编译器"吸星大法"之抽象语法树(AST)
Posted 小雷学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译器"吸星大法"之抽象语法树(AST)相关的知识,希望对你有一定的参考价值。
概述
说到这个话题我相信部分朋友应该会有点蒙,这玩意是啥?,笔者个人认为AST几乎无处不在,这么说可能又有部分朋友又不理解了,OK ,本文会带各位做一个初步的了解,以及实际案例和实战应用,打个委婉的比喻我们可以说AST就像“九阳神功”-内功心法,有了这套心法,自己创造一门武学也是轻车熟路。
上段说到其“内功心法”无处不在,这里笔者先简单举几个常见的例子如下:
Druid
Druid提供SQL完整解析功能,根据不同的SQL关键字生成语法树进而进行处理
模板引擎(例如FTL , HTTL , Velocity etc . .)
解析模板引擎的时候会首先进行分词生成tokens,然后语义或者文本处理,接着生成树形结构,随后使用对应设计模式对其进行访问,最后渲染,渲染的过程就是值填充的过程。
ASM
ASM是一款字节码修改工具,像我们spring,JDK的动态代理底层就是ASM,所以基本可以理解为java使用动态代理的地方都会用到。
JSON解析引擎(以fastjson为代表)
对JSON关键字解析的时候会用到ASM的包
当然除此之外很多地方,比如我们的编译器底层解析代码的时候也是站在AST的肩膀上,再比如我们熟知的javascript脚本解析器在解析js脚本的时候会生成抽象语法树,然后使用访问者模式(后文实例讲解的时候会有说明)对其进行访问,汇总一句话,"但凡文本指令解析说透了都是对AST的处理"。
心法提炼
接下来我们开始以一个模板引擎案例简单诠释一下AST的用法,一个优秀的模板引擎几乎都会用到语法解析,在诠释之前我们先来看看流程图:
上图为编译原理虎皮书里边的借鉴,描述编译器的基本流程,我们只需要关注前端编译生成语法树之前的部分
流程梳理如下:
首先会进行词法分析(Lexical Analysis),我们俗称为“分词”,之后经语法分析(Syntax Analysis)也就是检查是否符合定义的语法,如果不符合报错,之后经语义分析(Semantic Analysis),意思就是通过对应文档发现对应词的潜在意思和意义,和中文的一词多义很相似,语义分析我们这边没有语义文档,本文不作讲解。
PS: 当我们熟悉上述流程之后接下来我们以HTTL为例,通过源码调试进一步说明AST的重要性,对于HTTL模板引擎感兴趣的可以去看下,我个人觉得是一个很好的学习案例,把个武学招式,分招分式的简化到了极致
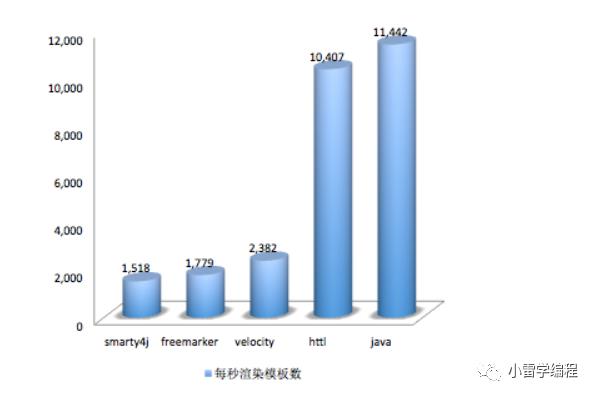
附上官网链接:http://httl.github.io/zh/
据官网数据报告得出HTTL在效率方面几乎接近于JAVA硬编码,远高于其他流行模板引擎。
接下来我们开始边调试代码边讲解,代码结构如下:
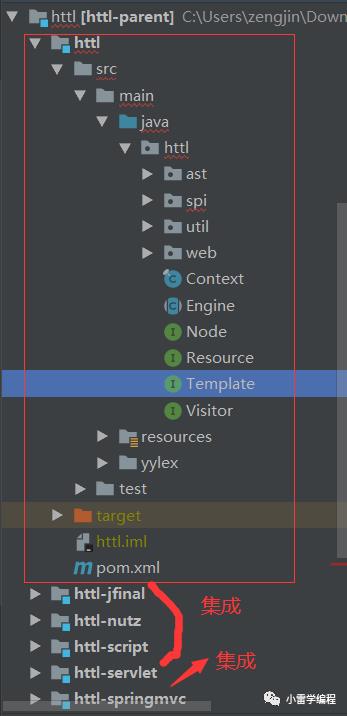
HTTL采用模块依赖,所以我们剑指核心心法,也就是上图红色框内容,分包详细解释见官网(例如SPI),这里我们主要讲AST包,因为要调试源码笔者首先想到的是测试用例,
看到这里某些读者可能会发现liangfei字眼,没错这就是梁飞大神的作品,当年阿里风声水起的亿级dubbo SOA架构,直到现在ali-cloud-dubbo的集成,后来作为apache基金会的顶级项目孵化,一直阿里一直都没有放弃过dubbo,而dubbo的主要开发就是梁飞,打个广告 _ _ ! 我的偶像。
直接运行测试用例:
运行之后进我之前打好的初始化断点如下:
