开源被喷,闭源被疑:方舟编译器怎么这么难?
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源被喷,闭源被疑:方舟编译器怎么这么难?相关的知识,希望对你有一定的参考价值。
作者丨赵钰莹
自 8 月 31 日正式开源,方舟编译器的讨论热度达到高潮,知乎话题《如何看待方舟编译器于 2019 年 8 月 31 日开源?》累计被浏览了五百多万次,网友共计发表了八百多条评论。由于本次开源放出的代码较少,不少网友都抛出了疑问,比如运行时方面的计划,开源的原因,开发出来的应用是否只能在华为手机上运行以及未来打算怎么做生态等,十年磨出的方舟编译器,一朝开源怎么就面临这么艰难的境地呢?
事实上,相比于过往十年的研发历程,现在的处境可能还算不上最艰难的。
2009 年,华为第一个编译团队成立,起初是为了无线基站领域的 DSP 性能问题。
2014 年,Open64 的鼻祖 Fred Chow 加入,这对华为后来的编译器发展,包括如今的方舟编译器都产生了重要影响。
2017 年,华为手机的销量非常之高,又开始出现大量新的问题。当时,整个混合执行模式里,解释执行的占比非常高,而执行性能比较低,JIT 在后台生成 JIT 代码的过程又会消耗大量 CPU 资源,编一个函数需要的时间也很长。此外,由于优化不完善,虚拟机的停顿时间非常长,尤其内存不足时,会导致大量卡顿。
基于上述原因,整个团队讨论出两条可行的解决方案:一是在现有虚拟机的基础上修改;二是另起炉灶,重新做一套能够执行 Java 的运行环境和编译器。第一条路相对简单省事,但只能解决部分问题,华为最终选择了第二条路线,这就促成了如今方舟编译器的诞生。
在方舟编译器的设计上,Fred Chow 的一篇论文提供了很好的思路:基于统一的 IR 既支持多种编程语言表示,又支持后端多芯片代码的指定形成。这就构成了方舟编译器的理论基础。在这个理论基础上,方舟编译器团队基于 MAPLE IR 做了更复杂的优化和更广义的控制流分析。
2019 年 4 月份,华为发布方舟编译器(ArkCompiler),同时在 8 月底将其编译框架代码开源,并计划后续完整开源方舟编译器的所有代码。然而,开源后的方舟编译器受到了四面八方开发者的高度关注,面对现在开源出来的少量代码,很难让人相信这是一个多语言、跨平台、高效的编程环境。
于是,整个团队首次公开了方舟编译器的基础架构和源码分析。
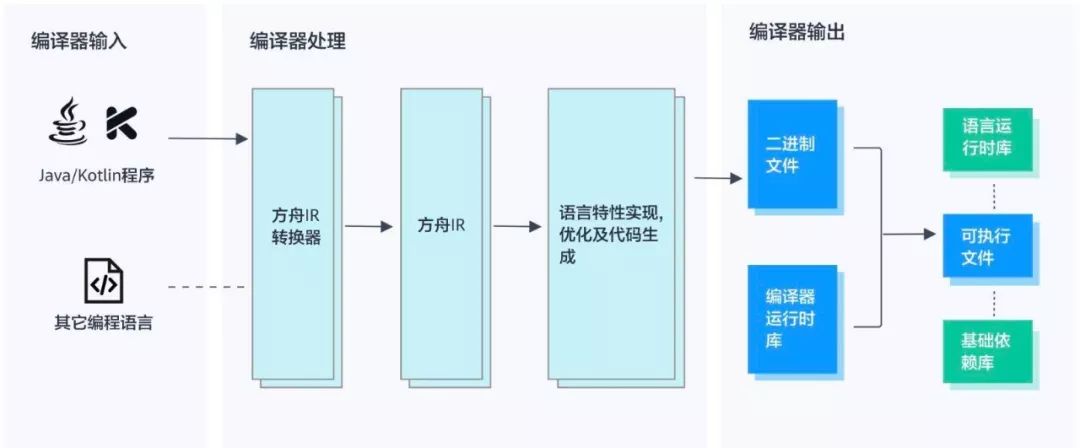
8 月 31 日,华为方舟编译器开源了编译器框架部分源码,包括编译器中间表示(IR,Intermediate Representation)和语言编译实现,同时搭配编译器其它二进制组件,实现 Java 程序到 aarch64 汇编指令的编译过程。

在华为的描述中,开发者可基于开源代码和二进制,编译构建出编译器工具链,尝试对 Java 程序进行编译。社区参与者可以通过框架源码学习方舟编译器的编译器中间表示(IR)及基本的中端编译框架,熟悉方舟编译器的架构思想,并参与诸如对编译器中端优化的贡献。方舟编译器是为支持多种编程语言、多种芯片平台的联合编译、运行而设计的统一编程平台,包含编译器、工具链、运行时等关键部件。
