一致性哈希算法那点事
Posted 程序员共读
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希算法那点事相关的知识,希望对你有一定的参考价值。
关键时刻,第一时间送达!
在维基百科中,一致性哈希算法是这么定义的:
一致哈希是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
上篇文章介绍了普通Hash算法的劣势,即当node数发生变化(增加、移除)后,数据项会被重新“打散”,导致大部分数据项不能落到原来的节点上,从而导致大量数据需要迁移。
那么,一个亟待解决的问题就变成了:当node数发生变化时,如何保证尽量少引起迁移呢?即当增加或者删除节点时,对于大多数item,保证原来分配到的某个node,现在仍然应该分配到那个node,将数据迁移量的降到最低。
一致性Hash算法的原理是这样的:
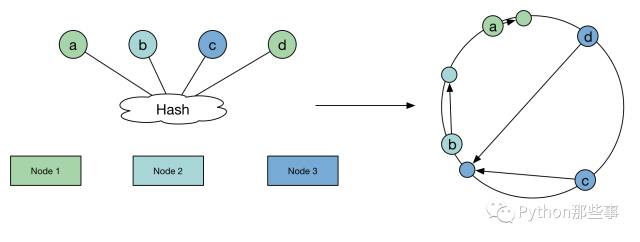
可以看一下当增加Node节点时数据移动量:
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000
NODES = 100
NEW_NODES = 101
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
new_ring = []
for n in range(NODES):
ring.append(_hash(n))
ring.sort()
for n in range(NEW_NODES):
new_ring.append(_hash(n))
new_ring.sort()
change = 0
for item in range(ITEMS):
h = _hash(item)
n = bisect_left(ring, h) % NODES
new_n = bisect_left(new_ring, h) % NEW_NODES
if new_n != n:
change += 1
print("Change: %d (%0.2f%%)" % (change, change * 100.0 / ITEMS))
运行的结果如下:
Change: 235603(2.36%)
虽然一致性Hash算法解决了节点变化导致的数据迁移问题,但是,我们回过头来再看看数据项分布的均匀性,进行了一致性Hash算法的实现。Python代码如下:
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000
NODES = 100
node_stat = [0 for i in range(NODES)]
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
hash2node = {}
for n in range(NODES):
h = _hash(n)
ring.append(h)
ring.sort()
hash2node[h] = n
for item in range(ITEMS):
h = _hash(item)
n = bisect_left(ring, h) % NODES
node_stat[hash2node[ring[n]]] += 1
_ave = ITEMS / NODES
_max = max(node_stat)
_min = min(node_stat)
print("Ave: %d" % _ave)
print("Max: %d (%0.2f%%)" % (_max, (_max - _ave) * 100.0 / _ave))
print("Min: %d (%0.2f%%)" % (_min, (_ave - _min) * 100.0 / _ave))
运行结果如下:
Ave: 100000
Max: 596413(496.41%)
Min: 103(99.90%)
这结果简直是简直了,确实非常结果差,分配的很不均匀。我们思考一下,一致性哈希算法分布不均匀的原因是什么?从最初的1000w个数据项经过一般的哈希算法的模拟来看,这些数据项“打散”后,是可以比较均匀分布的。但是引入一致性哈希算法后,为什么就不均匀呢?数据项本身的哈希值并未发生变化,变化的是判断数据项哈希应该落到哪个节点的算法变了。
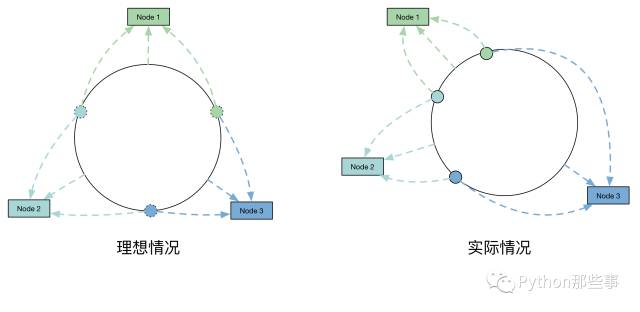
因此,主要是因为这100个节点Hash后,在环上分布不均匀,导致了每个节点实际占据环上的区间大小不一造成的。
那么如何解决这个问题呢?虚节点闪亮登场。通过增加虚节点的方法,使得每个节点在环上所“管辖”更加均匀。这样就既保证了在节点变化时,尽可能小的影响数据分布的变化,而同时又保证了数据分布的均匀。也就是靠增加“节点数量”加强管辖区间的均匀。
下面看一下引入虚节点后数据分布,Python代码如下:
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000
NODES = 100
VNODES = 1000
node_stat = [0 for i in range(NODES)]
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
hash2node = {}
for n in range(NODES):
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring.append(h)
hash2node[h] = n
ring.sort()
for item in range(ITEMS):
h = _hash(str(item))
n = bisect_left(ring, h) % (NODES*VNODES)
node_stat[hash2node[ring[n]]] += 1
_ave = ITEMS / NODES
_max = max(node_stat)
_min = min(node_stat)
print("Ave: %d" % _ave)
print("Max: %d (%0.2f%%)" % (_max, (_max - _ave) * 100.0 / _ave))
print("Min: %d (%0.2f%%)" % (_min, (_ave - _min) * 100.0 / _ave))
运行的结果如下:
Ave: 100000
Max: 116902(16.90%)
Min: 9492(90.51%)
同时,观察增加节点后数据变动情况,可以分析如下:
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000
NODES = 100
NODES2 = 101
VNODES = 1000
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
hash2node = {}
ring2 = []
hash2node2 = {}
for n in range(NODES):
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring.append(h)
hash2node[h] = n
ring.sort()
for n in range(NODES2):
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring2.append(h)
hash2node2[h] = n
ring2.sort()
change = 0
for item in range(ITEMS):
h = _hash(str(item))
n = bisect_left(ring, h) % (NODES*VNODES)
n2 = bisect_left(ring2, h) % (NODES2*VNODES)
if hash2node[ring[n]] != hash2node2[ring2[n2]]:
change += 1
print("Change: %d (%0.2f%%)" % (change, change * 100.0 / ITEMS))
运行结果如下:
Change: 104871(1.05%)
从运行结果看,引入虚节点之后,数据分布很均匀,同时,增加Node节点后移动的数据量较少。
今天,你理解了一致性哈希算法的精要了吗?高考日,让我们一起怀念那走过的岁月,祝福参加高考的学子进入梦想的学校吧!
来自:微博,网络
程序员共读整理发布,转载请联系作者获得授权
以上是关于一致性哈希算法那点事的主要内容,如果未能解决你的问题,请参考以下文章