上图会进行set操作,既然是初始化,简单说明一下,因为HTTL需要一个BEAN容器,但是为了减少依赖和重IOC框架引入,HTTL自己实现了一个beanFactory,作为各插件对象的核心通过SPI整合,这和spring 的容器很相似,对于这里之所以会调用set方法,其实就很好理解了,IOC容器通过反射注入对象调用set方法,我们继续。
当我们断点到这里的时候,我们可以看到我们的目标是hello.httl的处理,我们看看hello.httl脚本代码如下。
<!--#macro(hello(String name))-->Hello, ${name}!<!--#end--><!--#macro(welcome(String name))-->Welcome to hangzhou, ${name}!<!--#end-->
HTTL会把每一个httl文件都看成一个resource
我们可以看到有这么多resource的实现,ok,我们测试用例用的就是ClasspathResource,说明一下继续。

我们可以看到正确的加载了resource ,
这里不多说,毕竟文件加载不是我们的重点,
当代码走到240 line的时候就会通过流读到其模板内容,
我们可以看到当前classpathResource没有实现该方法,很显然调用的是抽象父类的方法,我们进去看看。

这样我们就拿到了模板内容了,接下来就是我们需要睁大眼睛的“内功心法”。

走过滤器之后会看到一个解析的过程,我标注了该过程是生成AST的核心所在,也是武学精髓所在,我们开始。

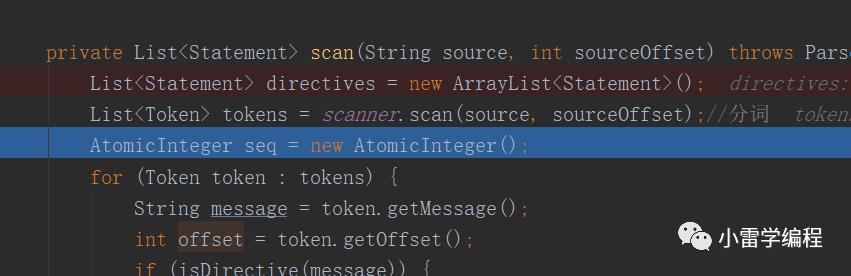
我们可以看到有三个方法,顺序是先走scan === > clean ====> trim,对应开篇的流程图,这里的clean , trim 属于语义分析部分,这里我们先过,详细看scan是如何做的,如下

走到这里会进行分词,因为分词的代码比较多,我直接写好注释贴出如下:
/*** 分词采用状态机模式根据不同关键字进行分词,* 让我想起了fastjson的解析,也是用的状态机模式* @param charStream* @param offset* @param errorWithSource* @return* @throws ParseException*/public List<Token> scan(String charStream, int offset, boolean errorWithSource) throws ParseException {List<Token> tokens = new ArrayList<Token>();// 解析时状态StringBuilder buffer = new StringBuilder(); // 缓存字符StringBuilder remain = new StringBuilder(); // 残存字符int pre = 0; // 上一状态int state = 0; // 当前状态char ch; // 当前字符// 逐字解析 ----int i = 0;int p = 0;for (; ; ) {if (remain.length() > 0) {// 先处理残存字符ch = remain.charAt(0);remain.deleteCharAt(0);} else { // 没有残存字符则读取字符流if (i >= charStream.length()) {break;}ch = charStream.charAt(i++);offset++;}buffer.append(ch); // 将字符加入缓存state = next(state, ch); // 从状态机图中取下一状态,状态机图采用二维数据装饰if (state <= ERROR) {throw new ParseException("DFAScanner.state.error, error code: " + (ERROR - state) + (errorWithSource ? ", source: " + charStream : ""), offset - buffer.length());}if (state <= POP) {int n = -(state % POP);int e = (state - n) / POP - 1;if (p <= 0) {throw new ParseException("DFAScanner.mismatch.stack" + (errorWithSource ? ", source: " + charStream : ""), offset - buffer.length());}p--;if (p == 0) {state = e;if (state == 0) {state = BREAK;}} else {state = n;continue;}} else if (state <= PUSH) {p++;state = PUSH - state;continue;}if (state <= BREAK) { // 负数表示接收状态int acceptLength;if (state <= BACKSPACE) {acceptLength = buffer.length() + state - BACKSPACE;//状态回退,回退所有空白符,退回的字符将重新读取if (acceptLength > 0) {int space = 0;for (int s = acceptLength - 1; s >= 0; s--) {if (Character.isSpaceChar(buffer.charAt(s))) {space++;} else {break;}}acceptLength = acceptLength - space;}} else {acceptLength = buffer.length() + state - BREAK;}if (acceptLength < 0 || acceptLength > buffer.length())throw new ParseException("DFAScanner.accepter.error" + (errorWithSource ? ", source: " + charStream : ""), offset - buffer.length());if (acceptLength != 0) {String message = buffer.substring(0, acceptLength);Token token = new Token(message, offset - buffer.length(), pre);tokens.add(token);// 完成接收}if (acceptLength != buffer.length())//没有结束,比如"(hello),jack",httl会在读到','之后的'j'的时候回到分片状态//那么会把"(hello)",作为第一个token,而','作为残存记录,开始状态回退state.BREAK从新读取remain.insert(0, buffer.substring(acceptLength)); // 将未接收的缓存记入残存buffer.setLength(0); // 清空缓存state = 0; // 回归到初始状态}pre = state;}// 接收最后缓存中的内容if (buffer.length() > 0) {String message = buffer.toString();tokens.add(new Token(message, offset - message.length(), pre));}return tokens;}
那么分词成功之后我们可以看到如下:
