大数据篇-使用SQOOP导入导出数据
Posted 第七行代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据篇-使用SQOOP导入导出数据相关的知识,希望对你有一定的参考价值。
最近忙着找房子搬家、又换工作等等好久没有更新文章了(其实也是偷懒了好久了),抱歉抱歉,今天就接着上篇文章再继续更新吧,我们使用sqoop来进行数据的导入导出。
一、mysql数据准备
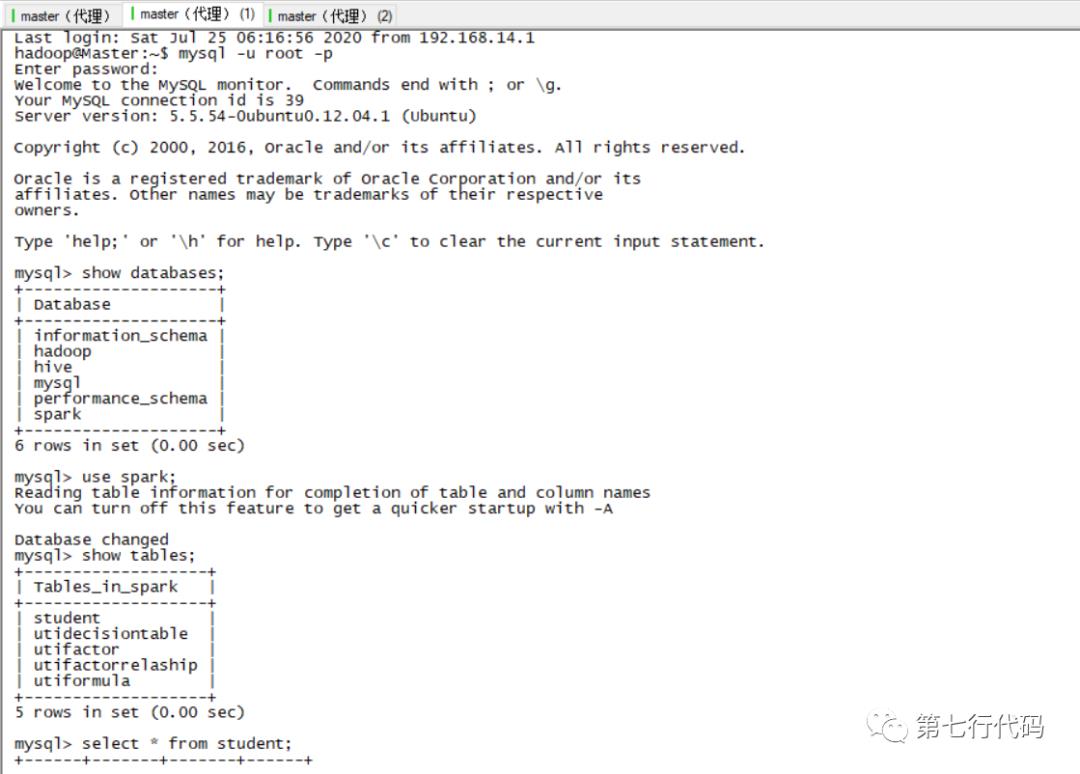
(1) 首先准备数据,使用如下命令登录mysql数据库,并查看表中数据。
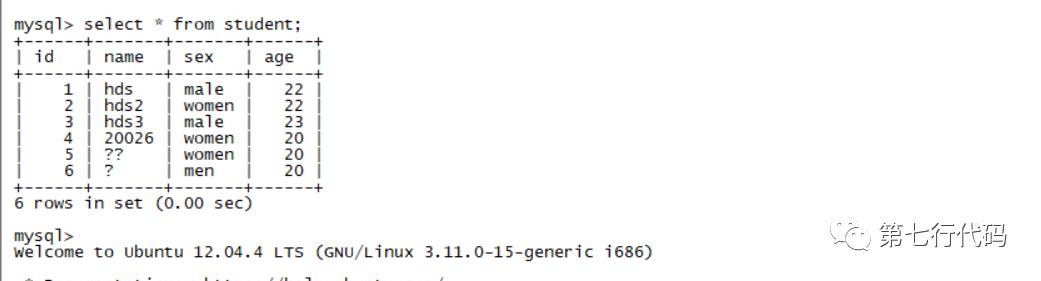
mysql -u root -p # 然后输入正确密码以登录数据库show databases; # 显示所有库use spark; # 使用名为spark的库show tables; # 显示所有表select * from student; # 查看表中所有数据
二、sqoop导入mysql数据到HDFS中
(2) 将表中数据导入到HDFS中
执行以下命令将筛选表中数据导入到hdfs中。
cd /usr/local/sqoop #跳转到sqoop目录./bin/sqoop import \--connect jdbc:mysql://Master:3306/spark \--username root \--password xxxxxx \--target-dir /tmp/sqoop/student \--query 'select id,name from student WHERE id>1 and $CONDITIONS' \--split-by id \--fields-terminated-by ',' \--m 1
