Ceph杀手锏CRUSH和主流分布式存储一致性哈希算法
Posted 云技术之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ceph杀手锏CRUSH和主流分布式存储一致性哈希算法相关的知识,希望对你有一定的参考价值。
1. 引言
在当前云计算推广如日中天的时代,企业和个人每天都会产出大量的数据,数据做为企业和组织的最宝贵资产,海量数据对后端存储的弹性伸缩能力、敏感数据的安全性、可靠性、一致性以及存储系统的IOPS和吞吐量有了更高的要求。江湖传闻:“武林至尊,宝刀屠龙,号令天下,莫敢不从”。于是江湖中有代表性的几大门派召集武林人士聚集“光明顶”,向昔日霸主索取宝刀,为了劝退群雄,霸主被逼无奈只好交出练就宝刀的三大秘籍(Google FS、MapReduce、BigTable)。各英雄豪杰下山后,结合各自的内功心法潜心修炼,数载后,江湖中涌现了一批新的门派,比如Hadoop、Ceph、Swift、SheepDog、GlusterFS、LeoFS,主要包含中心化和非中心化两大门派,其中非中心化门派的两个独门心法:CRUSH和一致性哈希因为没有元数据中心节点而备受推崇。下面逐个分析下存储江湖中的两个独门心法。
2. Ceph CRUSH算法原理及源码分析
2.1基本概念
CRUSH:全称是“Controlled Replication Under Scalable Hashing”,主要用来计算Object在Ceph集群中的存储位置。在中心化的分布式存储架构中,一般采用Master节点来存储数据的具体位置信息,这样会有单点故障(SPOF)。而Ceph采用CRUSH算法来高效的计算关于数据位置的信息,节点都是对称结构。Crush 核心作用:
1)可以均衡数据到集群中的各个OSD节点。
2)当增加或减少机器数量,可以大大减少Ceph集群数据迁移量。