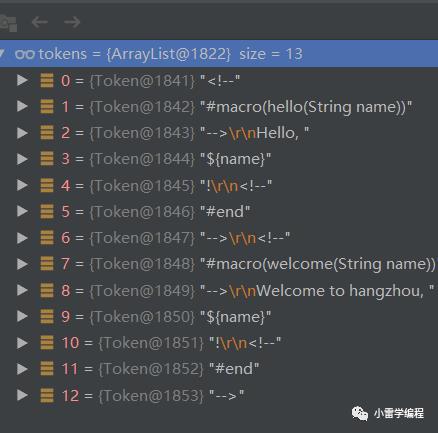
我们继续。
接下来我们会经过syntax analysis ,篇幅限制代码就不贴了,最终我们会把这13个TOKEN转换成我们各自语法node,如下:
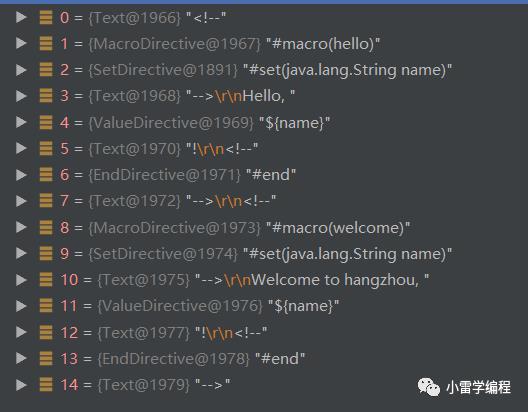
我们可以看到对应生成你了不同指令节点,文本节点text,这些指令在我们编写解析器引擎的时候自己可以定义,我们看看HTTL定义了哪些指令
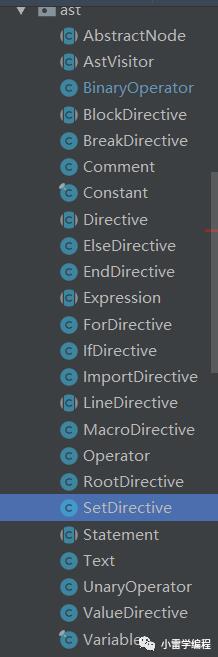
解释一下指令都继承AbstractNode,其作为Node的子类存在,我们也可以很明显的看出来,Expression(表达式),statement(域),而表达式又包括Operator,比如上图的一元操作符UnaryOpertator(类似 (e) -> e )等,和对应指令Directive。
分词语法分析之后会生成抽象语法树:
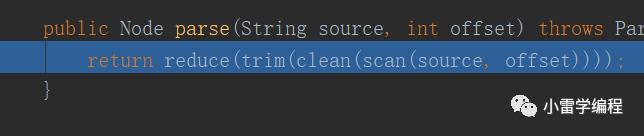
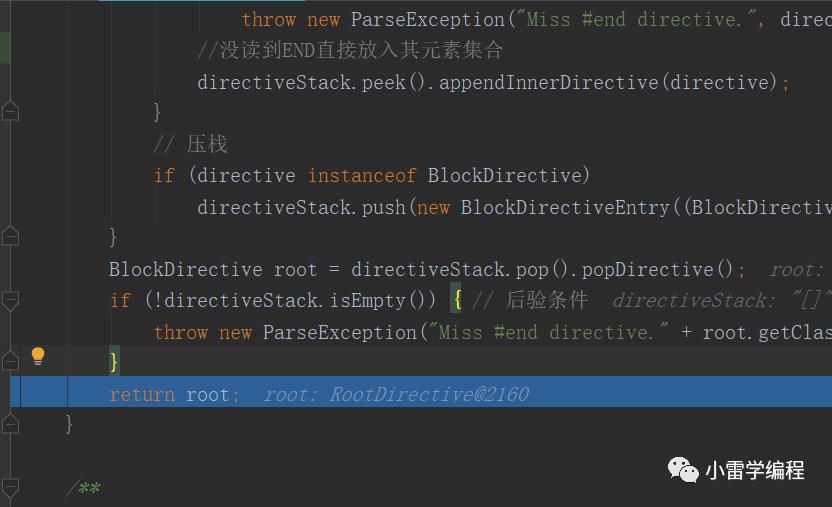
其中reduce方法就是生成语法树的简单逻辑:
private BlockDirective reduce(List<Statement> directives) throws ParseException {LinkedStack<BlockDirectiveEntry> directiveStack = new LinkedStack<BlockDirectiveEntry>();RootDirective rootDirective = new RootDirective();directiveStack.push(new BlockDirectiveEntry(rootDirective));for (Statement directive : directives) {if (directive == null)continue;Class<?> directiveClass = directive.getClass();// 弹栈if (directiveClass == EndDirective.class|| directiveClass == ElseDirective.class) {if (directiveStack.isEmpty())throw new ParseException("Miss #end directive.", directive.getOffset());BlockDirective blockDirective = directiveStack.pop().popDirective();if (blockDirective == rootDirective)throw new ParseException("Miss #end directive.", directive.getOffset());EndDirective endDirective;if (directiveClass == ElseDirective.class) {endDirective = new EndDirective(directive.getOffset());} else {endDirective = (EndDirective) directive;}blockDirective.setEnd(endDirective);}// 设置树if (directiveClass != EndDirective.class) { // 排除EndDirectiveif (directiveStack.isEmpty())throw new ParseException("Miss #end