如何实现一个简易编译器
Posted 前端工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何实现一个简易编译器相关的知识,希望对你有一定的参考价值。
| 作者: 微店-孟凡奇
本篇文章的内容是设计一个新语法,并实现能够解析该语法的编译器,将新语法编译成javascript的标准语法,使之能够正常运行在生产环境中。读完这篇文章,再结合自身的实践,大家就能知道该如何写一个小型编译器了。如果对源码感兴趣,请移步这里https://github.com/lucefer/continue-assign-parser 进行查看。
OK,总结一下接下来要做的事情:
语法设计
我们做的第一件事就是设计我们的语法规范,由于我们的新语法是在javascript的规范上进行的扩充,所以,有些语法我们要沿用ECMA的规范。在设计我们的新语法之前,先来看下面这段代码。
var a, b, c =5
a = b = c
显而易见,这段代码的作用是定义三个变量,并为它们赋初始值为5。
但我觉得上面的写法啰嗦,我想像下面这样书写代码,并实现同样的赋值操作。
var a b c = 5
简洁吗?不够简洁?
OK,我们再看下面两段代码,这次我们不再随意以a,b,c的方式命名变量,而是将变量命名语义化。
// javascript语法
var baseSalary, graduateSalary, doctorSalary =1000
baseSalary = graduateSalary = doctorSalary
// 新语法
var baseSalary graduateSalary doctorSalary =1000
可以看到,我们将变量命名语义化之后,后者的代码量减少了很多。但不要高兴的太早哦。因为ECMA规范中并没有这种语法,假如这样书写,非但达不到想要的效果,浏览器或者nodejs引擎会报语法错误。
如果你受不了第一种啰嗦的赋值语法,又特别想用第二种语法,怎么办呢?是的,我们可以实现一个编译器,将第二种语法编译成第一种语法。
在继续讲述之前,为了方便书写,姑且将第二种语法命名为qi语法,qi语法就是我们要实现的语法。
至此,我们的语法设计就结束了。
编译器的实现
在开始实现我们的编译器之前,我们首先得明确编译器长什么样子,由哪几部分构成,工作原理是怎样的。只有了解了这些,我们才知道该如何下手。
为了简单起见,我们对qi语法进行如下约束:
qi语法只能通过var或者let方式进行赋值。
qi语法不能使用ES6的解构赋值。
qi语法只能为变量赋予数字,字符串,null,bool四种基本类型值。即=号右侧只能跟数字、字符串、null、true或者false,不能跟表达式、对象、数组等复杂类型。
做了如上三个约束条件,我们就可以简化编译器的实现了。注意:仅仅是简化,我不会忽略这当中的每一个过程。
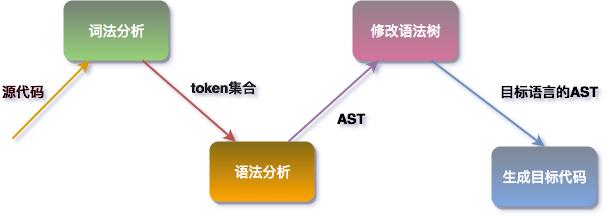
本质上来说,编译器其实也是一个程序,这个程序能够将一种语言(源代码)翻译成另一种语言(目标代码),类似于现实生活中的翻译员。如下图所示:

本文源代码就是符合我们前面设计好的语法规范的代码,目标代码是javascript标准代码。
如何下手
OK,我们接下来要实现一个能够将qi语法翻译为javascript语法的程序,但,从何处着手编码呢?在实际编码之前,我们再花点时间了解一下编译器的内部构造与工作原理,我们可以把编译器看成一个黑盒,从一端输入源代码,另一端输出目标代码。
一个完整的编译器包含如下过程
词法分析
语法分析
语义分析
生成中间代码
编译优化
生成目标代码
为了便于理解,本文所讲的编译器不包含4(生成中间代码)和5(编译优化)的步骤。
首先源代码经过词法分析器(tokenizer)分析,输出线性结构的token单词流。
token经过语法分析器(parser)分析,输出符合qi语法规范的AST(抽象语法树)。
将AST传入语法树遍历器(transformer)输出符合javascript规范的AST。
将生成的符合javascript规范的AST传入代码生成器(generator)构造目标代码。
至此,整个编译流程就结束了。具体流程如下图所示。
为了简单起见,我用下面这段代码作为贯穿全文的示例代码进行分析。
// qi语法
var a b c =100
本文实现的编译器,要能够把上面这段代码,翻译成如下代码。
// javascript语法
var a, b, c =100
a = b = c
另外,还需要声明一点,qi语法的规则也是要遵循javascript语法规范的,我只是在javascript现有语法的基础上衍生一种新的语法。明确了这一点,后续的词法分析和语法分析程序就容易编写了。
词法分析
编译器的第一个阶段就是词法分析,词法分析的作用是将源代码翻译成token集合。源代码实质上是一个字符序列,字符本身粒度太小,直接拿来进行语法分析,复杂度较高。所以我们先分割出一个词法分析器,将字符序列转换成单词集合。拿上面的源代码来说,如果以字符为粒度进行展开,其形式如下:
['v','a','r',' ','a',',',' ','b',' ','c',' ','=',' ','1','0','0']
这种结构我们很难提取出有价值的信息,而我们的词法分析器,则是将上面的字符序列,变成下面的单词序列。
['var',' ','a',' ','b',' ','c',' ','=',' ','100']
