神经网络中的Attention-3.为机器翻译Seq2Seq准备数据
Posted DataSea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络中的Attention-3.为机器翻译Seq2Seq准备数据相关的知识,希望对你有一定的参考价值。
在上一篇文章中,我们首先研究了Sequence-to-Sequence(Seq2Seq)。在这篇文章中,在用Python实现Seq2Seq模型之前,让我们看看如何为神经机器翻译准备数据。
问题-神经机器翻译
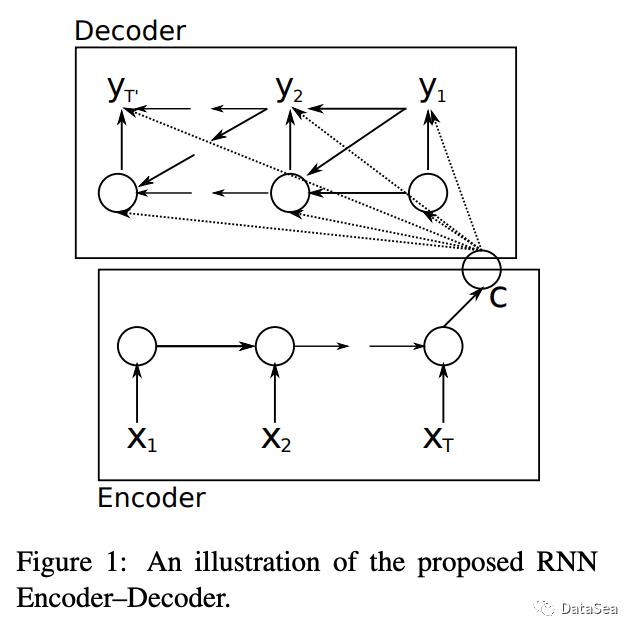
机器翻译的任务是将一种语言(如法语)的句子自动转换成另一种语言(如英语)的句子。我们要转换的句子(词)通常称为源句(词)。被转换成的句子(词)就是目标句子(词)。下面的图表展示了从法语到英语的翻译,第一个源词是“On”、“y”和“va”,而目标词是“Let’s”和“go”。
神经机器翻译是机器翻译的一个分支,它积极地利用神经网络,如循环神经网络和多层感知器,来预测语料库中可能出现的单词序列的可能性。到目前为止,神经机器翻译已经更成功地解决了机器翻译中的问题,这些问题已经在之前的文章中概述过了。
许多早期具有开创性的神经机器翻译研究都采用了Seq2Seq架构,例如Cho et al. (2014)。在这篇文章中,让我们看看如何为Python的神经机器翻译准备数据。
数据集
本帖使用的数据集是从这里下载的英语-德语句子对数据集。它们不仅提供与英语对应的德语句子,还提供法语、阿拉伯语和汉语等其他语言的句子。所以如果你想尝试翻译其他语言,请查看网站!
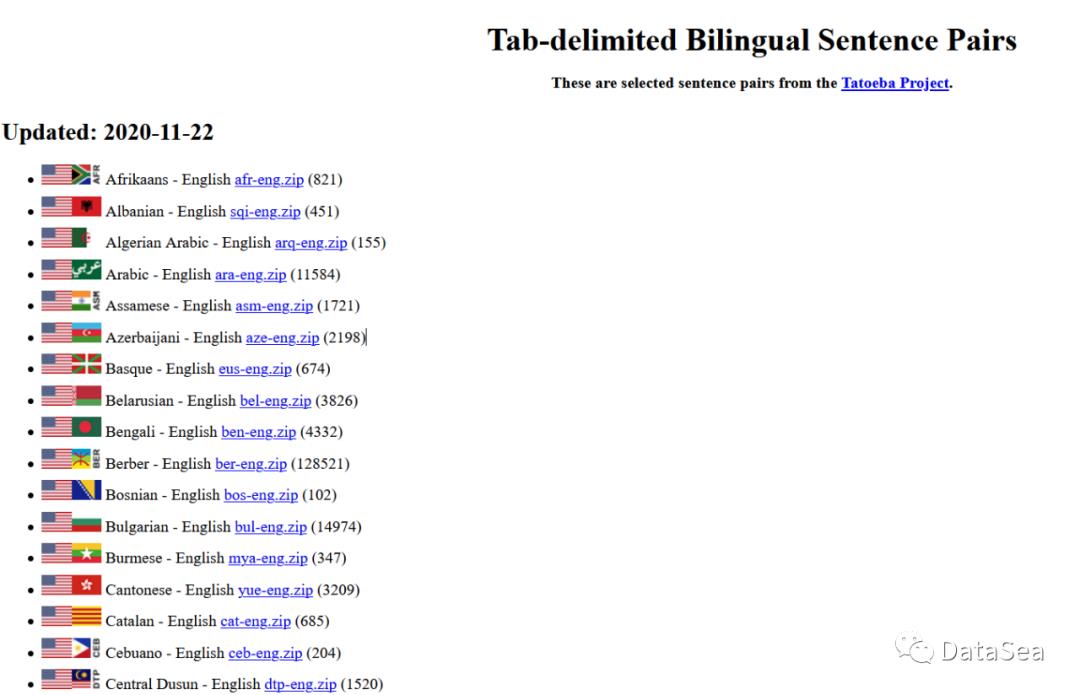
数据以TAB分隔,每一行包含英语句子+ TAB +另一种语言句子+ TAB+属性。因此,我们可以从每一行中提取(英语句子,另一个语言句子),同时用TAB(“\t”)分隔每行。

让我们从导入必要的包开始。请在自己的Conda环境中安装Pytorch等科学计算包后,导入它们。
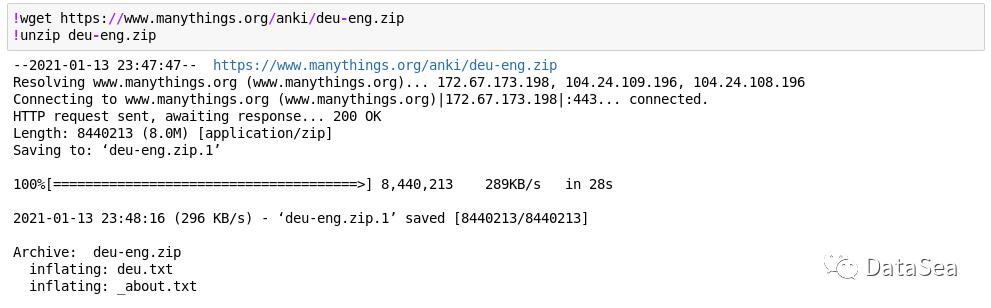