directive.", directive.getOffset());directiveStack.peek().appendInnerDirective(directive);}// 压栈if (directive instanceof BlockDirective)directiveStack.push(new BlockDirectiveEntry((BlockDirective) directive));}BlockDirective root = directiveStack.pop().popDirective();if (!directiveStack.isEmpty()) { // 后验条件throw new ParseException("Miss #end directive." + root.getClass().getSimpleName(), root.getOffset());}return root;}
如果上图我们可以看到对比的结果,通过stack的特性进行一个节点的子节点的组装,举个例子:我们要读1 + 3 * 4 这个Operator,1先入栈接着 + 号,然后3 发现 * 号比 + 号优先级高 继续入栈,遇到4 的时候出栈3 和 * 号做操作 3 * 4 = 12 随后在出栈+ 号 和 1 做 1 + 12 操作 = 13 ,其实理解就是先处理的那个操作符作为树的一个根节点,其子节点作为要参数,和这里的 BlockDirectiveEntry很像,因为要处理根的子节点所以入栈出栈都是在根上。
继续,
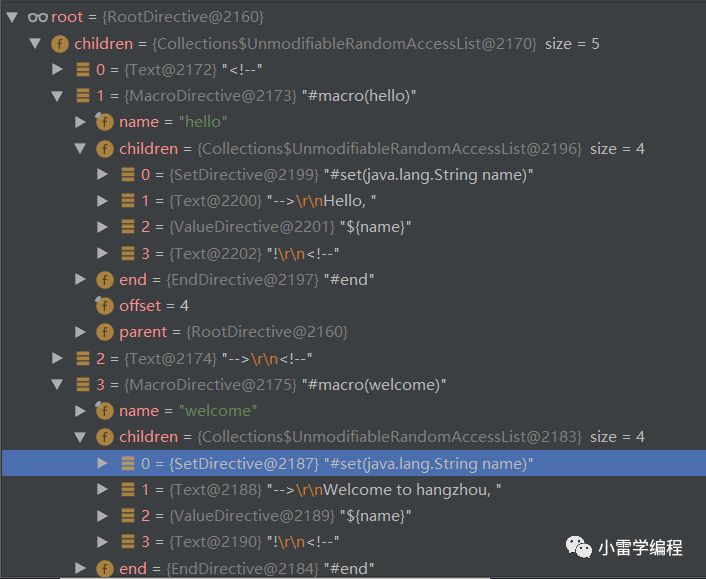
到这里我们的抽象语法树就生成了,我们以JSON 的方式打印看看树的结构如下:
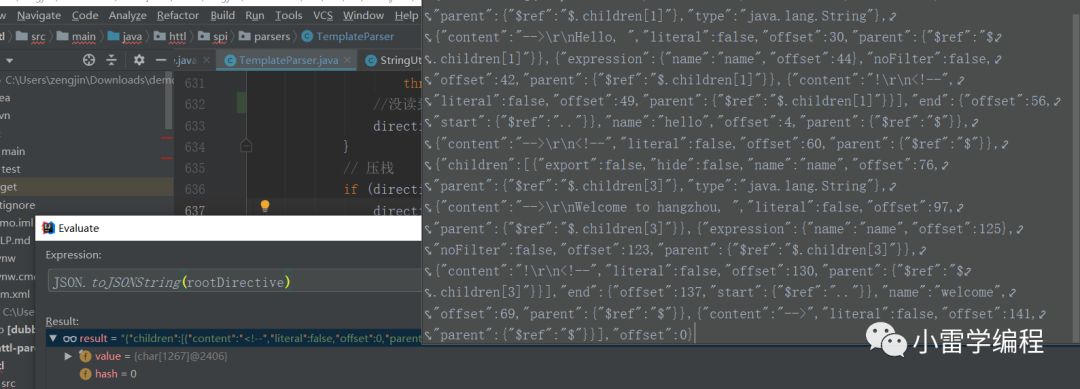
有经验的同学应该有感觉,MAP结构 ,树,JSON,其实是可以互相转换的,我们大体可以看出指令记录了内容,名字,和类型,以及对于子节点和offset字符偏移量。
那么接下来就需要对语法树进行访问了:

247行代码对语法树的访问和处理,进去
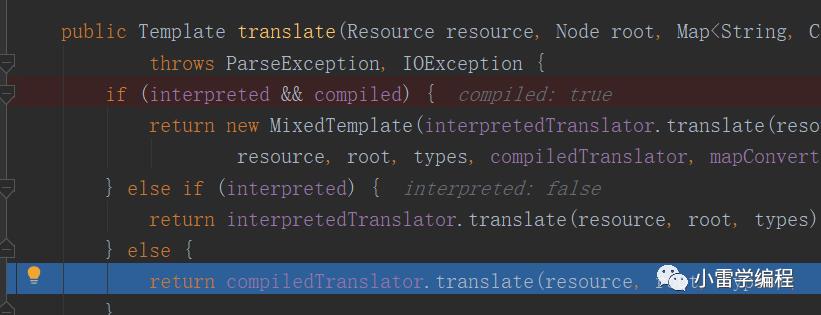
这里的使用的提前编译,也就是说每个模板会提前编译成字节码,也这就是官网为什么说HTTL极致的优化,在模板渲染的时候一个模板可以对应多个业务,所以静态模板只需要提前编译一次就可以了,不同的只是渲染的过程,
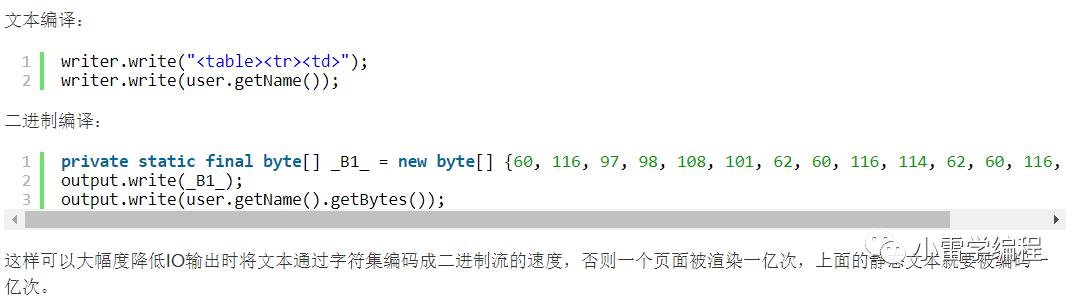
以上为官网的描述,其实在这里就可以提现了,我们继续
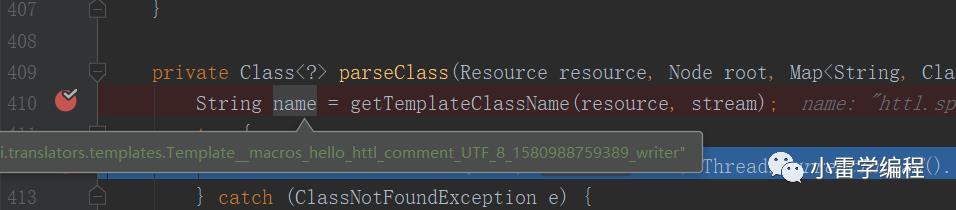
进去之后我们会走到这个方法,410行代码会生成一个不存在的名字,也就是需要运行时编译生成的类的名字,然后会走catch ,我们看看catch部分如下:
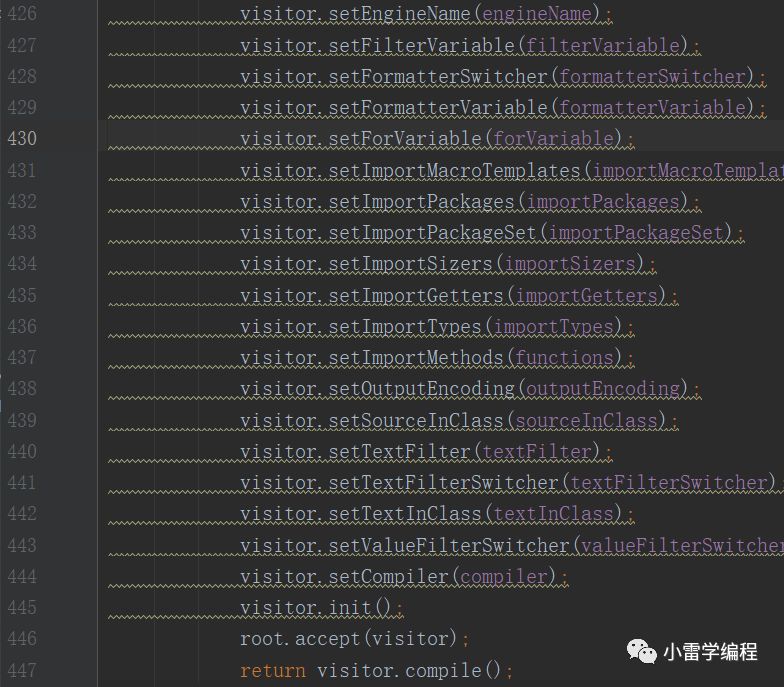
走到446行代码就开始了不同Node对于最后生成的动态编译类不同功能的组装,既然要组装类,那么肯定需要进行之前Node语法树的访问(能访问才能处理嘛),访问用到了访问者模式(有时间的可以先去看看,可能篇幅有限不会讲很细),也就是开篇说到的ASM在运行时访问每个类结构的时候用的方式
ok,我们debug进去,此时我们的root就是一开始的rootDirectve
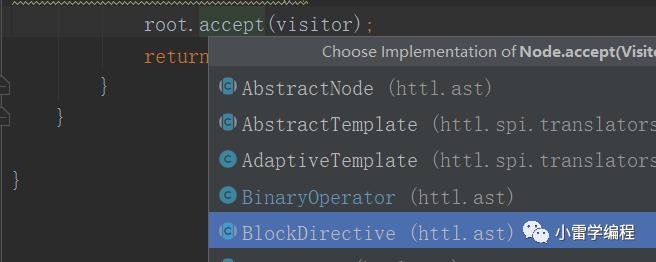
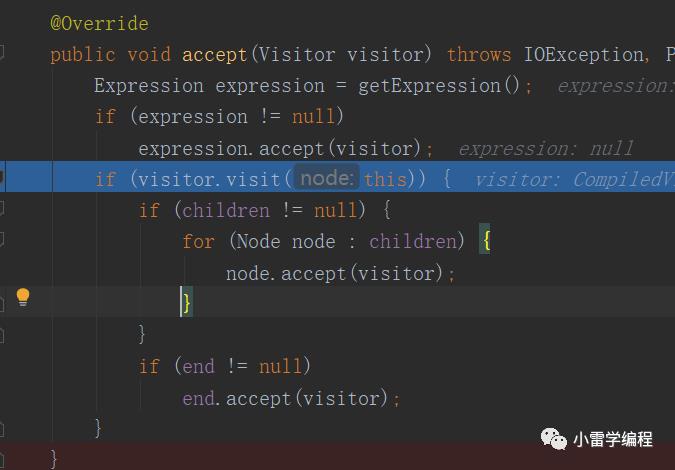
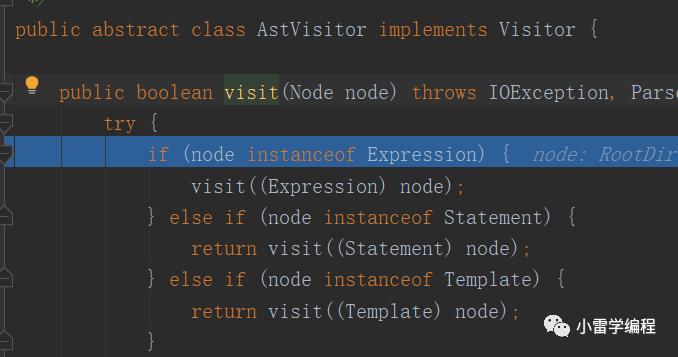