就目前可见的范围,整个方舟编译器的开源部分代码由 C、C++ 的头文件、源码和汇编代码组成,C 语言的头文件占了绝大部分,目前提供的代码一共有七万多行,注释大概有一万多行,还有很多空行,加起来大约有 10 万行代码,而其中的注释非常之少。每个文件的大小整体也不是很大,个别超过了 2000 多行,大部分在 1000 行以下。
从代码内容来看,主要是与中间代码相关的部分,当然也包括了 Phase、IPA,但实际里面主要是阶段性管理的辅助代码,真正相关的代码目前还没有呈现。huawei_secure_c 的文件中存放了大量关键代码,比如内存拷贝等关键函数。根据选取的几个测试用例,目前对 Java 1.6 及以上版本的支持都没有问题,从 Java 到 IR 的翻译还是比较顺畅,只不过在第三库版本支持上可能会有问题。
至于上文提到的中间代码,根据 MAPLE 的文档,主要有如下几个特点:
尽可能保留源代码信息;
高层次树状层次化结构;
低层次与指令一一对应;
可扩展——支持新的语言和控制结构。
目前开源的方舟基础架构一部分是关于 Java/Kotlin 的编程语言实现,因为这两类语言强依赖虚拟机,方舟编译器去掉了虚拟机之后,补全了一些功能在里面;另一部分是后续优化和分析的基础支持,比如开源了 SSA 的表示。
方舟编译器架构师在近期的分享中表示,Maple IR 设计时基本考虑了三件事情:
1、IR 存在于三种不同的格式中:
Binary,主要用来做分发,或者是真正执行时需要考虑效率问题;
中间语言需要有可读性,因为程序员很关心代码的执行过程;
存在 In-memory 的过程,也就是组织中间语言在内存的存储。
2、分层设计,Maple 的整个想法来源于 Open64 的鼻祖 Fred Chow,而 Open64 当时的设计是五层结构。方舟编译器总结和借鉴了 Open64 的经验,形成了一个分层的设计,按需来选择不同层次。这样可以让高层语言快速回到原代码,大多数编译器都会支持这一功能,很多的应用场景都可用到。此外,高层的中间表示对实现接近原语言的优化会比较方便。比如,方舟编译器保留了较高层 Class 类型,这样做 TBAA 和 Devirtual 相对容易。
3、高层结构更接近原语言。原语言的代码最为精简,方舟编译器希望中间结构也能够更加精简,比如分发格式更小。同时,希望能够重用编译优化能力,当引入新语言时,能够尽量减少改动。分层之后引入新语言,可以只改高层,高层拓展后,底层所有优化保持不变。
在中间语言的部分,方舟编译器架构师表示可分为两部分看待:类型和操作符。
在类型上,Maple 编译器中有一个 Global tab 的表示,所有全局符号都保存在这里。第一项就是 type tab,这个的实现就是 MirType 的一个 vector。MirType 的定义基本上就只有这几项,首先要看类型到底是什么类型。其次,类型里面的 Primitive Type 是什么样子,比如说是一个 Int 或者更复杂的结构体。
