非常强的对比基准。这个往往因为目前的搜索空间的设计,导致大部分网络结果都很好,比如下图所呈现的 NASBench-101 中 42 万个网络的分布(横轴是精度,纵轴是这个精度下有多少网络 log scale)。所以找出一个工作还不错的网络并不难。
2) 既然搜索空间的设计影响很大,那么是不是更应该把注意力放在设计搜索空间,而不是搜索?
我觉得这个问题应该站在不同的角度。首先,近几年神经网络的高速发展让我们在设计搜索空间的时候有了很多先验经验,所以设计出来的搜索域里的网络都不会太差。在一些传统的视觉应用,搜索的贡献可能就不如加各种 tricks 或者调参数在工程中来的更实际一些。但是如果当我们遇到一个新的任务,比如设计一个神经网络去调度网络节点。由于先验经验很少,这个时候搜索就可以极大的加速我们设计网络的速度。并且搜索可以提供很多的经验去让我们改进搜索空间。
3)基于搜索方法的 NAS 和 DARTS 类算法的对比。
以 DARTS 为代表的 one-shot NAS 方法跑的很快,是因为利用了一个超级网络 (Supernet) 去近似每个网络的性能。在这个过程中,Supernet 相当提供一个网络性能的预测,然后利用 SGD 在 Supernet 上去找一个比较好的结果。这里 Supernet 和 Search 也是可以分开,而且分开后更易分别提高这两个部分。所以只需要把 Supernet 的概念应用在传统搜索方法上,也是可以很快得到结果。SGD 的问题是很容易卡在一个局部最优,而且目前 SoTA 的结果基本都是利用传统搜索方法直接,或者利用一个 supernet 搜索出来的。
Github 地址:https://github.com/facebookresearch/LaMCTS
Neural Architecture Search,全网最全的神经网络结构搜索 pipeline。
开源 LaNAS on NASBench101:无需训练网络,在你笔记本上快速评估 LaNAS。
开源 LaNAS 搜索出的模型「LaNet」:在 CIFAR-10 和 ImageNet 上都取得 SoTA 结果。
开源 one-shot/few-shots LaNAS:只需几个 GPU,快速并且高效完成神经网络结构搜索。含搜索,训练,整套 pipeline。
分布式 LaNAS:让我们用上百个 GPU 来超过最先进的模型。整套 pipeline。
Bag of tricks 模型训练的那些黑科技:我们列出当下训练模型的一些提升点数黑招数。
Black-box optimizations,黑盒优化
1 分钟的对比:只需 1 分钟,评测 LA-MCTS,和贝叶斯优化及进化算法。
MuJoCo Tasks:应用 LA-MCTS 在机器人,强化学习,并可视化你学出来的策略。
王林楠是布朗大学第四年博士生,他的研究方向为人工智能和超级计算。他的目标就是让人工智能全民化,能够让任何人,任何公司只需要点击几次鼠标就能设计,部署一个可行的人工智能系统。为了实现这个目标,他一直致力于建立一个基于蒙特卡洛树搜索的人工智能,来设计不同的人工智能给大众。通过四年的努力,他们已经围绕蒙特卡洛树搜索建立了一个完整的神经网络结构搜索系统去实现这个目标。
田渊栋博士,脸书(Facebook)人工智能研究院研究员及经理,研究方向为深度强化学习,多智能体学习,及其在游戏中的应用,和深度学习模型的理论分析。围棋开源项目 DarkForest 及 ELF OpenGo 项目中研究及工程负责人和第一作者。2013-2014 年在 Google 无人驾驶团队任软件工程师。2005 年及 08 年于上海交通大学获本硕学位,2013 年于美国卡耐基梅隆大学机器人研究所获博士学位。曾获得 2013 年国际计算机视觉大会(ICCV)马尔奖提名(Marr Prize Honorable Mentions)。
[1] Neural Architecture Search using Deep Neural Networks and Monte Carlo Tree Search, AAAI-2020.
