技多不压身——从一个编译器的"bug"谈起
Posted 算法与数学之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技多不压身——从一个编译器的"bug"谈起相关的知识,希望对你有一定的参考价值。
技多不压身——从一个编译器的"bug"谈起
来源: 南慕伦
编辑:Gemini
一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的进程。人生往往有很多机会是超乎预料的,今天想着要去当教授,明天说不定就要被请去当教皇了。所以啊,技多不压身,不管在哪一个行业,多学一个技能,指不定什么时候就能派上用场。
你说我一个学机器学习的,怎么就跑来做数据库了呢?下面分享一段有趣的个人经历。
前两天公司里测试发现了一个bug,“尸检”(postmortem)之后同事发了封邮件分享了这个有趣的GCC "bug":

这段代码其实是把64位有符号整型转换成无符号整型,并与无符号整型数2相比较。
在GCC4.9以及更高的版本(可在Ubuntu 16.04上测试,或使用gcc -v查看编译器版本)不加任何优化的时候,其输出结果是:
test@instance-3 /tmp/gcc $ g++ test.cpp -o test && ./test value 9223372036854775808 compare correct然而,加了最常用的-O2优化参数之后,结果却不对了:
test@instance-3 /tmp/gcc $ g++ test.cpp -o test -O2 && ./test value 9223372036854775808 less than 2?!更有趣的是,同事发现,当给ABSTest加上inline关键字,或者把该函数的第一行改为:
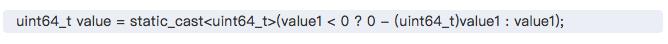
输出结果又是对的。
于是大牛认为这是gcc的bug,虽然修正的方法有点奇怪,但是编译器不是自己写的也没办法。遂记录下来给所有工程师分享讨论。
我看到这个问题也觉得很有意思,因为。
好在我旦计算机教学的体系比较完善,本科课程从模拟电路到操作系统整个体系都涉及,虽然学得不是太好,但是整个体系结构的大致理解还是可以的,加之当年计算机体系结构直接引入了CMU的教材:《》,拆过二进制炸弹,所以看这种级别程序的汇编代码问题不大,所以我决定深入研究一下造成这个bug的原因,或许可以提交个报告。
测试了一下,我发现这个bug在加编译参数-O1的时候并没有出现,考虑到不加优化的汇编代码差异比较大,不好直接比较,于是我直接直接用编译器加-O1和-O2生成的汇编代码来进行比较。汇编语言,但是有个大致了解非常简单,比C++的原理简单得多,《深入理解计算机系统》那本书讲得非常透彻。
对编译器gcc,使用-S参数可直接生成汇编代码。
g++ test.cpp -O2 -S -o test.S这样打开test.S可以直接看到汇编代码,我仅截取有用的部分进行讨论。
-O1
sarq $63, %rax movq %rdi, %rbx xorq %rax, %rbx subq %rax, %rbx movl $6, %edx movl $.LC0, %esi movl $_ZSt4cout, %edi call _ZSt16__ostream_insertIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_PKS3_l movq %rbx, %rsi movl $_ZSt4cout, %edi call _ZNSo9_M_insertImEERSoT_ cmpq $1, %rbx ja .L2-O2
sarq $63, %rax movl $6, %edx movl $.LC0, %esi xorq %rax, %rbx movl $_ZSt4cout, %edi subq %rax, %rbx call _ZSt16__ostream_insertIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_PKS3_l movq %rbx, %rsi movl $_ZSt4cout, %edi call _ZNSo9_M_insertImEERSoT_ cmpq $1, %rbx jle .L5注意到两段代码其实非常相似,只有最后一句有差异,一个是JA(无符号跳转),另一个JLE(有符号跳转)。
乍一看似乎的确是gcc的bug。稍微有一些C++编程经验的程序员应该了解-O1和-O2的区别只在于O2多了一些优化选项。为了搞清楚更深层次的原因,需要进一步确定是哪些优化选项导致的。在gcc的文档页面可以看到各种优化选项:
这样我们一下子就把范围缩小到了37个优化选项,我们只需要确定是哪个选项导致的这个问题。怎么最快找到这题图书馆管理员大妈都能做,我就不说了。
最后锁定下来,竟然是两个选项同时开启才会造成的:
-ftree-vrp 和 -fstrict-overflow
这下就有意思了,先看看ftree-vrp:
-ftree-vrp
Perform Value Range Propagation on trees. This is similar to the constant propagation pass, but instead of values, ranges of values are propagated. This allows the optimizers to remove unnecessary range checks like array bound checks and null pointer checks. This is enabled by default at -O2 and higher. Null pointer check elimination is only done if -fdelete-null-pointer-checks is enabled.