我们可以看到进去之后会直接调用visitor.visit(this),在进去走visit方法,也就是如上图方法,那么这里的this是什么,其实就是刚刚rootDirective,这里就是访问者模式比较怪异的地方,抽象Node对象会准备一个accept方法接收访问者,而该方法会直接调用型参访问者对象的visit方法,传this,其实这里已经是访问者模式的精髓了,访问者模式访问者提供具体处理功能方法,被访问者对象只需要提供需要被处理的哪些功能,我们继续。
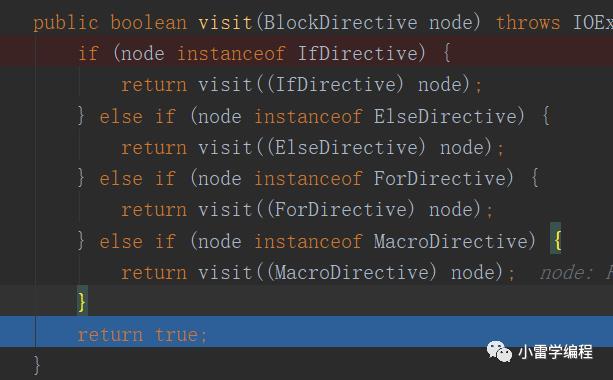
因为root节点不需要处理,所以直接返回true,到这里我们一级一级返回,
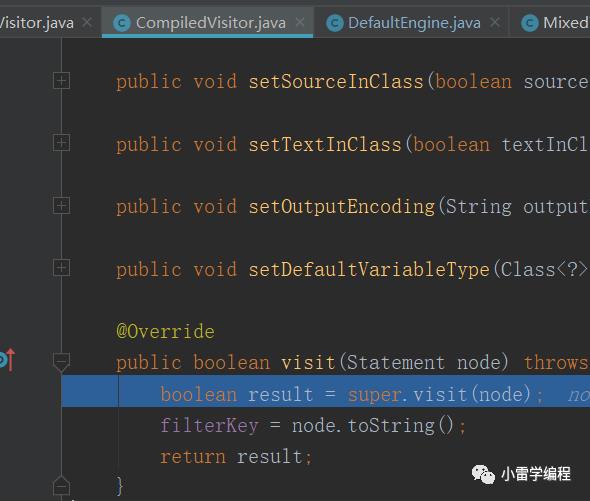
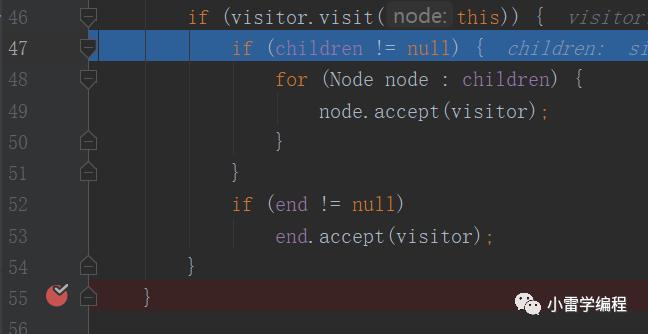
46行返回true会走到47行代码,继续往下,会递归遍历,走到49行代码
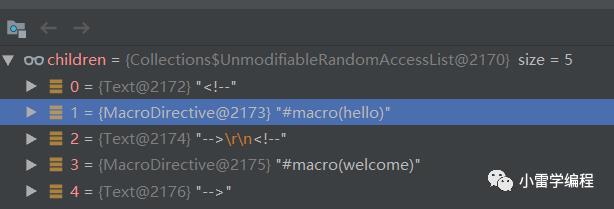
我们以其中一个Text指令为例说明,继续
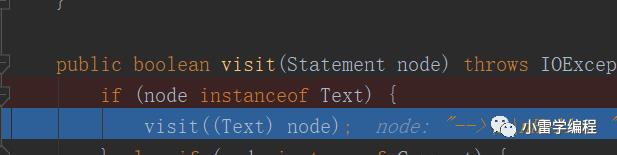
这里会调用compiledVisitor的对应型参的指定方法如下
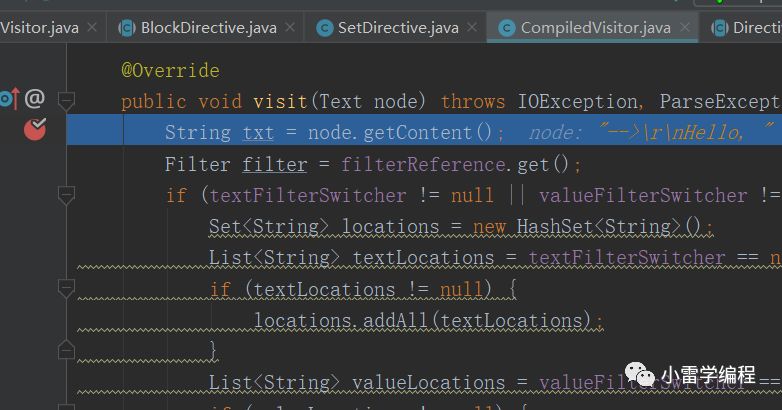
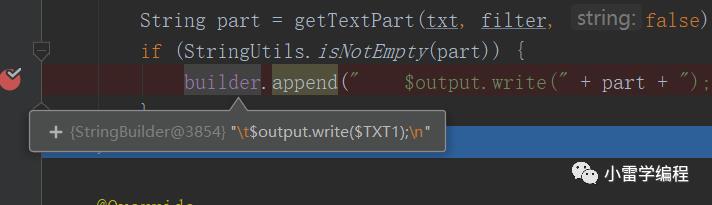
最后会生成一段字符串存入CompileVisitor的全局变量StringBuilder内,这只是其中一个节点的处理,这不是重点我们跳过,节点(#marco)处理完就可以开始预编译流程了,预编译会调用CompileVisitor.compile方法
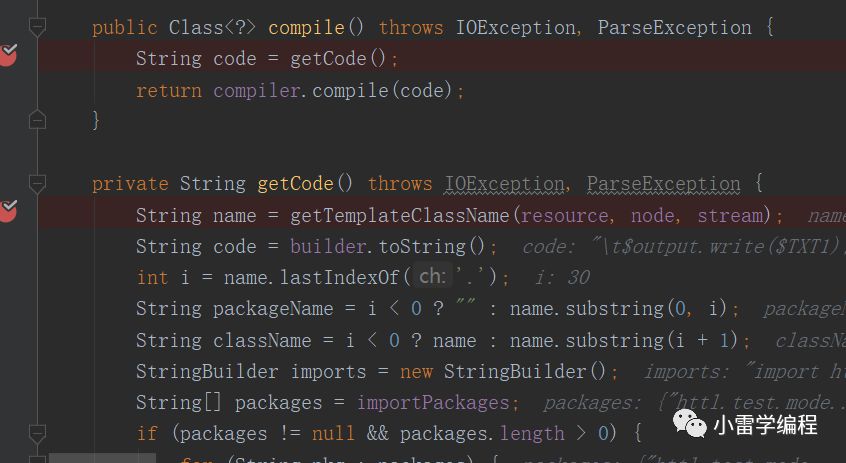
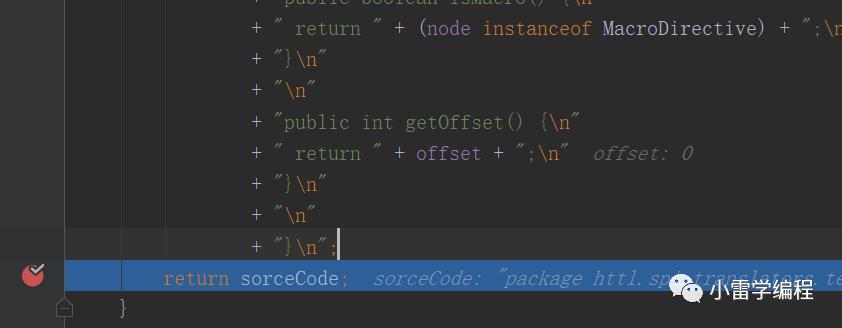
package httl.spi.translators.templates;import httl.test.model.*;import httl.test.method.*;import java.util.*;import httl.*;import httl.util.*;public final class Template__macros_hello_httl_hello_comment_UTF_8_1580988759389_writer extends httl.spi.translators.templates.WriterTemplate {private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[0], new Class[0]);private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[0], new Class[0]);private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[0], new Class[0]);private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[0], new Class[0]);private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[0], new Class[0]);private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final char[] $TXT1 = httl.util.CharCache.getAndRemove("2");private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final String $TXT2 = httl.util.StringCache.getAndRemove("1");private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final char[] $TXT3 = httl.util.CharCache.getAndRemove("3");private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private static final java.util.Map $VARS = new httl.util.OrderedMap(new String[] {"name"}, new Class[] {java.lang.String.class});private final httl.spi.methods.TypeMethod $httl_spi_methods_TypeMethod;private final httl.spi.methods.CodecMethod $httl_spi_methods_CodecMethod;private final httl.spi.methods.LangMethod $httl_spi_methods_LangMethod;private final httl.spi.methods.FileMethod $httl_spi_methods_FileMethod;private final httl.spi.methods.MessageMethod $httl_spi_methods_MessageMethod;public Template__macros_hello_httl_hello_comment_UTF_8_1580988759389_writer(httl.Engine engine, httl.spi.Interceptor interceptor, httl.spi.Compiler compiler, httl.spi.Switcher filterSwitcher, httl.spi.Switcher formatterSwitcher, httl.spi.Filter filter, httl.spi.Formatter formatter, httl.spi.Converter mapConverter, httl.spi.Converter outConverter, java.util.Map functions, java.util.Map importMacros, httl.Resource resource, httl.Template parent, httl.Node root) {super(engine, interceptor, compiler, filterSwitcher, formatterSwitcher, filter, formatter, mapConverter, outConverter, functions, importMacros, resource, parent, root);this.$httl_spi_methods_TypeMethod = (httl.spi.methods.TypeMethod) functions.get(httl.spi.methods.TypeMethod.class);this.$httl_spi_methods_CodecMethod = (httl.spi.methods.CodecMethod) functions.get(httl.spi.methods.CodecMethod.class);this.$httl_spi_methods_LangMethod = (httl.spi.methods.LangMethod) functions.get(httl.spi.methods.LangMethod.class);this.