基于最基础的 MirType,可以扩展出 Structure 结构。之后信息更加丰富,比如会有父类的一些 Field,还有 VTab、ITa 等。基于 MirStructType,可以扩展出高层结构,方舟编译器会保留 Class 信息,这部分目前来看对分析和优化的帮助非常大。
在操作符上,方舟编译器支持 Memory 的操作,也有结构化的操作符。除了支持传统调用,还支持很多 Java 特有的调用。
在内存管理上,方舟编译器目前是以 RC 为主,GC 为辅。开发者可能对 GC 比较熟悉,这里讲下对 RC 的一些支持。RC 是一个比较容易理解的事情,多一个引用就加一,少了就减一,思想比较简单。在真实应用中,方舟编译器加一的情况基本就四种:
一个对象引用了另一个对象,进行加一;
栈包括寄存器里的变量要去引用对象,再次加一;
静态或者全局变量多加一个引用的话,也要加一;
函数返回对象,也要加一。
减一的场景也比较简单,比如局部变量 Last Use 后,因为局部变量已经死掉,指向的原来对象要进行减一操作;如果某个变量被重新赋值,原来指向的堆对象也要进行减一操作。
在这种方式下,一个特别简单的函数可能要进行一系列加减操作,每次操作可能都要加锁,基本程序很难跑起来。于是,整个团队又开始从三个角度对此进行优化:
第一,减少插入,很多变量间的 Live Range 可能是重叠的,重叠后前面加一,后面减一的操作就可以不做了;如果实在没有办法避免插入,就看如何减少每一次操作的开销,方舟编译器有一个逃逸分析,最主要的结果是看变量会不会被多线程访问。如果变量的值被单线程访问,就不需要加锁,只需要加一或减一操作,然后保证不被提前释放就可以。
第二,RC 操作是比较麻烦的事情,方舟编译器现在提供 Annotation 的方法,Annotation 的效果应该是最好的,但对程序员要求较高,如果程序员加的不对,内存可能会出现泄漏。另外,方舟编译器也提供自学习的方法。
第三,方舟编译器以 RC 为主,GC 为辅。如果一些环没有被 RC 释放掉,可以从被 GC 释放掉的环里学到一些规则,把这些规则写成一个文件或者放到内存里,指导下一次运行时的内存释放。
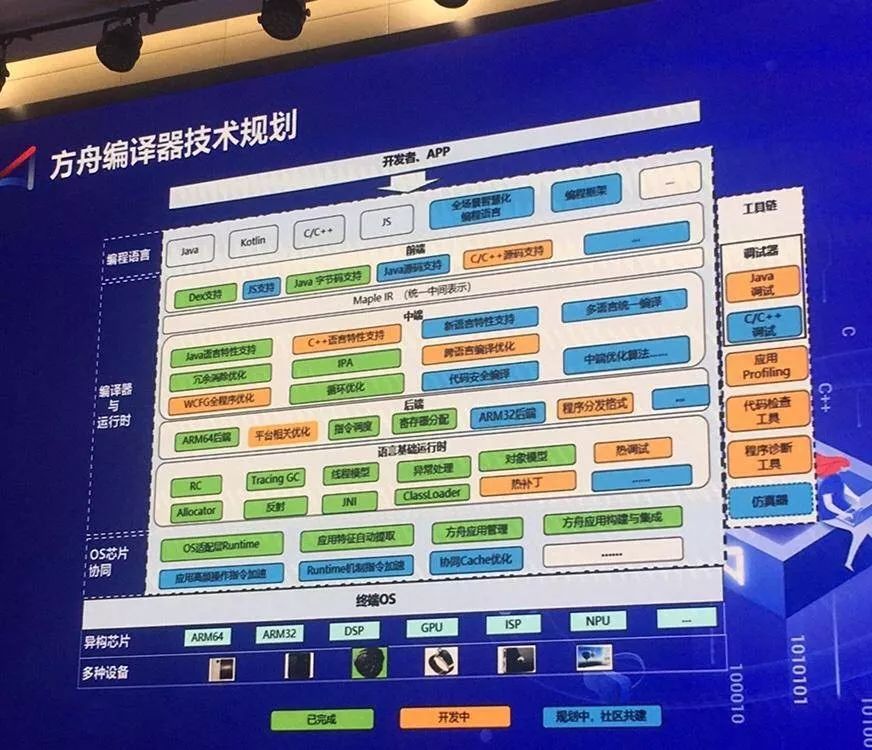
如上图,绿色的部分已经完成,黄色的部分还在开发中,而蓝色的部分还在规划中,华为希望与社区进行共建。
接下来,方舟编译器团队会开放跨语言全程序优化能力。对 android 而言,从 Java 到 C 或者从 C 到 Java 的调用,整个次数会非常多,而且每一次调用的开销也比较大。如果能够把这一部分做好,大概能够提高 10% 到 20% 的性能。
另外,整个团队还做了一些安全编译,比如把运行时错误移到编译时做,因为在运行时的状态下,Bug 很难查找,如果在编译时就对问题进行报警,这样对开发者比较友好。
