Java虚拟机-即时编译器(上)
Posted Mr羽墨青衫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java虚拟机-即时编译器(上)相关的知识,希望对你有一定的参考价值。
本文会先介绍Java的执行过程,进而引出对即时编译器的探讨,下篇会介绍分层编译的机制,最后介绍即时编译器对应用启动性能的影响。
本文内容基于HotSpot虚拟机,设计Java版本的地方会在文中说明。
0 Java程序的执行过程
Java面试中,有一道面试题是这样问的:Java程序是解释执行还是编译执行?
在我们刚学习Java时,大概会认为Java是编译执行的。其实,Java既有解释执行,也有编译执行。
Java程序通常的执行过程如下:

源码.java文件通过javac命令编译成.class的字节码,再通过java命令执行。
需要说明的是,在编译原理中,通常将编译分为前端和后端。其中前端会对程序进行词法分析、语法分析、语义分析,然后生成一个中间表达形式(称为IR:Intermediate Representation)。后端再讲这个中间表达形式进行优化,最终生成目标机器码。
在Java中,javac之后生成的就是中间表达形式(.class),举个栗子
1public class JITDemo2 {
2 public static void main(String[] args) {
3 System.out.println("Hello World");
4 }
5}
上述代码通过javap反编译后如下:
1// javap -c JITDemo2.class
2
3Compiled from "JITDemo2.java"
4public class com.example.demo.jitdemo.JITDemo2 {
5 public com.example.demo.jitdemo.JITDemo2();
6 Code:
7 0: aload_0
8 1: invokespecial #1 // Method java/lang/Object."<init>":()V
9 4: return
10
11
12 public static void main(java.lang.String[]);
13 Code:
14 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
15 3: ldc #3 // String Hello World
16 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
17 8: return
18}
JVM在执行时,首先会逐条读取IR的指令来执行,这个过程就是解释执行的过程。当某一方法调用次数达到即时编译定义的阈值时,就会触发即时编译,这时即时编译器会将IR进行优化,并生成这个方法的机器码,后面再调用这个方法,就会直接调用机器码执行,这个就是编译执行的过程。
所以,从.java文件到最终的执行,其过程大致如下:
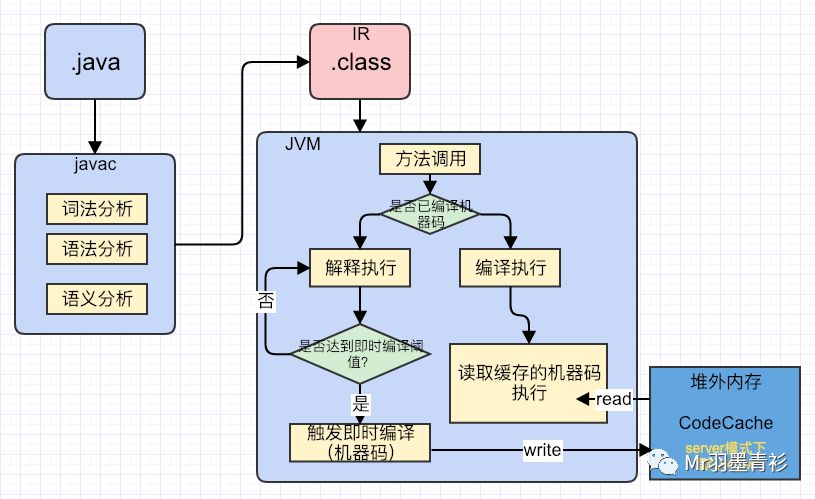
(CodeCache会在下文中介绍)
那么,何时出发即时编译?即时编译的过程又是怎样的?我们继续往下研究。
1 Java即时编译器初探
HotSpot虚拟机有两个编译器,称为C1和C2编译器(Java10以后新增了一个编译器Graal)。
C1编译器对应参数-client,对于执行时间较短,对启动性能有要求的程序,可以选择C1。