来源:
这个优化的主要思想是,在编译过程中,如果一个变量能够知道他的最大和最小值,如果之后再出现相应的类型检查,就可以将其删除。
比如说下面这段代码():
for (i = 1; i < 100; i++)
{ if (i) g ();
}在编译过程中就可以明确知道,i 的范围是[1, 100]的整型,所以if(i)这个条件永远为真,就可以优化掉,变成:
for (i = 1; i < 100; i++)
{ g ();
} 这个优化其实非常合理,一时半会儿也看不出什么问题。那么再来看下一个:
-fstrict-overflow
Allow the compiler to assume strict signed overflow rules, depending on the language being compiled. For C (and C++) this means that overflow when doing arithmetic with signed numbers is undefined, which means that the compiler may assume that it does not happen. This permits various optimizations. For example, the compiler assumes that an expression like i + 10 > i is always true for signed i. This assumption is only valid if signed overflow is undefined, as the expression is false if i + 10 overflows when using twos complement arithmetic. When this option is in effect any attempt to determine whether an operation on signed numbers overflows must be written carefully to not actually involve overflow.
This option also allows the compiler to assume strict pointer semantics: given a pointer to an object, if adding an offset to that pointer does not produce a pointer to the same object, the addition is undefined. This permits the compiler to conclude that p + u > p is always true for a pointer p and unsigned integer u. This assumption is only valid because pointer wraparound is undefined, as the expression is false if p + uoverflows using twos complement arithmetic.
See also the -fwrapv option. Using -fwrapv means that integer signed overflow is fully defined: it wraps. When -fwrapv is used, there is no difference between -fstrict-overflow and -fno-strict-overflowfor integers. With -fwrapv certain types of overflow are permitted. For example, if the compiler gets an overflow when doing arithmetic on constants, the overflowed value can still be used with -fwrapv, but not otherwise.
The -fstrict-overflow option is enabled at levels -O2, -O3, -Os.
来源:
说实话,看到前两句话,我的内心是非常激动的:这不是一个bug,而是一个feature!该优化假设计算不存在有符号整型的溢出,否则是未定义行为(未定义行为指的是编译器想干嘛就干嘛,所以结果不一定总是错的,也可能是对的,优化怎么强大怎么来)!那一切都有了合理的解释:
首先,value1是定义了64位整型的最小值,也就是 . 当对value1 进行0-value1计算的时候,发生了溢出。
. 当对value1 进行0-value1计算的时候,发生了溢出。
然后,由于两个编译选项是-O2默认开启的,所以编译过程编译器假设value1不会溢出,编译器直接进行了优化,由于value是无符号整型,要跟2比较大小,在JLE和JA都可以用的情况下,JLE由于某种原因被选中了,所以就出现了诡异的结果。
他给的两个修改方法,加上inline那个能够得出正确结果,估计是纯粹是偶然,编译器恰好没选择导致出错的JLE,而选择了JA,这估计跟具体的优化策略有关。换一个编译器版本或者平台估计还是会出错。
而加unsigned也是错误的。有符号整型强制转换成无符号整型的时候,无论正数负数都是保留所有二进制位不变:
"If the destination type is unsigned, the resulting value is the least unsigned integer congruent to the source integer (modulo 2^n where n is the number of bits used to represent the unsigned type). [ Note: In a two’s complement representation, this conversion is conceptual and there is no change in the bit pattern (if there is no truncation). —end note ]
来源:
同事的本意是取绝对值,但是由于正数的最大值比负数的最小值绝对值小1,这种情况下同样长度的有符号整型是没办法表示的。同事期望的表现是在这种情况下,直接变成无符号整型,这样就能够表示了。这样看似乎这样做是可以的,但是别忘了,大部分计算机表示负数是用补码,比如1字节有符号整型有8位,它的-1是1111 1111,如果直接这样转换成无符号整型,就变成了1+2+4+8+16+32+64+128 = 255,这显然不是取绝对值操作。
下面来考虑怎么解决这个问题。
如果学过汇编语言,这题其实很简单。那段C++代码,能够造成溢出的只有那一个值。所以,在初始化的时候将其改成std::numeric_limits<int64_t>::min() + 1就可以避免溢出。这是一种改法,当然这样改并不好,原因在于当其它程序员在用同样的方法做事情的时候,会导致同样的错误。
去掉那两个flag中的任意一个吗?这显然也不好。因为我们公司是做数据库的,代码性能异常重要,这两个优化很多时候还是效果非常明显。
读了一下文档,我发现有两个选择:
打开编译器警告。在编译选项中加上 -Wstrict-overflow=2 即可出现报警:

加上-fwrapv选项。这个选项我是从上文中-fstrict-overflow看到的,它定义了溢出时候编译器的行为——采用二补码的方式进行操作:
-fwrapv
This option instructs the compiler to assume that signed arithmetic overflow of addition, subtraction and multiplication wraps around using twos-complement representation. This flag enables some optimizations and disables others. This option is enabled by default for the Java front-end, as required by the Java language specification.
来源:
文档写这么详细,肯定是有人踩过同样的坑。但是,做这么强的假设,应该直接丢警告才对啊!