下载&读取数据
让我们先下载并解压缩数据集。您还可以在您的机器上手动下载并解压缩它们。如果成功下载并解压缩了文件,您将得到以下输出。
Anaconda环境中如下:
Linux环境如下:
下载文件后,我们可以打开文件并读取它们。我更喜欢用readlines()函数读取txt文件,但是您也可以用read()函数尝试一下。

存储数据的列表长度为224,420。换句话说,总共有224,420个英德语句子对。
预处理
每个数据集都需要预处理,尤其是像文本这样的非结构化数据。为了使所涉及的时间和计算成本最小化,我们将随机选择50,000对进行模型训练。然后,我们将只保留字母字符并对句子进行标记。同样,字母将被更改为小写字母,并且将在单独的集合中提取唯一的标记。另外,我们在句子的开始和结束处添加了“句子的开始”(“<sos>”)和“句子的结束”(<eos>) token。这将让机器检测每个句子的头和尾。
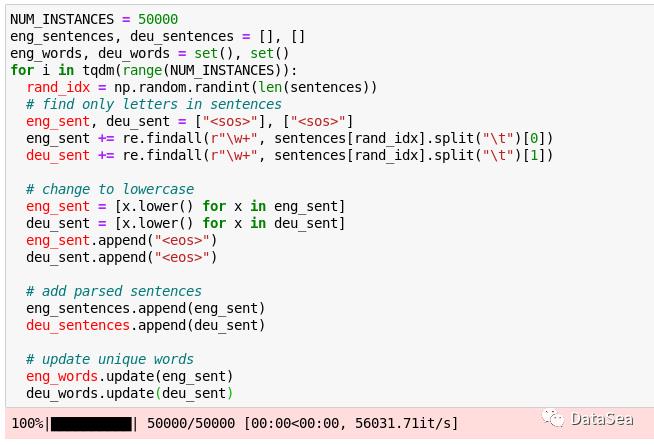
所以,现在我们有5万个随机选择的英语和德语句子,它们与相应的索引配对。为了获得标记的索引,让我们将唯一的标记集转换为列表。然后,为了进行完整性检查,让我们打印出语料库中英语和德语词汇的大小。
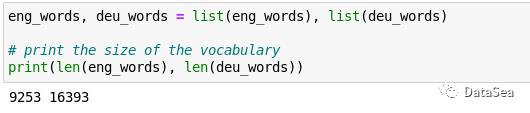
有9,253个独特的英语符号和16,393个德语符号。有趣的是,德语中的记号大约是英语的两倍。
最后,让我们把每个句子中的单词转换成索引。这将使信息更容易被机器理解。这些被编入索引的句子将作为已实现的神经网络模型的输入。
现在,我们已经完成了导入和预处理英语-德语数据的工作。为了进行最后的完整性检查,让我们尝试打印出编码的和原始的句子。请注意,我们从语料库中随机选择了50,000个句子,所以所选择的句子在你这边可能是不同的。
在这篇文章中,我们介绍了Seq2Seq及其整体架构。在下一篇文章中,我将使用Pytorch实现Seq2Seq模型,并展示如何用预处理数据训练它。感谢您的阅读。
以上是关于神经网络中的Attention-3.为机器翻译Seq2Seq准备数据的主要内容,如果未能解决你的问题,请参考以下文章