C2编译器对应参数-server,对峰值性能有要求的程序,可以选择C2。
但无论是-client还是-server,C1和C2都是有参与编译工作的。这种方式成为混合模式(mixed),也是默认的方式,可以通过java -version看出:
1C:\Users\Lord_X_>java -version
2java version "1.8.0_121"
3Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
4Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
最后一行的mixed mode说明了这一点。
我们也可以通过-Xint参数强行指定只使用解释模式,此时即时编译器完全不参与工作,java -version的最后一行会显示interpreted mode。
可以通过参数-Xcomp强行指定只使用编译模式,此时程序启动后就会直接对所有代码进行编译,这种方式会拖慢启动时间,但启动后由于省去了解释执行和C1、C2的编译时间,代码执行效率会提升很多。此时java -version的最后一行会显示compiled mode。
下面通过一段代码来对比一下三种模式的执行效率(一个简陋的性能 ):
1public class JITDemo2 {
2
3 private static Random random = new Random();
4
5 public static void main(String[] args) {
6 long start = System.currentTimeMillis();
7 int count = 0;
8 int i = 0;
9 while (i++ < 99999999){
10 count += plus();
11 }
12 System.out.println("time cost : " + (System.currentTimeMillis() - start));
13 }
14
15 private static int plus() {
16 return random.nextInt(10);
17 }
18}
首先是纯解释执行模式
添加虚拟机参数:-Xint -XX:+PrintCompilation(打印编译信息)
执行结果:
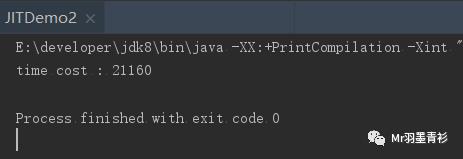
编译信息没有打印出来,侧面证明了即时编译器没有参与工作。
然后是纯编译执行模式
添加虚拟机参数:-Xcomp -XX:+PrintCompilation
执行结果:
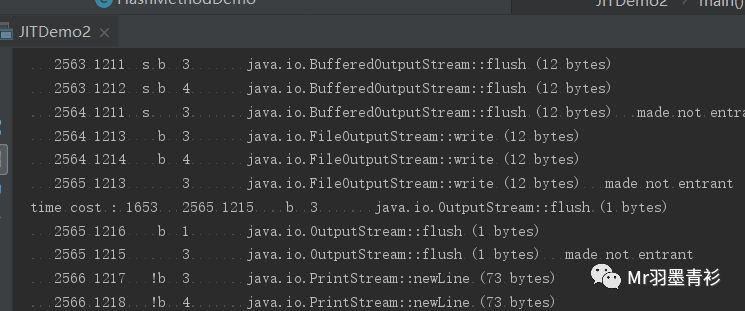
会产生大量的编译信息
最后是混合模式
添加虚拟机参数:-XX:+PrintCompilation
执行结果:
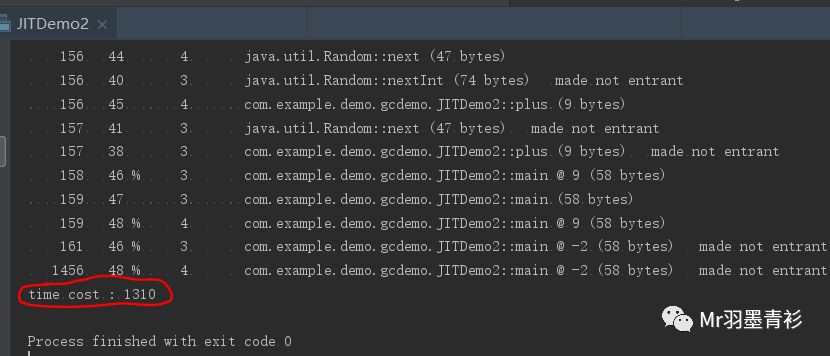
结论:纯解释模式>纯编译模式>混合模式
但这里只是一个很简短的程序,如果是长时间运行的程序,不知纯编译模式的执行效率会否高于混合模式,而且这个测试方式并不严格,最好的方式应该是在严格的基准测试下测试。
2 何时触发即时编译
即时编译器触发的根据有两个方面:
方法的调用次数
循环回边的执行次数
JVM在调用一个方法时,会在计数器上+1,如果方法里面有循环体,每次循环,计数器也会+1。