目前方舟编译器的代码托管在华为云与码云平台(gitee.com),遵守的开源协议是中国首个开源协议——木兰宽松许可证,这样做的目的也是为了规避其他协议潜在的开源风险。在未来走向开放治理以后,方舟编译器将按照所挂靠机构的模式来托管。开发者可通过代码托管平台参与社区贡献,包括文档贡献和代码贡献,同时也可在此平台上反馈相关问题和需求。
在生态构建方面,很多开发者都认为这是方舟编译器需要迈过的一道大坎。其实,做生态不一定只有开源这一条路径,苹果没有开源却依然有大批开发者愿意为其平台开发应用,鸿蒙 OS 的开源主管表示,华为之所以选择开源方舟编译器,一是真的希望得到广大开发者的帮助,和众多编译器领域优秀的学者和从业人员一起进步;二是希望获得广大开发者的信任。
但是现在,很多开发者都觉得难以参与,因为没有 Runtime,开放的源代码也非常少。华为方舟编译器架构师表示方舟编译器其实有一个 Runtime,用来实现各种与运行相关的信息,比如 Java 反射、JNI 调用、内存管理、内存回收机制等,但现在只有 6 万行代码,是一个非常轻量级,只提供必备内容的 Runtime。
目前开发者可以先在华为手机上运行 ,同时华为也希望社区可以一起通过开源的方式做一个简单的 Runtime。后续会按照计划尽快开放所有源代码,因为代码开源需要进行很多清理和整改,时间上希望各位开发者多些耐心。如果开发者希望参与社区构建,可以考虑以下几个角度:
共建方舟 IR。其实现在方舟 IR 的标准还没有完全定下来,处在逐渐发展的过程中,华为希望和大家一起把标准做得更好。这里面也有很多挑战性的工作,因为不同的高级语言有不同的特征,类型系统、内存管理机制、内存对象模型都可能不同,希望大家能够形成更好的标准,支持更多语言表达;
多语言前端,目前的编译器只做了 Java,C++ 还在内部开发中,其实还有更多语言,包括 JS,也希望社区中的广大开发者共同建设;
多芯片后端,华为内部只做了 ARM64 的后端,ARM32 还在规划中,但可能有一些厂家用 X86,开发者可以结合自己的芯片做一些后端开发用到自己的产品中;
对编译算法有兴趣的同学,可以在中端和后端做一些编译算法优化,包括数组越界检查消除、锁优化等,这可能对大家都有好处。
方舟编译器的愿景就是构建多语言、跨平台、高效的编程环境。面向未来,华为做了很多全场景智慧化场景的尝试,如何全场景下进行高效编程以及在整个 IR 层面,如何进行优化等都是极具挑战的任务,方舟编译器未来同样希望与硬件更好结合,而这些都需要更多开发者参与其中。
方舟编译器主页:
https://www.openarkcompiler.cn
官方主库:
https://code.opensource.huaweicloud.com/HarmonyOS/OpenArkCompiler/home
Gitee 镜像仓库:
https://gitee.com/harmonyos/OpenArkCompiler
点个在看少个 bug 以上是关于开源被喷,闭源被疑:方舟编译器怎么这么难?的主要内容,如果未能解决你的问题,请参考以下文章