Pools:pools是数据的逻辑存储池,PG数量需要根据OSD数量和副本数量合理设定,设定好后,尽量不要轻易变动PG数量,避免大量数据均衡影响Ceph正常读写性能。
[root@OpenStack ~]# ceph osd pool create test-pool 1024 //创建pool会填写PG数量
[root@OpenStack ~]# ceph osd pool set test-pool size 3 //设置pool的副本数
[root@OpenStack ~]# ceph osd pool get test-pool size //查询pool的副本数
size: 3
Object:不论是块存储、对象存储还是文件存储,最终都是以Object形态存储在磁盘上。
PG:相当于一致性哈希算法里的虚拟节点,做为Object的归置组。
OSD:真正的存储组件,OSD一般和磁盘一一对应,处理存储磁盘上的读/写操作。
2.2 CRUSH上传文件流程
通过客户端上传一个文件到Ceph集群中的指定pool中,不论是RBD、RGW还是CephFS,因为底层都是对象存储。总共分为如下几个步骤:
1)切分文件为Object:首先,客户端会对文件进行数据分片,把大文件拆分为多个Object。例如,假定每个Object大小为8MB,一个1GB的文件可以被拆分成 128个Object。(1024MB / 8MB)如下图所示:
2)计算Object对应PG:对Object进行Hash, 然后哈希值和 PG的数量取余,得到的值再和pool的ID拼接成PG_ID。如下图所示:
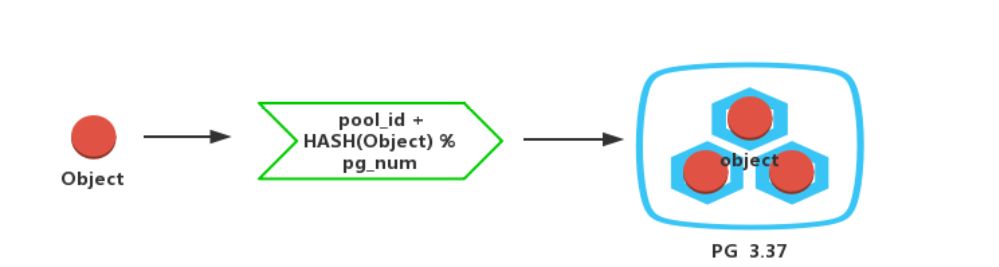
pg_id计算公式:pg_id = pool_id + HASH(Object) % pg_num
例如pg_id = 3.37 表示pool_id为3,Object哈希值取余后为0X37。
[root@OpenStack ~]# ceph osd lspools //下面左侧的数字就是pool_id