除了解决方法,我还给同事提了一条建议:仔细阅读所有编译选项,看看有没有类似的强假设。
总结
这不是一个bug,而是一个feature
C++程序员非常有必要了解编译器的原理,读编译器文档,知道编译器在做各种优化时候所做的假设
GCC文档上比LLVM完善不少,所以如果考虑整体迁移到LLVM,虽然好处不少,但是文档不全这方面需要慎重考虑
虽然现代软件工程强调解耦、模块化,试图把不同的层级分隔开,让每一层的程序员只专注于自己的那一层。但是毕竟软件是人来写的,有人的地方不可避免的有人为失误(bug),很多时候会遇到像本文这样的bug,牵涉到下一层的东西。所以,要想成为一个优秀的软件工程师,需要对从上到下的体系结构都有一定了解。这一点,复旦计算机学院的课程设计就很好,赵一鸣院长就说,培养的学生要建立从基本电路,到制作CPU,到计算机体系结构,设计编译器、操作系统的全方面知识体系。虽然在教学上跟美国顶尖大学比仍有非常大的差距,但是总体教学设计思路仍然让我收益颇丰。
思考题
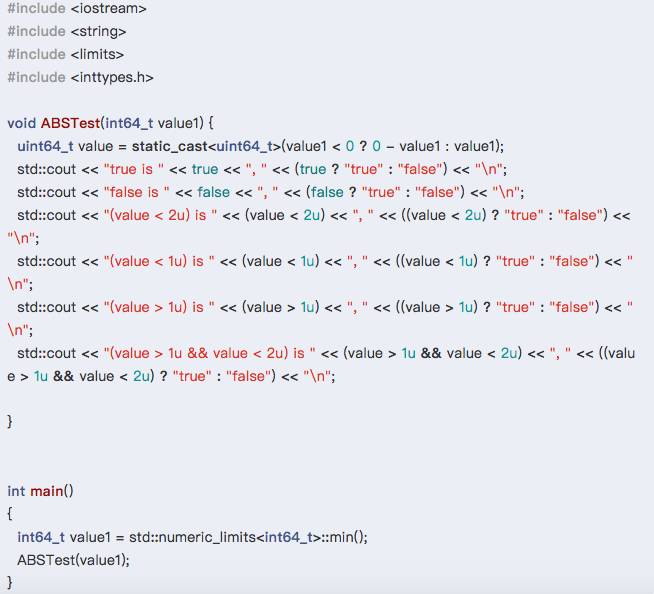
1、上文中所说的代码是由于编译器的优化导致的不确定行为,按照上述解释,同样的值传入同样的函数,结果应该相同。解释下列代码运行结果出现的原因(提示:原因非常有趣!)
代码
#include <iostream>#include <string>#include <limits>#include <inttypes.h>size_t test(int64_t value1) { uint64_t value = static_cast<uint64_t>(value1 < 0 ? 0 - value1 : value1); if (value < (((uint64_t)1) << 6)) return 1; if (value < (((uint64_t)1) << 13)) return 2; if (value < (((uint64_t)1) << 20)) return 3; if (value < (((uint64_t)1) << 27)) return 4; if (value < (((uint64_t)1) << 34)) return 5; if (value < (((uint64_t)1) << 41)) return 6; if (value < (((uint64_t)1) << 48)) return 7; if (value < (((uint64_t)1) << 55)) return 8; if (value < (((uint64_t)1) << 62)) return 9; return 10;}int main(){ { int64_t test2 = std::numeric_limits<int64_t>::max(); std::cout << "1: " << test(test2) << "\n"; } { uint64_t test1 = (((uint64_t)1) << ((10 - 1) * 7)); uint64_t test2 = std::numeric_limits<uint64_t>::max(); test(test1); std::cout << "2: " << test(test2) << "\n"; } return 0;} 运行结果
test@instance-3 /tmp/gcc $ g++ test1.cpp -O2;./a.out 1: 10 2: 1运行环境
test@instance-3 /tmp/gcc $ gcc -v Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/5/lto-wrapper Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 5.4.0-6ubuntu1~16.04.4' --with-bugurl=file:///usr/share/doc/gcc-5/README.Bugs --enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-5 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-5-amd64/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-5-amd64 --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-5-amd64 --with-arch-directory=amd64 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc-gc --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.4)2、在实际的调试过程中,源代码往往比较复杂,包含大量函数调用,直接生成的汇编代码比较难以理解。请用GCC 4.9及以上的编译器比较下列代码在-O1和-O2下的运行结果,并展示简化过程。
拓展阅读
除了Jeff Dean,Linux作者Linus Torvalds也是一个编译器级的存在。不同的是,他个性十分鲜明,不光是警告编译器,他还把gcc的作者骂成“不应该从幼儿园合格毕业”,“头朝下摔到地上导致智商低下的树懒宝宝”,真是个英语十级的骂人高手:
Lookie here, your compiler does some absolutely insane things with the
spilling, including spilling a *constant*. For chrissake, that
compiler shouldn't have been allowed to graduate from kindergarten.
We're talking "sloth that was dropped on the head as a baby" level
retardation levels here:
……
来源:
我感觉这的确是个真的bug,但有意思的是只会发生在x86_64架构上,x64则没问题:,
以上是关于技多不压身——从一个编译器的"bug"谈起的主要内容,如果未能解决你的问题,请参考以下文章