在不启用分层编译时(下篇会介绍),当某一方法的计数器达到由参数-XX:CompileThreshold指定的值时(C1为1500,C2为10000),就会触发即时编译。
下面做个关闭分层编译时,即时编译触发的实验:
首先是根据方法调用触发(不涉及循环)
1// 参数:-XX:+PrintCompilation -XX:-TieredCompilation(关闭分层编译)
2public class JITDemo2 {
3 private static Random random = new Random();
4
5 public static void main(String[] args) {
6 long start = System.currentTimeMillis();
7 int count = 0;
8 int i = 0;
9 while (i++ < 15000){
10 System.out.println(i);
11 count += plus();
12 }
13 System.out.println("time cost : " + (System.currentTimeMillis() - start));
14 }
15
16 // 调用时,编译器计数器+1
17 private static int plus() {
18 return random.nextInt(10);
19 }
20}
执行结果如下:
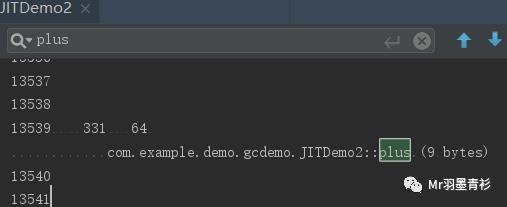
由于解释执行时的计数工作并没有严格与编译器同步,所以并不会是严格的10000,其实只要调用次数足够大,就可以视为热点代码,没必要做到严格同步。
根据循环回边
1public class JITDemo2 {
2 private static Random random = new Random();
3
4 public static void main(String[] args) {
5 long start = System.currentTimeMillis();
6 plus();
7 System.out.println("time cost : " + (System.currentTimeMillis() - start));
8 }
9
10 // 调用时,编译器计数器+1
11 private static int plus() {
12 int count = 0;
13 // 每次循环,编译器计数器+1
14 for (int i = 0; i < 15000; i++) {
15 System.out.println(i);
16 count += random.nextInt(10);
17 }
18 return random.nextInt(10);
19 }
20}
执行结果:
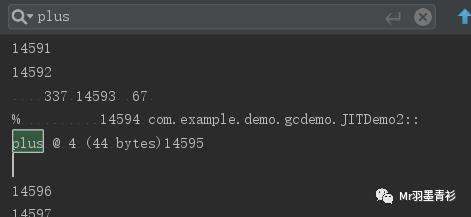
根据方法调用和循环回边
PS:每次方法调用中有10次循环,所以每次方法调用计数器应该+11,所以应该会在差不多大于10000/11=909次调用时触发即时编译。
1public class JITDemo2 {
2 private static Random random = new Random();
3
4 public static void main(String[] args) {
5 long start = System.currentTimeMillis();