1 images
2 volumes
3 vms
4 cephfs_data
5 rbd
[root@OpenStack ~]# ceph pg ls-by-pool vms //查询指定pool下pg和Object分布情况

3) 计算PG对应的OSD集合:对pg_id进行CURSH得到该PG对应的OSD数组。如下图所示:
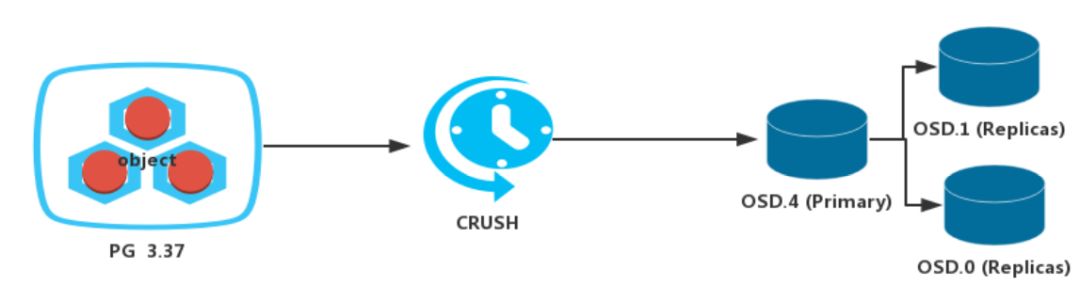
计算公式:OSD-ids = CRUSH(PG-id,cluster-map, cursh-rules)。
如果设置Object的副本数为3,则返回3个OSD。
[root@OpenStack ~]# ceph pg map 3.37 //查看PG对应的OSD集合
osdmap e866 pg 3.37 (3.37) -> up [4, 0,1] acting [4, 0, 1]
//osd.4是Primary,osd.0和osd.1是Replicas
2.3 Ceph 客户端读写流程
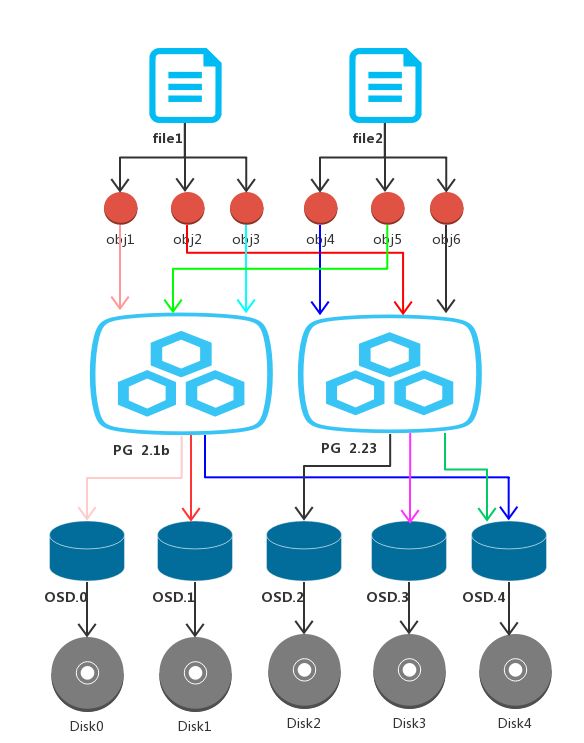
数据在Ceph集群的读写路径是:file-> (Pool, Object) → (Pool, PG) → OSD→Disk,对应关系如下图所示:
2.4 Ceph CRUSH核心源码
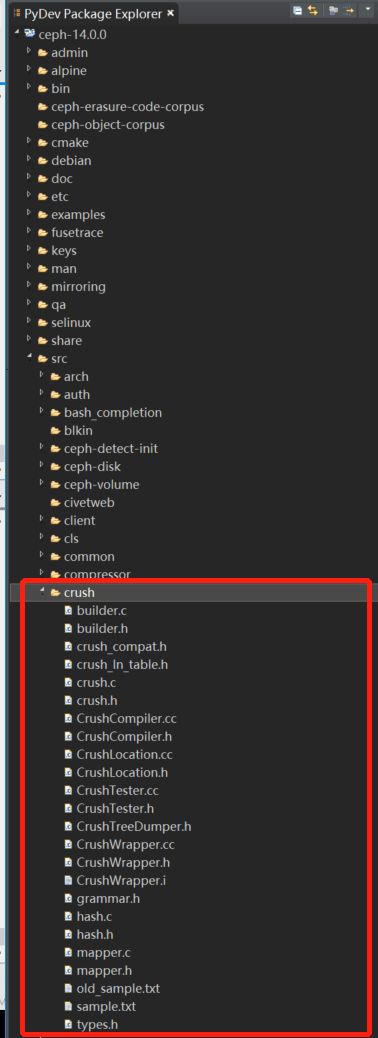
本文源码基于ceph-14.0.0版本,ceph主要是由C++和C编写的,代码结构整体还是比较清爽。其中CRUSH的源码主要集中在如下目录:
核心源码调用关系如下:
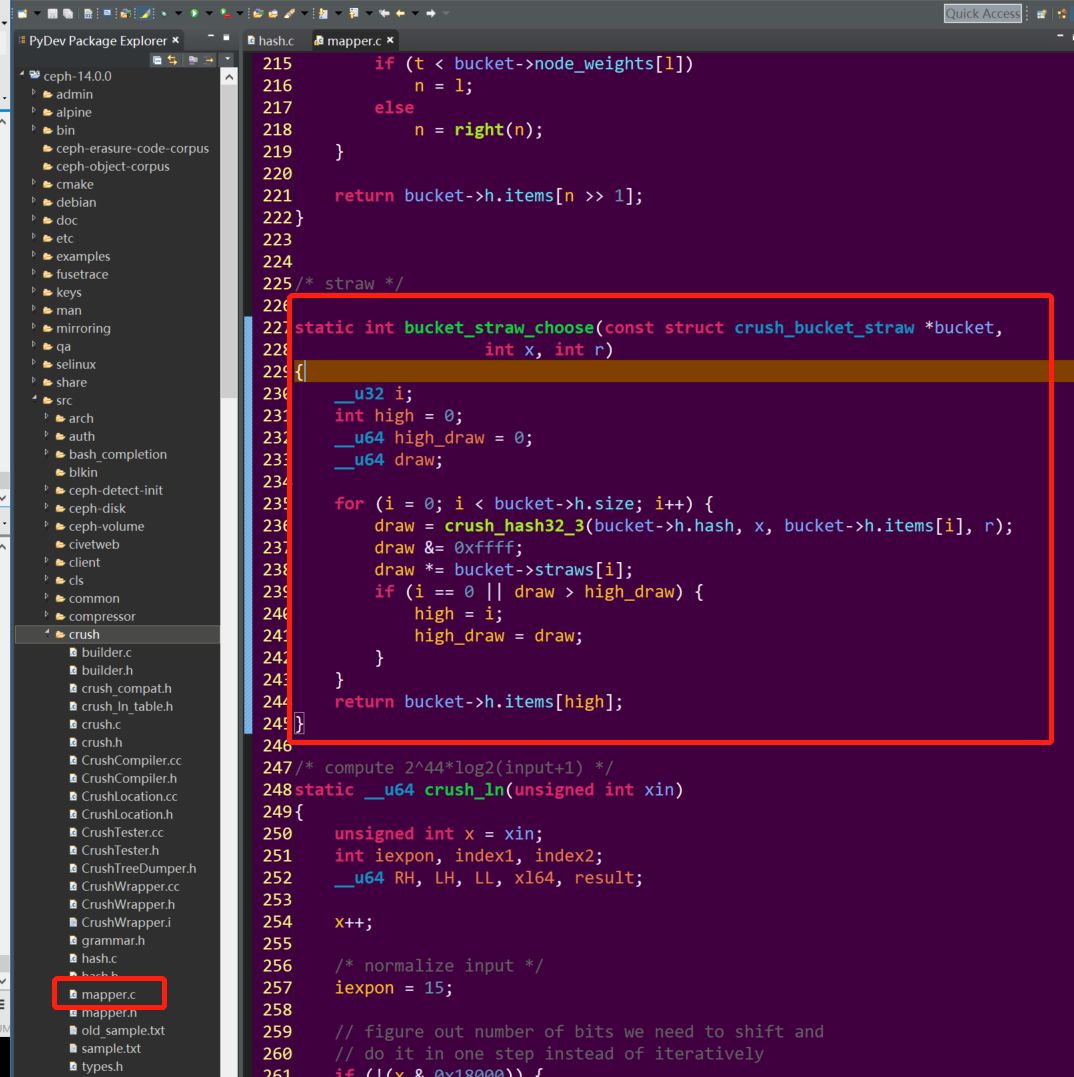
mapper.c源文件:
hash.c 源文件:
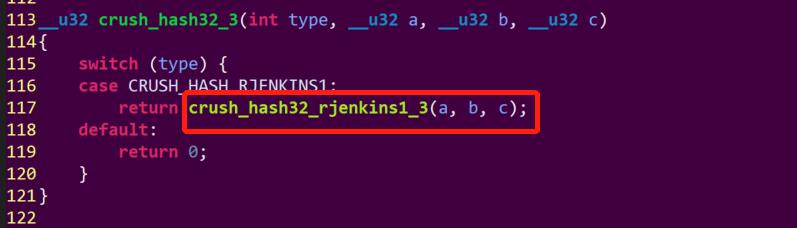