$httl_spi_methods_FileMethod = (httl.spi.methods.FileMethod) functions.get(httl.spi.methods.FileMethod.class);this.$httl_spi_methods_MessageMethod = (httl.spi.methods.MessageMethod) functions.get(httl.spi.methods.MessageMethod.class);}protected void doRenderWriter(httl.Context $context, java.io.Writer $output) throws java.lang.Exception {httl.spi.Filter $filter = getFilter($context, "filter");httl.spi.Filter filter = $filter;httl.spi.formatters.MultiFormatter $formatter = getFormatter($context, "formatter");httl.spi.formatters.MultiFormatter formatter = $formatter;java.lang.String name = (java.lang.String) $context.get("name");$output.write($TXT1);$output.write(doFilter(filter, $TXT2, formatter.toString($TXT2, name)));$output.write($TXT3);}public String getName() {return "/macros/hello.httl#hello";}public java.util.Map getVariables() {return $VARS;}protected java.util.Map getMacroTypes() {return new httl.util.OrderedMap(new String[0], new Class[0]);}public boolean isMacro() {return true;}public int getOffset() {return 0;}}
最后生成的字节码预编译类对应#marco指令如上
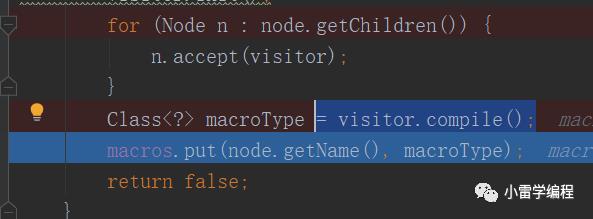
生成之后会缓存起来直接返回
到这里基本就完了,最终会生成对应的模板类
(Template__macros_hello_httl_hello_comment_UTF_8_1580988759389_writer),然后就准备开始渲染流程了,渲染的过程是根据运行时数据填充到预编译类里边之后,把内存的值,渲染到模板中替换,最后调用对应运行的是模板的render方法如下
生成的模板类在内存中进行渲染,263行代码。(这里UnsafeByteStream去掉了无用锁,由HTTL提供)
总结一下:
通过这么久代码调试我们可以了解到AST的基本流程,HTTL是比较典型的案例,当然在Druid里边也会有但是较复杂,另外编译引擎在解析一门编程语言的时候,基本流程都是开篇的那个图,除了AST之外我们还讲到了访问者的设计模式用于访问AST,以及词法分析器的分词工作,类比FastJson,用的都是状态机模式,Pattern也可以做但是不太方便,所以看完本篇文章之后应该对AST有一个简单的场景认识。
以上是关于编译器"吸星大法"之抽象语法树(AST)的主要内容,如果未能解决你的问题,请参考以下文章