关键点说明:
1、sqoop import 是使用sqoop进行导入的关键字
2、使用 \ 可以将命令换行,而不是执行命令,提升可读性
4、username、password是用户名、密码
5、target-dir 是代表导出到hdfs的哪个目录下,不用手动创建,导入时会自动创建
6、query 是筛选数据的sql,注意sql后边一定要有 and $CONDITIONS ,相当于1=1
7、split-by id 代表根据哪个字段进行分区,如设置split-by id 和m 10,sqoop会查该表id字段的最大值和最小值,然后分成10份,最好10个并行的maptask去查数据库。
8、fields-terminated-by ',' 代表导出到hdfs的文件中以 ,分割各个字段
9、m 1 设置之后代表只会启动一个maptask执行数据导入,不设置m 1默认会启动4个maptask执行数据导入
(3) 执行命令如下所示,可以看到实际执行的是mapreduce任务
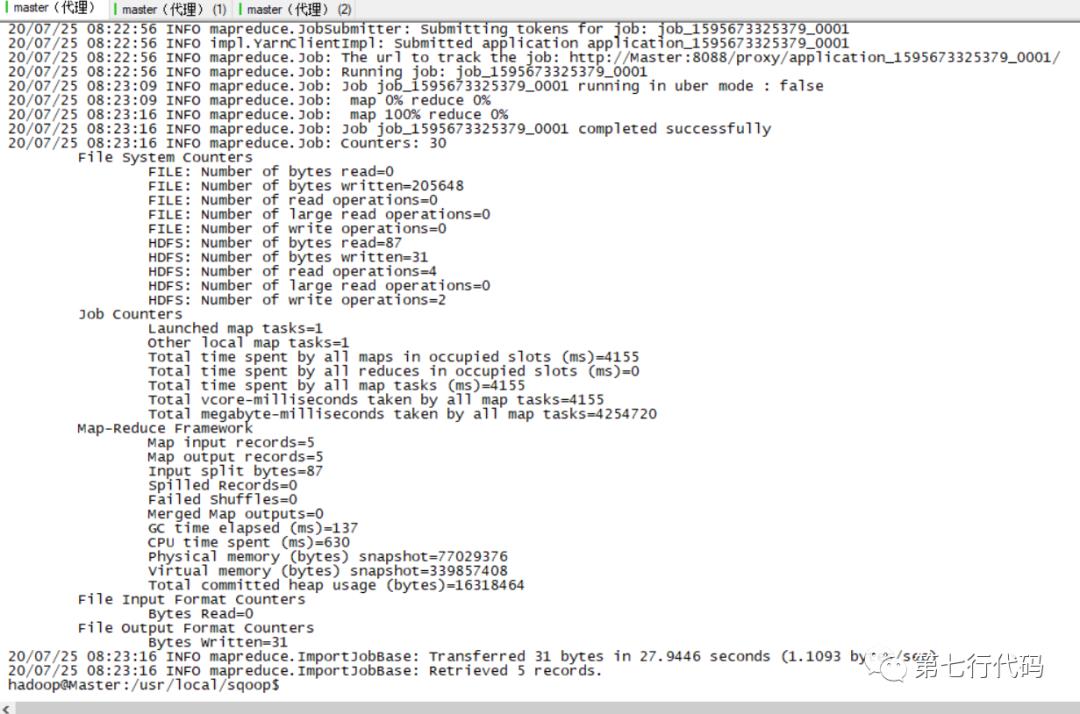
(4) 查看hdfs上对应文件内容,可验证执行结果,如下图所示:
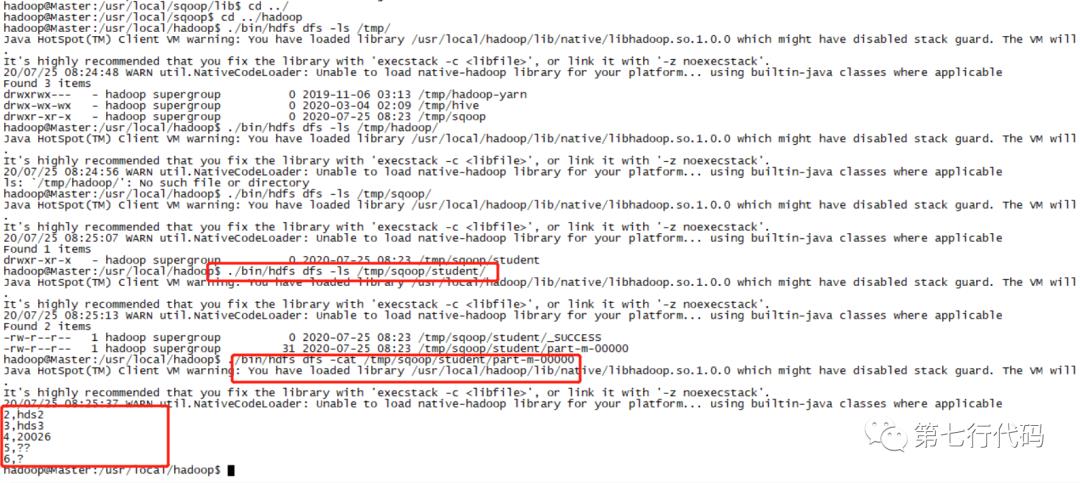
三、sqoop将mysql数据导入Hive
导入Hive和导入HDFS是差不多的,其实就是先将数据导入HDFS的临时目录,后调用hive元数据操作API接口,执行建表、将数据从临时目录导入到hive目录的操作。执行以下命令:
./bin/sqoop import \--connect "jdbc:mysql://Master:3306/spark" \--username root \--password hadoop \--hive-import \--fields-terminated-by '\t' \--table student \--split-by id \--m 2
如下图所示:
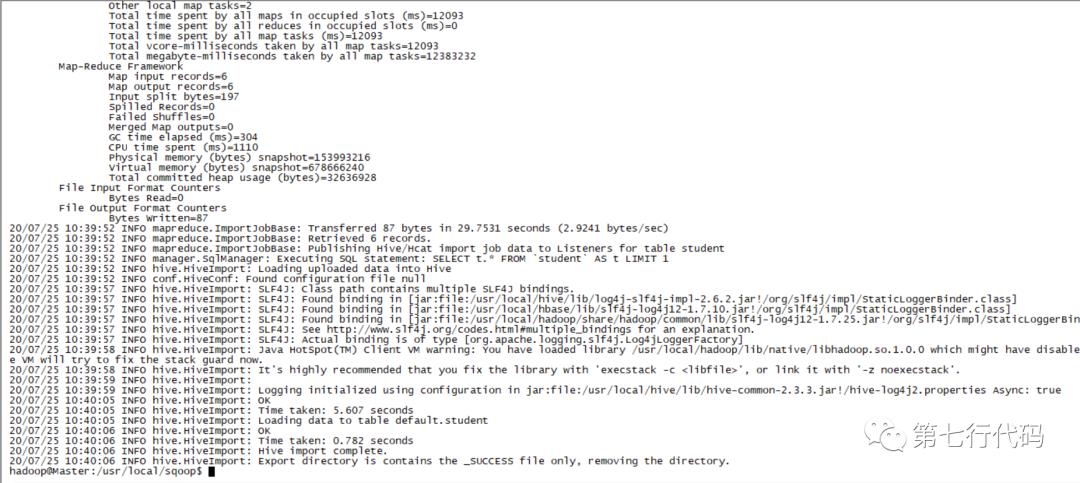
然后我们打开Hive命令行,去查看下Hive中数据是否正常,输入“hive”,进入交互窗口,输入show tables,可以看到已经有student这种表了,然后查询其中数据,如下图所示:
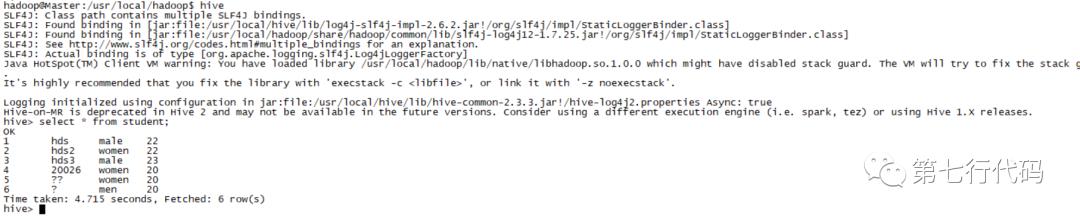
注:如果导出到hive中,查询数据发现全是null时,应该是由于你命令中的分隔符填的不对,hive无法分割数据存储,一开始我是使用的 , 作为分隔符导致数据都是null,然后把表删掉,使用 ‘\t’ 作为分割符重新导入,数据正常显示。
ok,使用sqoop将数据由关系型数据库导出到HDFS、Hive就演示完了,其实还可以向Hbase等非关系型数据库导出,我就不一一演示了,今天太晚了,就先到这里吧,明天再为大家分享数据由非关系型数据库向关系型数据库导入的过程,大家晚安、晚安!
你的每个“在看”都好令人心动
以上是关于大数据篇-使用SQOOP导入导出数据的主要内容,如果未能解决你的问题,请参考以下文章