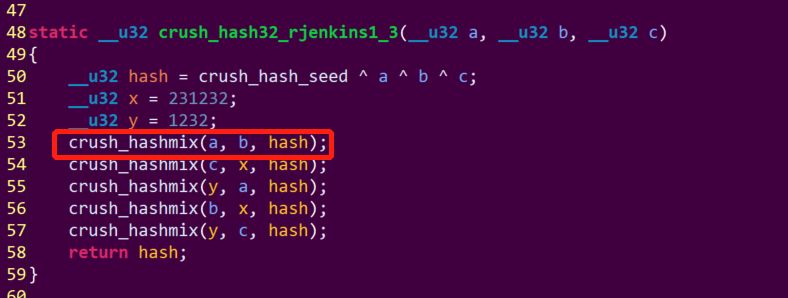
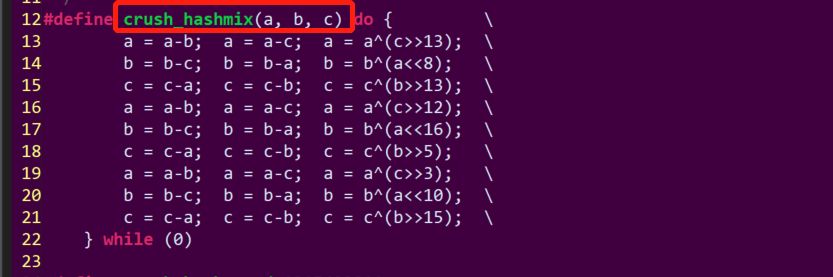
从代码上可以看出,通过对可选bucket集合、PG_ID和随机数r进行hash, 参数相同情况下,每次的计算结果肯定也是相同的,意味着相同PG_ID存储OSD的位置不变。如果想要获取多个副本的osd集合,可以通过r参数的变化来获取。
3. 一致性哈希算法(Consistent Hashing)
先简单了解下一致性哈希算法(ConsistentHashing),和CRUSH算法有共同之处。一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,目前采用一直性哈希算法的主要有OpenStack的Swift对象存储、亚马逊的DynamoDB 、SheepDog、LeoFS等分布式存储。
在分布式存储中,如何快速定位数据的存储位置,想必大家头脑中第一个想法就是hash(object)%N算 法。普通哈希算法弊端:弹性伸缩节点数量是再也正常不过的事情了。如果利用普通hash(object)%N算 法,在机器数量N发生变动后,原来数据的位置计算会错乱,该算法肯定不可取。
3.1 方案1
1)将存储节点的IP通过hash算法映射到环上
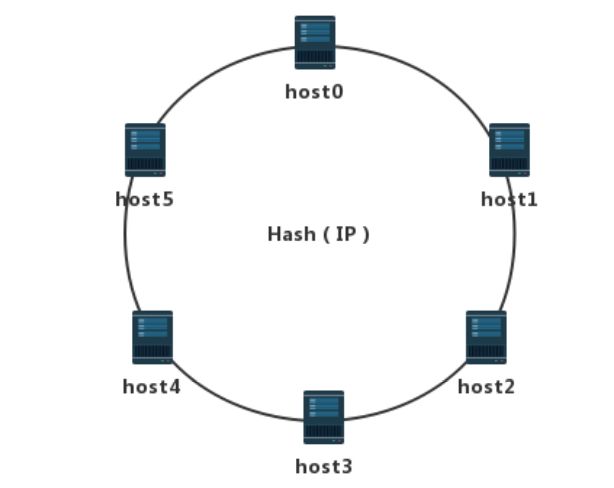
以6个节点的集群做个简单的示例,节点名称分别为:host0、host1、host2、host3、host4、host5。分别对每个节点IP进行Hash来计算各自在环中的逻辑分布位置。节点分布示意图如下:
2)把数据通过hash算法处理后映射到环上
