人工智能之卷积神经网络
Posted 峰哥话技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能之卷积神经网络相关的知识,希望对你有一定的参考价值。
概述
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和无监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求。
目前在图片分类、图片检索、目标检测、目标分割、目标跟踪、视频分类等图像视频相关领域中已有很多成功的应用。
卷积神经网络基础
如下图所示,一个典型的CNN通常由CONV(卷积层)、RELU、POOLING(池化层)、FC(全连接)等模块组成。
卷积层
卷积层保留了输入图像的空间特征,即对于一张32*32*3的图片而言,卷积层的输入32*32*3的矩阵,不需要任何改变。卷积层中比较重要的是模块是卷积核(kernel)、步长(stride)和填充(padding)。
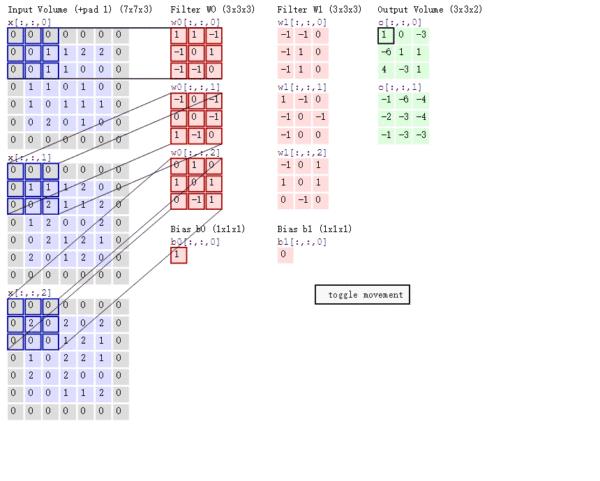
卷积核(kernel) :让卷积核在input image上依次进行滑动,滑动方向从左到右,从上到下;每滑动一次,卷积核就与其滑窗位置对应的input image做一次点积计算并得到计算结果。
步长(stride): 卷积在输入图片上移动时需要移动的像素数.
填充(padding):可以在进行卷积操作前,对原矩阵进行边界填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常都用“[公式]”来进行填充的。
举一个例子来说明上述的概念,在7*7输入图片上做一个1像素的填充(padding),步长(stride)为1,卷积核(kernel)3*3,卷积输出的特征层(feature map)为7*7。W1*H1*D1为输入图片宽、高和通道,F为kernel的大小,步长为S,填充为P;经过一次卷积后等到的结果为W2*H2*D2。
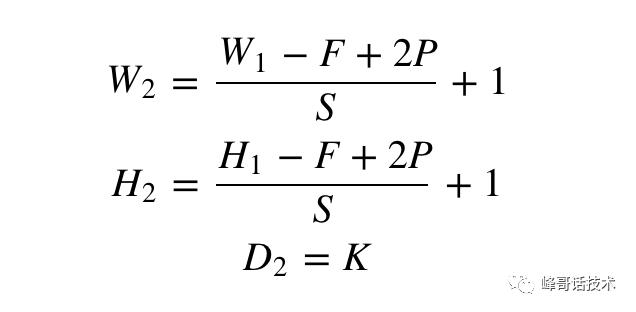
然后再经过RELU等激活函数激活后的结果通常称为Feature Map
池化层
池化层是对图片进行压缩的一种方法,池化层有max pooling,average pooling等。池化层一般对卷积之后的Feature Map进行池化,使得图片进行压缩。
我们假设输入W1xH1xD1为输入图片宽、高和通道,F为池化kernel的大小,步长为S,填充为P;经过一次池化操作后等到的结果为W2xH2xD2。
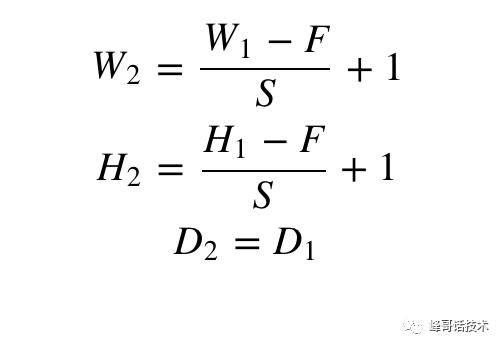
全连接层
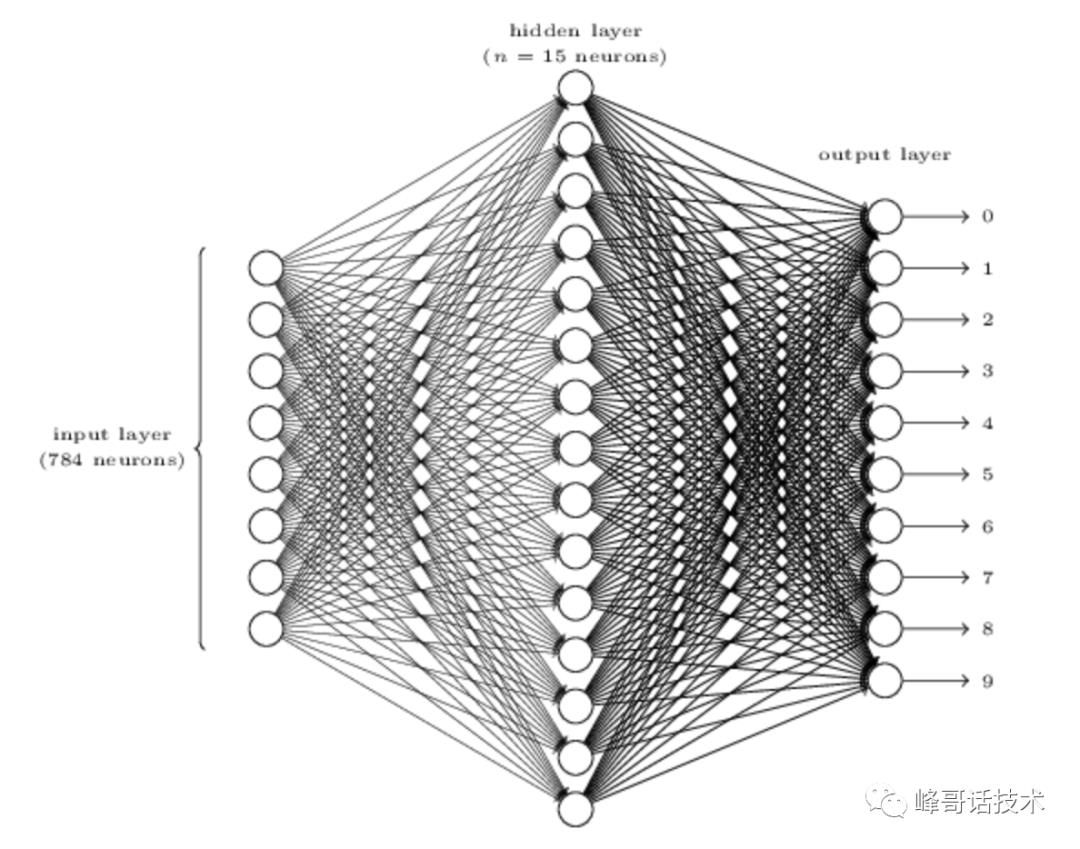
全连接层可以理解为神经网络的隐藏层,它包含权重和激活函数。如下图所示:
批规范化处理
BN(BatchNorm)主要是为了加速神经网络的收敛过程以及提高训练过程中的稳定性。可以理解为对Batch的图片进行前向计算,误差也是将该batch图片的所有误差累计起来一起回传,其归一化为:
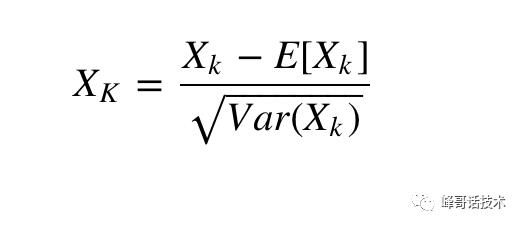