很显然,单词序列的可读性更高,我们甚至能够很容易地读出这段代码的意思。
javascript词法规范中包含、保留字、操作符、字面量(字符串,数字,null,bool等)、变量标识符等诸多单词类型,所以我们的词法分析器还应该分析出单词类型。
前面我对qi语法的赋值类型做了一些约束,并且规定qi语法的词法完全遵循javascript的规范,所以qi语法的词法类型有以下几种:
标识符,IDENTIFIER
关键词,KEYWORD
bool字面量,BOOLEAN_LITERAL
null字面量,NULL_LITERAL
数字字面量,NUMBER_LITERAL
字符字面量,STRING_LITERAL
操作符,PUNCTUATOR
换行符,BR
程序结束,EOF
OK,明确了单词类型,我们就可以定义有限自动状态机了,如下:
consttokenType = {
IDENTIFIER:1,
KEYWORD:2,
EOF:3,
NULL_LITERAL:4,
BOOLEAN_LITERAL:5,
PUNCTUATOR:6,
NUMBER_LITERAL:7,
BR:8,
STRING_LITERAL:9
}
module.exports = tokenType
需要注意的是,我们增加换行符的目的,是为了减少变量定义语句的二义性。看下面这段代码,假设我们不增加换行符。
var a b
c =100
// token集合为[ var a b c = 100 ]
var a b c =100
// token集合为[ var a b c = 100 ]
可以看到这两段代码的token集合是一模一样的,但是这两段代码的实际语义却是完全不一样的。
为了能够采用自顶向下的LL(1)的语法分析方式,我们引入换行符BR来消除二义性。
明确了单词类型,我们就可以着手写代码了,词法分析过程不是很复杂,利用前面定义的有限自动状态机即可,所以我不打算贴上全部代码,仅取主要方法讲解一下,如果想看具体实现,点击这里 https://github.com/lucefer/continue-assign-parser/blob/master/src/compiler/tokenizer.js 词法分析器:
functiongetNextToken()
{
letcp, token
if (pos > len) {
return{
type: Type.EOF
}
}
cp = source[pos]
// 判断是否属于标识符的开始字符,若是,就先进行标识符的扫描
if (isIdStart(cp)) {
token = scanId()
returntoken
}
// 判断是否是操作符,若是,进行操作符的扫描
if (cp === '(' || cp === ')' || cp === ';' || cp === ',') {
token = scanPuntuator()
returntoken
}
// 判断是否是单双引号,若是,进行字符串的扫描
if (cp === '"' || cp === '\'') {
token = scanStringLiteral()
returntoken
}
// 判断是否是点号,若是,先判断接下来的字符是否属于数字,若是,则进行数字扫描,如若不是,进行操作符的扫描
if (cp === ".") {
if (isDecimalDigit(source[pos + 1])) {
returnscanNumberLiteral()
}
returnscanPuntuator()
}
// 判断当前字符是否是数字,若是,进行数字的扫描。
if (isDecimalDigit(cp)) {
returnscanNumberLiteral()
}
// 以上情况都不符合,进行操作符的扫描
returnscanPuntuator()
}
上面这段代码经过词法分析器分析之后,得到下面这种线性结构的数据。

至此,我们的词法分析阶段结束,开始下一步的语法分析。
语法分析
经过词法分析,我们得到了可读性较高的token集合,接下来开始语法分析,语法分析阶段主要做两件事:
语义分析
我们在语法树构建过程的同时,会对源程序进行语义分析,由于我们的语法比较简单,仅仅是变量定义,不会涉及变量类型检测,所以语义分析仅仅是简单的单词类型检测。
生成抽象语法树(AST)
先来看一下我们要生成的语法树是什么样子的
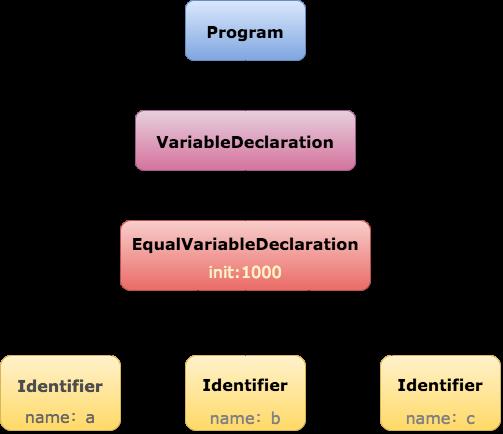
OK,大家对抽象语法树有了大概的认识,我们开始写代码,写代码之前,要搞清楚如何进行语法分析。由此,需要引出文法这一概念。文法是什么?文法其实是描述语言的一种工具。比如我们的赋值语句:
var a =1
怎么定义我们赋值语句的形式呢?如果用大白话来说,我可以这样解释赋值语句:赋值语句最左边是var,然后跟一个变量a,再跟等号,最后跟一个表达式。但这样解释太啰嗦了,我需要用一组符号来表示
S->abcE;E->f
S 对应赋值语句
a 对应 关键词var
b 对应 变量a
c 对应 操作符=
E 对应 表达式
f 对应 数字1
这种用符号来表示语言的形式就叫产生式,S->abcE代表S的产生式,E->f代表E的产生式,其中小写字母代表终结符,大写字母代表非终结符。当我们为式子中某个非终结符挑选一个产生式,并用这个产生式的右侧部分代替这个非终结符在式子中的位置,那么这个过程,我们叫非终结符的展开。当某个式子能够按照文法完全展开,那么我们可以说这个式子符合该文法的定义,是正确的文法。