同样我们通过Hash算法分别计算六个对象:obj0、obj1、obj2、obj3、obj4、obj5的逻辑位置并映射到环上,此时对象和节点都分布到了相同的环上。对象存储位置分布如下图,那如何才能知道对象具体的存储位置呢?我们定一个规则:以对象为参照物顺时针旋转,第一个碰到的节点就做为该对象的真实存储位置。这样obj0存储在host5中,obj1存储在host1中,obj2存储在host4中,obj3存储在host0中,obj4存储在host3中,obj5存储在host2中。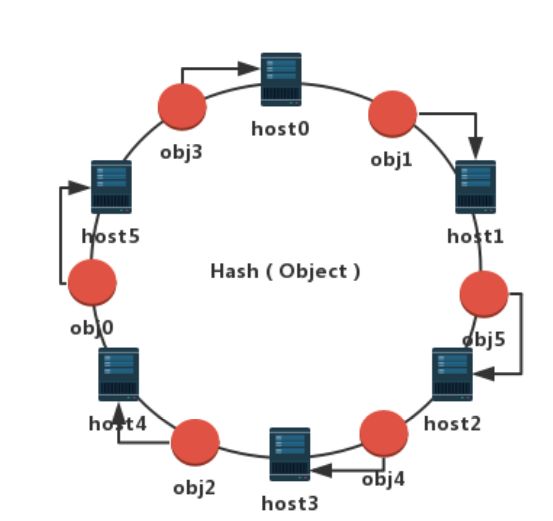
下面我们检验下该算法在节点数量变化的情况下,存储集群数据是否还能正常进行读写操作?集群节点数量变动无非两种场景:
1)节点由于故障需要从集群移出
我们不妨把host4移除掉,如下图所示:
按照上面定的顺时针规则,发现只有原来处于host3和host4之间的数据(即obj2)需要迁移,obj2被迁移到了离他顺时针最近的节点host5上。可见,减少集群节点数量,只有少量数据发生迁移,大部分数据位置不变。集群还是可以正常进行读写。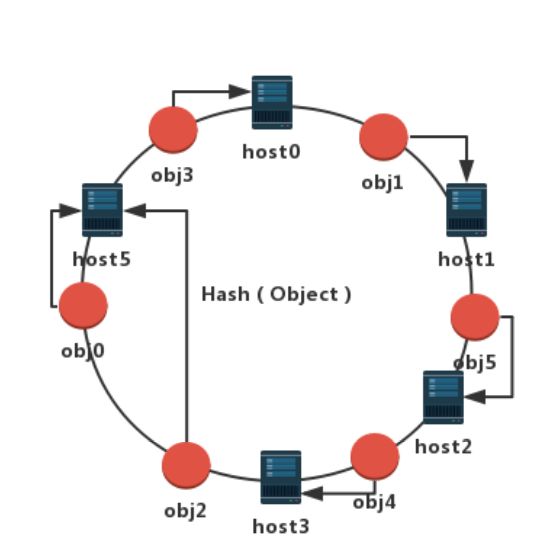
2)存储数据业务量上升,集群需要扩容节点
我们项集群增加一个节点host6并通过Hash映射到环上,位于host1和host2之间,如下图所示:同样按照上面定的顺时针规则,发现只有处于host1和host6之间的数据(即obj5)需要迁移,obj5被迁移到了离他顺时针最近的新节点host6上。可见,增加集群节点数量,只有少量数据发生迁移,大部分数据位置不变。集群同样可以正常进行读写。
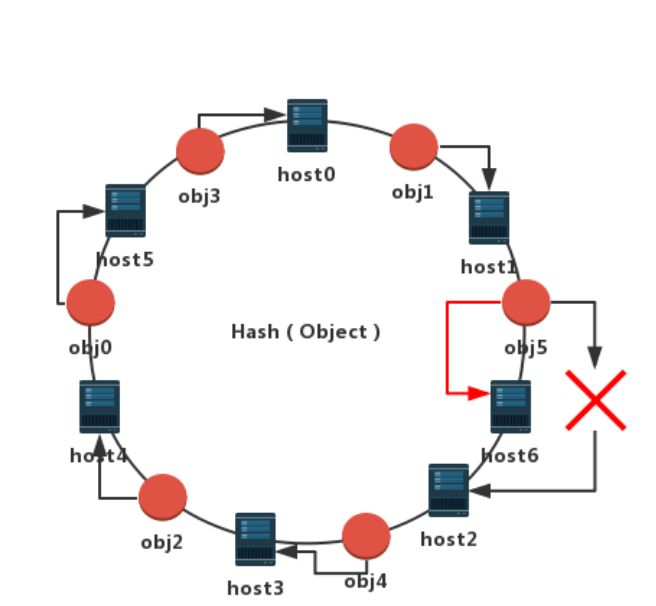
综上,在节点数量发生变化的场景下,该算法可以保证只有少量的数据位置会发生迁移,显著减轻了集群变化可能引发的数据迁移的负载。
那上述算法是不是很完美了?仔细分析后,如果节点数量较少,很有可能导致obj的分布不均衡。如果集群的节点非常多,host和obj在环上的分布就会逐步均衡。那怎么才能使host节点数量达到一定的量级呢,总不至于真的添加大量物理服务器吧。请看下面的改进方案,可以很好的解决这个问题。