CNN结构
CNN结构有很多,AlexNet、VGGNet、GoogLeNet和ResNet等,这篇博客我们主要了解一下VggNet,如果熟悉VggNet其它的神经网络也很容易上手和理解。
VGGNet
VGGNet包含两种结构,分别为16层和19层,所有卷积层的kernel都只有3x3。VGGNet中连续使用3组3x3kernel(stride=1)的原因是与使用7x7kernel产生的效果相同,更深层次的网络结构不仅学习网络效果更好,而且会减少参数数量。对于一个C个kernel的卷积层来说,原来的参数为7x7xC,而新的参数为3x(3x3xC)
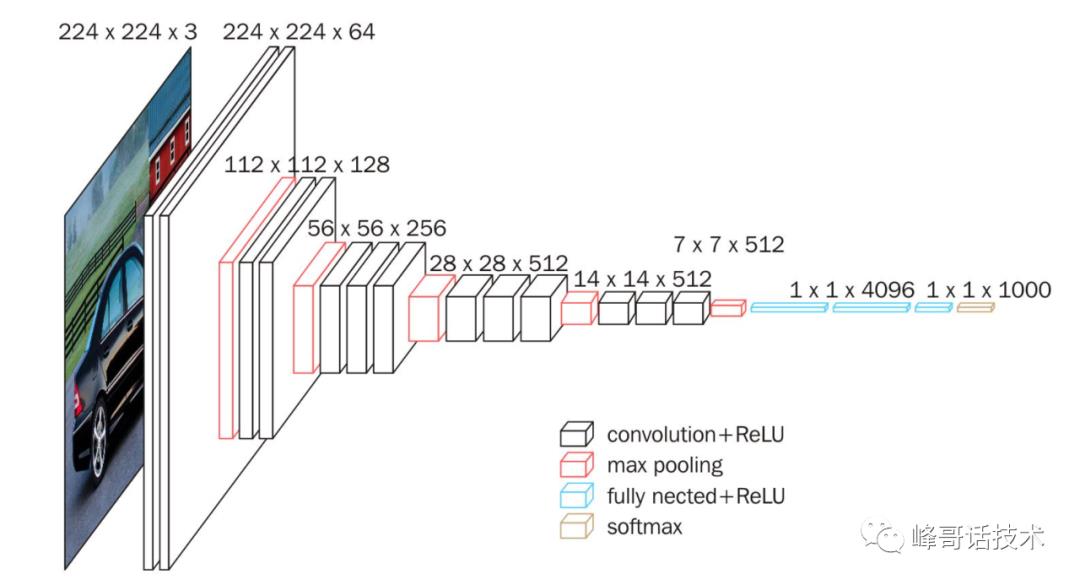
具体网络结构如下图:
VGG实现图像分类
我们使用Vgg16来训练一个图像分类的模型,具体分为如下步骤:
准备数据
构建卷积神经网络
定义损失函数和优化方法并训练保存模型
模型服务发布
1.数据集准备
import torchimport torchvisionimport torchvision.transforms as transforms#数据预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])train_dataset = torchvision.datasets.CIFAR10(trian=True,transform=transform)test_dataset = torchvision.datasets.CIFAR10(trian=False,transform=transform)trian_loader = torch.utils.data.DataLoader(train_dataset,batch_size=16,shuffle=True,num_workers=4)trian_loader = torch.utils.data.DataLoader(test_dataset,batch_size=16,shuffle=False,num_workers=4)classes=('plane','car','bird','deer','cat','dog','frog','horse','ship','truck')
2.构建卷积神经网络
config = {'VGG16':[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M']}class VGGModel(nn.Model):def __init__(self,net_name):super(VGGModel,self).__init__()self.features = self.layers(config[net_name])self.clssifier = nn.Sequential(nn.Dropout(),nn.Linear(512,512)nn.Relu(True),nn.Dropout(),nn.Linear(512,512),nn.Relu(True),nn.Linear(512,10),)for model in self.modules():if