6 int count = 0;
7 int i = 0;
8 while (i++ < 15000) {
9 System.out.println(i);
10 count += plus();
11 }
12 System.out.println("time cost : " + (System.currentTimeMillis() - start));
13 }
14
15 // 调用时,编译器计数器+1
16 private static int plus() {
17 int count = 0;
18 // 每次循环,编译器计数器+1
19 for (int i = 0; i < 10; i++) {
20 count += random.nextInt(10);
21 }
22 return random.nextInt(10);
23 }
24}
执行结果:
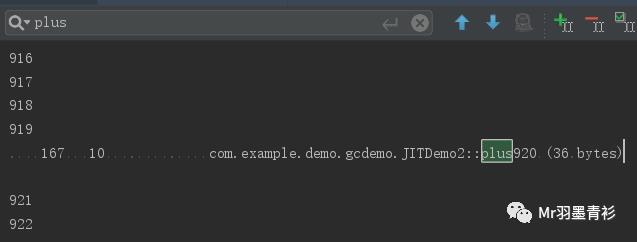
3 CodeCache
CodeCache是热点代码的暂存区,经过即时编译器编译的代码会放在这里,它存在于堆外内存。
-XX:InitialCodeCacheSize和-XX:ReservedCodeCacheSize参数指定了CodeCache的内存大小。
-XX:InitialCodeCacheSize:CodeCache初始内存大小,默认2496K
-XX:ReservedCodeCacheSize:CodeCache预留内存大小,默认48M
PS:可以通过-XX:+PrintFlagsFinal打印出所有参数的默认值。
3.1 通过jconsole监控CodeCache
可以通过JDK自带的jconsole工具看到CodeCache在内存中所处的位置,例如
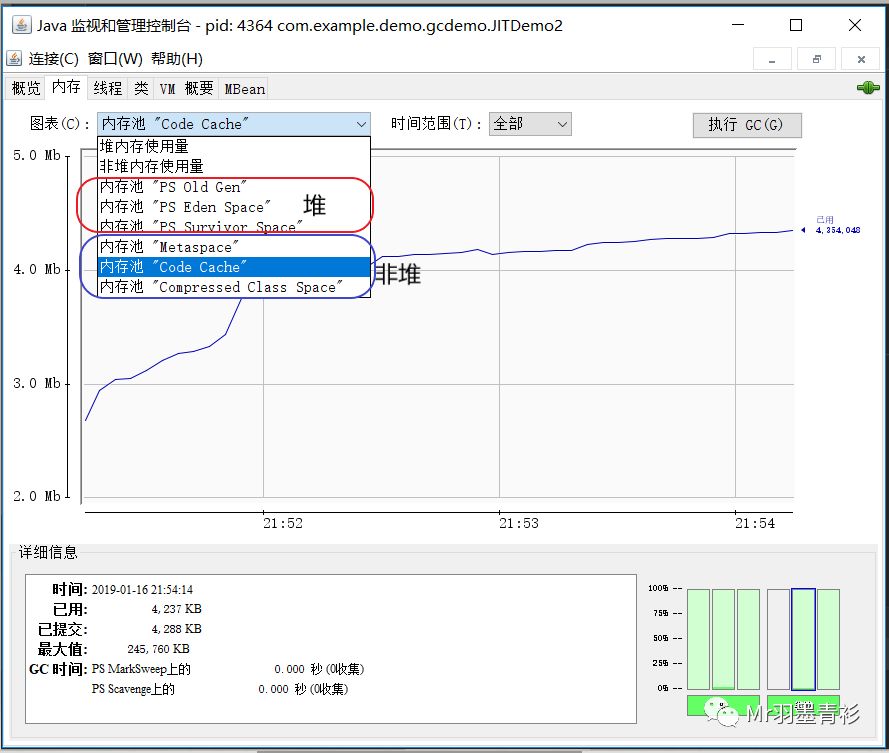
从图中曲线图可以看出CodeCache已经使用了4M多。
3.2 CodeCache满了会怎样
平时我们为一个应用分配内存时往往会忽略CodeCache,CodeCache虽然占用的内存空间不大,而且他也有GC,往往不会被填满。但如果CodeCache一旦被填满,那对于一个QPS高的、对性能有高要求的应用来说,可以说是灾难性的。
通过上文的介绍,我们知道JVM内部会先尝试解释执行Java字节码,当方法调用或循环回边达到一定次数时,会触发即时编译,将Java字节码编译成本地机器码以提高执行效率。这个编译的本地机器码是缓存在CodeCache中的,如果有大量的代码触发了即时编译,而且没有及时GC的话,CodeCache就会被填满。
一旦CodeCache被填满,已经被编译的代码还会以本地代码方式执行,但后面没有编译的代码只能以解释执行的方式运行。
通过第2小节的比较,可以清晰看出解释执行和编译执行的性能差异。所以对于大多数应用来说,这种情况的出现是灾难性的。
CodeCache被填满时,JVM会打印一条日志:
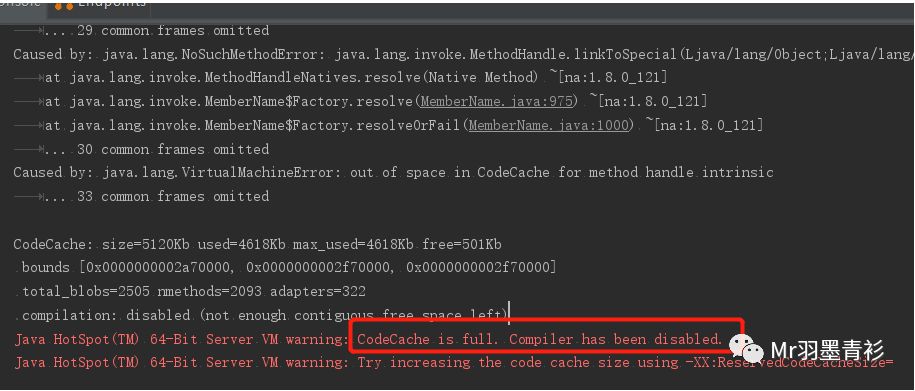
JVM针对CodeCache提供了GC方式: -XX:+UseCodeCacheFlushing。在JDK1.7.0_4之后这个参数默认开启,当CodeCache即将填满时会尝试回收。JDK7在这方面的回收做的不是很少,GC收益较低,在JDK8有了很大的改善,所以可以通过升级到JDK8来直接提升这方面的性能。
3.3 CodeCache的回收
那么什么时候CodeCache中被编译的代码是可以回收的呢?