3.2 改进方案2(最终的一致性哈希算法)
在方案1的基础上,为了解决数据分布均衡,在数据和物理节点之间增加了一层虚拟节点的逻辑概念。一个物理节点对应多个虚拟节点。物理节点和虚拟节点在环外通过Hash映射对应关系,虚拟节点和obj映射在环上。数据的存储映射关系实质是:obj->虚拟节点->物理节点。Obj在大量虚拟节点分布会相对均衡,当然在物理节点上数据也会均衡分布。最后对象映射的关系图如下:
4. 总结及建议
Crush和一致性哈希算法是分布式存储的两大法宝,掌握好它就相当于深入到了分布式存储的灵魂,可以加快学习其他存储产品的步伐。但是也需要注意以下事项:
1)提前规划好存储集群,除非逼不得已,尽量不要随便频繁变动集群配置,目前开源的技术方案没有你想象的那么健壮。
2)当集群中有节点挂掉的时候,还是要及时通过监控告警来通知到维护人员,一旦遇到自动恢复不了的情况,需要及时手动干预恢复,避免导致大量节点宕机导致大量数据均衡,形成恶性循环。
3)向集群添加或删除节点时候,尽量逐台添加或删除,不要一次增加(删除)大量节点,减少集群数据均衡带来的负载压力。
杨武 新钛云服研发总监,十年云研发和架构经验,中国科学技术大学软件工程全日制硕士研究生学历。曾在IBM、土豆网、微烛云先后担任云计算研发工程师、架构师,技术总监等职务,参与并主导过产品设计、研发、测试和运维(DevOps)等完整产品生命周期流程,有上万台物理服务器规模的OpenStack集群架构实战经验,对云平台的瓶颈和性能优化有丰富经验。精通OpenStack、CloudForms、Kubernetes、Ceph、KVM、Docker、Solaris(SmartOS)等云平台及虚拟化技术。
↓↓ 点击"阅读原文" 【加入云技术社区】
相关阅读:
更多文章请关注
以上是关于Ceph杀手锏CRUSH和主流分布式存储一致性哈希算法的主要内容,如果未能解决你的问题,请参考以下文章