isinstance(model,nn.Conv2d):n = model.kernel_size[0]*model.kernel_size[1]*model.out_channelsmodel.weight.data.normal_(0,math.sqrt(2./n))model.bias.data.zero_()def forward(self,x):x = self.features(x)x = x.view(x.size(0),-1)x = self.clssifier(x)return xdef layers(self,config):in_channels = 3in_layers = []for value in config:if value == 'M':in_layers +=[nn.MaxPool2d(kernel_size=2,stride=2)]else:in_layers +=[nn.Conv2d(in_channels,kernel_size=3,stride=1),nn.BatchNorm2d(value),nn.ReLU(inplace=True)]in_channels=Truenet = VGGModel("VGG16")
3.定义损失函数和优化方法并训练保存模型
max_epoch = 128#定义损失函数cross_loss = nn.CrossEntropyLoss()#定义优化方法optimizer = optim.SGD(net.parameters(),lr=0.0001,momentum=0.9)for epoch in range(max_epoch):train_loss = 0.0for index,data in enumerate(trian_loader,0):inputs,labels = dataoptimizer.zero_grad()outputs = net(inputs)loss = cross_loss(outputs,labels)loss.backward()optimizer.step()train_loss+=loss.item()if index % 2000 == 1999:print(train_loss)print("Saving epoch %d model" % (epoch+1))state = {"net":net.state_dict(),'epoch':epoch+1}torch.save(state,"epoch_{0}.ckpt".format(epoch+1))
4.模型服务发布
分类模型预测和评估是将自己训练好的模型对测试数据集进行准确率评估和测试。选取模型后会对所选择的模型服务发布,其中端对端的深度学习模型服务发布最常用的一种方式采用Restful API。
总结
现在大多数图像和视频的算法,基本上都会使用或者涉及到卷积神经网络,VGGNet卷积神经网络的结构更像积木一样,构建自己的视觉分析模型。当然在实际工业部署和使用过程中会有很多优化技巧和服务集成,后面的文章会重点介绍。
以上是关于人工智能之卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章