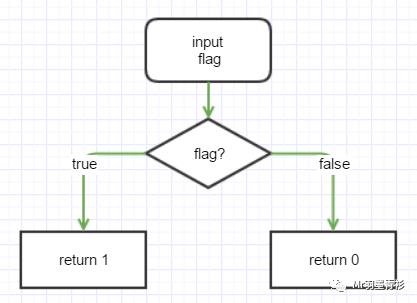
这要从编译器的编译方式说起。举个例子,下面这段代码:
1public int method(boolean flag) {
2 if (flag) {
3 return 1;
4 } else {
5 return 0;
6 }
7}
从解释执行的角度来看,他的执行过程如下:
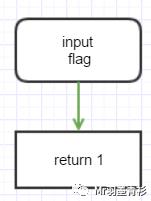
但经过即时编译器编译后的代码不一定是这样,即时编译器在编译前会收集大量的执行信息,例如,如果这段代码之前输入的flag值都为true,那么即时编译器可能会将他变异成下面这样:
1public int method(boolean flag) {
2 return 1;
3}
即下图这样
但可能后面不总是flag=true,一旦flag传了false,这个错了,此时编译器就会将他“去优化”,变成编译执行方式,在日志中的表现是made not entrant:
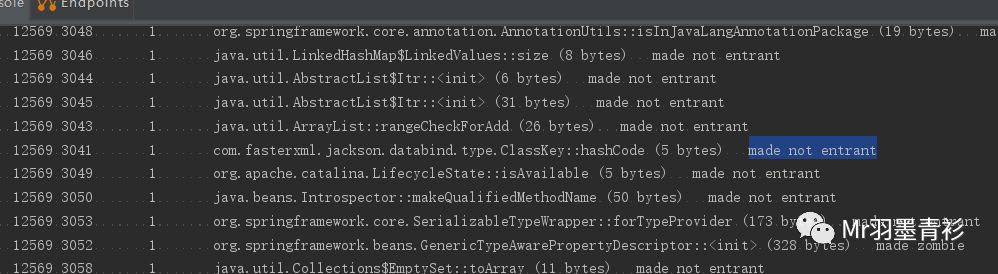
此时该方法不能再进入,当JVM检测到所有线程都退出该编译后的made not entrant,会将该方法标记为:made zombie,此时 这块代码占用的内存就是可回收的了。可以通过编译日志看出:
3.4 CodeCache的调优
在Java8中提供了一个JVM启动参数:-XX:+PrintCodeCache,他可以在JVM停止时打印CodeCache的使用情况,可以在每次停止应用时观察一下这个值,慢慢调整为一个最合适的大小。
以一个SpringBoot的Demo说明一下:
1// 启动参数:-XX:ReservedCodeCacheSize=256M -XX:+PrintCodeCache
2@RestController
3@SpringBootApplication
4public class DemoApplication {
5 // ... other code ...
6
7 public static void main(String[] args) {
8 SpringApplication.run(DemoApplication.class, args);
9 System.out.println("start....");
10 System.exit(1);
11 }
12}
这里我将CodeCache定义为256M,并在JVM退出时打印了CodeCache使用情况,日志如下:
最多只使用了6721K(max_used),浪费了大量的内存,此时就可以尝试将-XX:ReservedCodeCacheSize=256M调小,将多余的内存分配给别的地方。
4 参考文档
[1] https://blog.csdn.net/yandaonan/article/details/50844806
[2] 深入理解Java虚拟机 周志明 第11章
[3] 极客时间《深入拆解Java虚拟机》 郑雨迪
以上是关于Java虚拟机-即时编译器(上)的主要内容,如果未能解决你的问题,请参考以下文章