语法分析的过程就是根据文法定义,不停的去寻找产生式,直到找到一个匹配源代码的展开方案,如果找不到,说明我们的源代码是有语法错误的。
明白了文法的定义形式,我们为qi语法定义如下的文法:
S -> aV
变量定义语句 -> var 变量定义,
V -> DF
变量定义 -> 变量 跟随变量定义
F -> ξ
跟随变量定义 -> 空
F -> ,V
跟随变量定义 -> , 变量定义
D -> IE
变量 -> 多变量 表达式
I -> iI
多变量 -> 单变量 多变量
I -> ξ
多变量 -> 空
E->ξ
表达式 -> 空
E->t
表达式 -> = 数字字面量 | 布尔字面量 | 字符串字面量 | null
注:终结符有三类,a代表关键词var或者let,i代表变量名,t代表字面量
如图
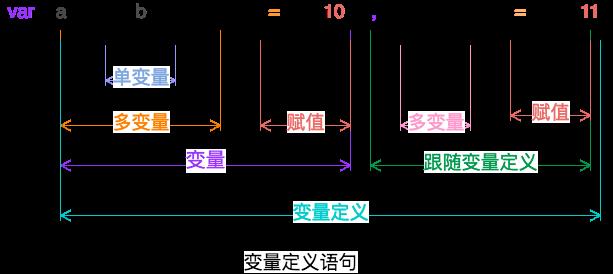
文法定义好了,我们拿一个式子展开一下,验证一下该式是否符合该文法。
var a b c =10
展开上式
代入1式,得S->varV
代入2式,得S->varDF
带入5式,得S->varIEF
代入6式,得S->vara IEF
代入6式,得S->vara b IEF
代入6式,得S->vara b cIEF
代入7式,得S->vara b c EF
代入9式,得S->vara b c =10F
代入3式,得S->vara b c =10
展开成功,该语句是符合我们连等语法的赋值语句。
再来个复杂一些的:
vara b c =10, d e =11
代入1式,得S->varV
代入2式,得S->varDF
代入5式,得S->varIEF
代入6式,得S->vara IEF
代入6式,得S->vara b IEF
代入6式,得S->vara b cIEF
代入7式,得S->vara b c EF
代入9式,得S->vara b c=10F
代入4式,得S->vara b c=10, V
代入2式,得S->vara b c =10, DF
代入5式,得S->vara b c =10, IEF
代入6式,得S->vara b c =10, d IEF
代入6式,得S->vara b c =10, d e IEF
代入7式,得S->vara b c =10, d e EF
代入9式,得S->vara b c =10, d e =11F
代入3式,得S->vara b c =10, d e =11
展开成功
文法定义好了,接下来我们开始编写语法分析器。其实语法分析就是寻找式子展开方案的过程,并根据文法中的产生式构建抽象语法树。语法分析的关键点搞定之后,我们就可以进行编码了。碍于篇幅有限,我只贴上生成语法树的递归函数。详细代码参见语法分析器
https://github.com/lucefer/continue-assign-parser/blob/master/src/compiler/parser.js
functionparseEqualVariableDeclaration(re)
{
letnode, equalNode, id_list
current_token = token_list[pos++]
//遍历token集合
while (current_token.type === Type.IDENTIFIER) {
node = newNode()
node.type = Syntax.Identifier
node.value = current_token.value
!id_list && (id_list = [])
id_list.push(node)
current_token = token_list[pos++]
}
if (!id_list) {
return
}
//如果每一个定义语句多于一个变量的话,则视为Syntax.EqualVariableDeclaration
if (id_list.length > 1) {
equalNode = newNode()
equalNode.type = Syntax.EqualVariableDeclaration
equalNode.body = id_list
re.push(equalNode)
}
elseif(id_list.length === 1)
{
re.push(node)
}
//判断是否存在跟随变量,如果存在的话,递归解析
if (current_token && current_token.value === ',') {
if (equalNode) {
equalNode.init = undefined
} else {
id_list.forEach(function (n) {
n.init = undefined
})
}
parseEqualVariableDeclaration(re)
}
letinit = ''
//判断是否有赋值过程
if (current_token && current_token.value === '=') {
current_token = token_list[pos++]
// 若有赋值过程,则值类型必须在基础类型范围之内
if (current_token.type === Type.STRING_LITERAL || current_token.type === Type.NUMBER_LITERAL || current_token.type == Type.BOOLEAN_LITERAL || current_token.type == Type.NULL_LITERAL) {