[2] Sample-Efficient Neural Architecture Search by Learning Action Space, 2019
[3] Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search, NeurIPS 2020.
[4] Optimistic optimization of a deterministic function without the knowledge of its smoothness, NeurIPS 2011.
[5] Batched Large-scale Bayesian Optimization in High-dimensional Spaces, AISTATS 2018.
[6] Heteroscedastic Treed Bayesian Optimisation, 2014.
[7] Monte Carlo Tree Search in continuous spaces using Voronoi optimistic optimization with regret bounds, AAAI-2020.
[8] Bock: Bayesian optimization with cylindrical kernels
[9] Correcting boundary over-exploration deficiencies in Bayesian optimization with virtual derivative sign observations
[10] Solving Black-Box Optimization Challenge via Learning Search Space Partition for Local Bayesian Optimization
[11] Adaptive Local Bayesian Optimization Over Multiple Discrete Variables
© THE END
投稿或寻求报道:content@jiqizhixin.com
以上是关于专栏 | 蒙特卡洛树搜索在黑盒优化和神经网络结构搜索中的应用的主要内容,如果未能解决你的问题,请参考以下文章
golang蒙特卡洛树算法实现五子棋AI
黑盒测试
蒙特卡洛树搜索介绍
强化学习
蒙特卡洛树搜索介绍
蒙特卡洛树搜索介绍
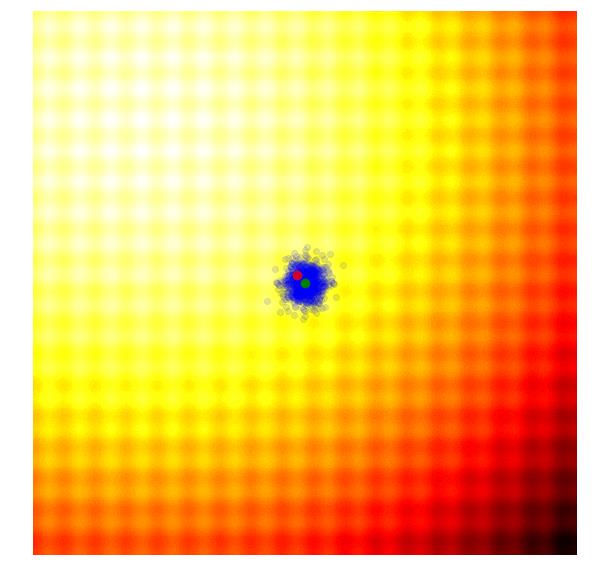
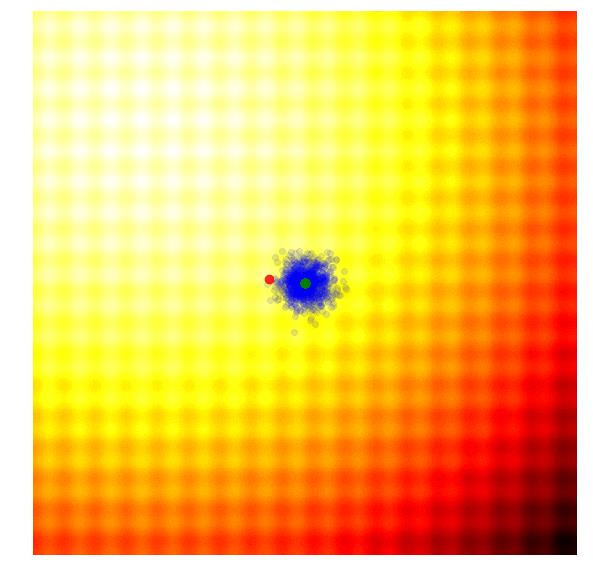
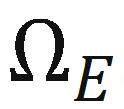 。然后,我们只在这个子空间上进行贝叶斯优化即可。
。然后,我们只在这个子空间上进行贝叶斯优化即可。