if (current_token.type === Type.STRING_LITERAL) {
init = '"' + current_token.value + '"'
} else {
init = current_token.value
}
current_token = token_list[pos++]
}
elseif(current_token.type === Syntax.BR)
{
current_token = token_list[pos++]
}
else
{
thrownewError("语法分析错误")
}
if (equalNode) {
equalNode.init = init
} else {
node.init = init
}
}
//判断赋值语句后是否存在跟随变量,如果有,则递归解析
if (current_token && current_token.value === ',') {
parseEqualVariableDeclaration(re)
}
}
语法分析结束后,我们能得到下面的语法树。
{
"type":"Program",
"body": [{
"type":"VariableDeclaration",
"body": [{
"type":"EqualVariableDeclaration",
"body": [{
"type":"Identifier",
"value":"a"
}, {
"type":"Identifier",
"value":"b"
}, {
"type":"Identifier",
"value":"c"
}],
"init":100
}],
"kind":"var"
}]
}
语法树遍历器
经过语法分析,我们得到了qi语言的语法树,正常情况下我们可以根据语法树,生成最终代码了,但我想再增加一个语法树遍历器transformer,通过它,我可以将qi语法的AST转换成任何我想要的语言的AST,这样我可以为这些语言扩充qi语法,而不仅仅是为javascript。
语法树遍历器的实现比较简单,我只需要对qi语法的AST树采用深度优先遍历即可,具体代码参见语法树遍历器 https://github.com/lucefer/continue-assign-parser/blob/master/src/compiler/transformer.js
OK,说下我的期望,我想将qi语法的语法树转变成如下树形结构。
{
"type":"Program",
"body": [{
"type":"VariableDeclaration",
"body": [{
"type":"Identifier",
"value":"a"
}, {
"type":"Identifier",
"value":"b"
}, {
"type":"Identifier",
"value":"c"
}],
"kind":"var"
}, {
"type":"AssignmentExpression",
"body": [{
"type":"AssignmentEqual",
"body": [{
"type":"Identifier",
"value":"a"
}, {
"type":"Identifier",
"value":"b"
}, {
"type":"Identifier",
"value":"c"
}],
"value":100
}]
}]
}
经过AST转换之后,我得到了包含一个变量定义语句和一个赋值表达式语句的树形结构,这种结构在生成目标代码阶段更容易分析。
目标代码生成
经过语法树遍历器我们得到了更利于生成代码的树形结构,这样我们就可以构造目标代码了。构造过程分为两个阶段
1. 生成变量定义代码
{
"type":"VariableDeclaration",
"body": [{
"type":"Identifier",
"value":"a"
}, {
"type":"Identifier",
"value":"b"
}, {
"type":"Identifier",
"value":"c"
}],
"kind":"var"
}
上面的树形结构对应代码
var a, b, c
2. 生成变量赋值代码
{
"type":"AssignmentExpression",
"body": [{
"type":"AssignmentEqual",
"body": [{
"type":"Identifier",
"value":"a"
}, {
"type":"Identifier",
"value":"b"
}, {
"type":"Identifier",
"value":"c"
}],
"value":100
}]
}
上面树形结构对应代码为
a = b = c =100
可以看出,转换后的AST可以让我们很容易的生成目标代码,逻辑比较简单,这里不做过多着墨,详细代码参见代码生成器
结语
至此,我们的编译器就介绍完了,希望本文能够帮助大家消除编译器的困惑。本文的所有源码托管在github上。另外,针对该库我编写了一个webpack-loaderassign-loader,感兴趣的同学可以去试用下。
..........
苹果耍[流氓]啦~要对赞赏收30%过路费
以下是ios用户专用赞赏通道~
感谢您的支持,我们会继续努力!
..........
以上是关于如何实现一个简易编译器的主要内容,如果未能解决你的问题,请参考以下文章