缓存与一致性哈希
Posted 百果科技研发团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存与一致性哈希相关的知识,希望对你有一定的参考价值。
缓存与一致性哈希
前言
缓存是分布式系统中的重要组件,主要解决高并发,大数据场景下,热点数据访问的性能问题。提供高性能的数据快速访问。
伸缩性
考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是值得考虑的,尤其实在设计分布式缓存系统时,如果某台服务器失效,对于整个系统来说如果不采用合适的算法来保证一致性,那么缓存于系统中的所有数据都可能会失效(即由于系统节点数目变少,客户端在请求某一对象时需要重新计算其 hash 值(通常与系统中的节点数目有关),由于 hash 值已经改变,所以很可能找不到保存该对象的服务器节点)。
余数哈希算法

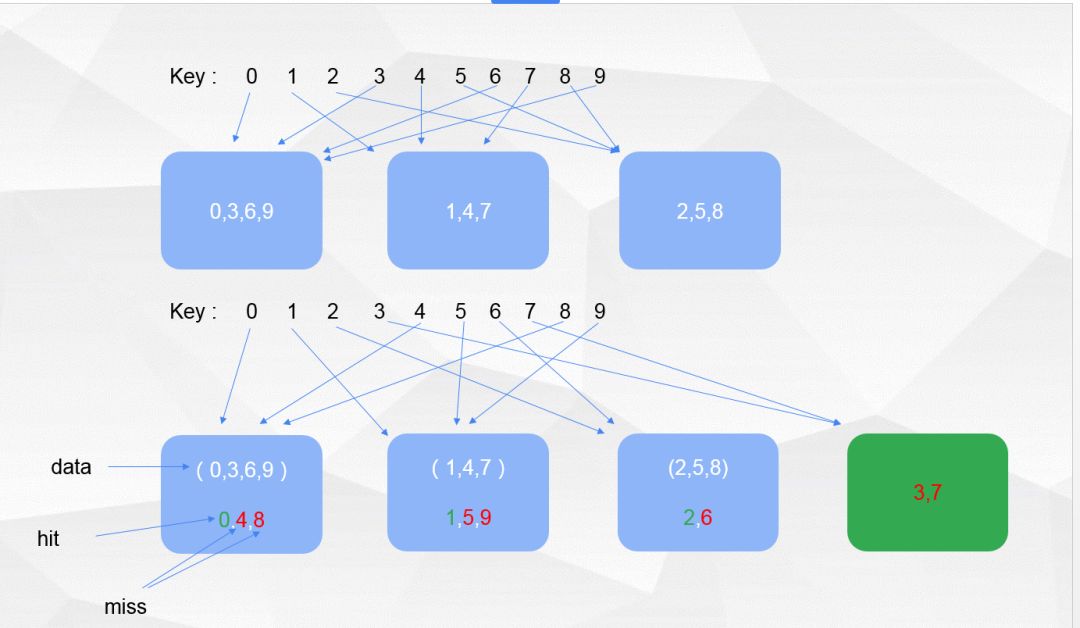
现在我们假设有 n 台 redis 服务器,一份数据a进来的时候,以散列公式 hash(a)%n,计算所存放的服务器,假设 hash(a)%n = i ,那么数据被散列到标号为 1 的服务器,
然后这个时候服务器新增了一台,然后散列公式为 hash(a)%(n+1),这个时候请求访问数据a的时候,被分配至 2 号服务器,但是其实这个时候数据是在 1 号服务器的。如上图所示,这个时候会有大量数据丢失(访问不到了)所以这个时候,我们假设是新增了服务器,如果是持久化存储的,我们可以让服务器集群对数据进行重新散列,进行数据迁移,然后重新预热恢复数据。但是这样意味着每次增减服务器的时候,集群就需要大量的通信和数据迁移,这个开销是非常大的。而且当如果大量缓存失效时,请求会直接落到数据库上,造成突然的数据库压力大增,甚至造成宕机引起不可预测的后果。因此关键在于,服务器数量变动的时候,要能够保证命中丢失率足够低。
一致性哈希算法
业界流行的解决方案
一致性哈希算法 (Consistent Hashing) 最早在论文 《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》 中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为 0-2^32-1(即哈希值是一个 32 位无符号整形,若哈希算法的值超过 2^32 ,就除以 2^32 取余数)。
接下来使用如下算法定位数据访问到相应服务器:将数据 key 使用相同的函数 Hash 计算出哈希值,并确定此数据在环上的位置,对应的访问服务器位置就是顺时针的遇到的第一台服务器。
假设我们有 K1~K7 7个数据,哈希后映射的位置如下:
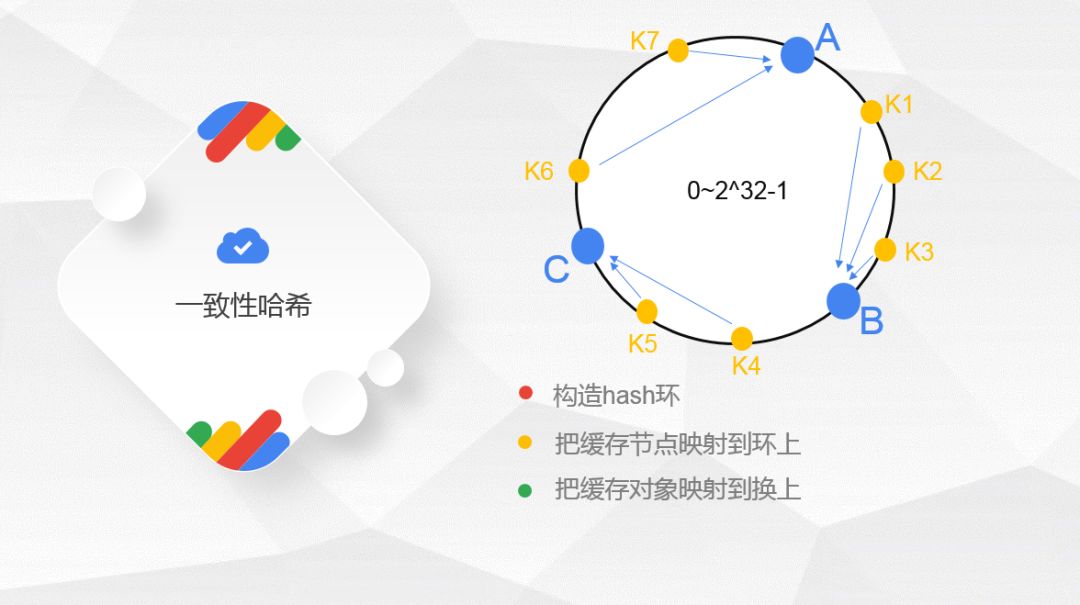
根据一致性哈希算法,数据 K1~K3 会被定为到 Node B上,K4~K5 被定为到 Node C上,K6~K7 被定为到 Node A 上。
下面分析伸缩性问题:
蓝线为宕机或者扩展前的数据-节点映射路线,绿线为宕机或者扩展后的映射路线,红线为原来的蓝线在宕机或扩展后的失效路线。
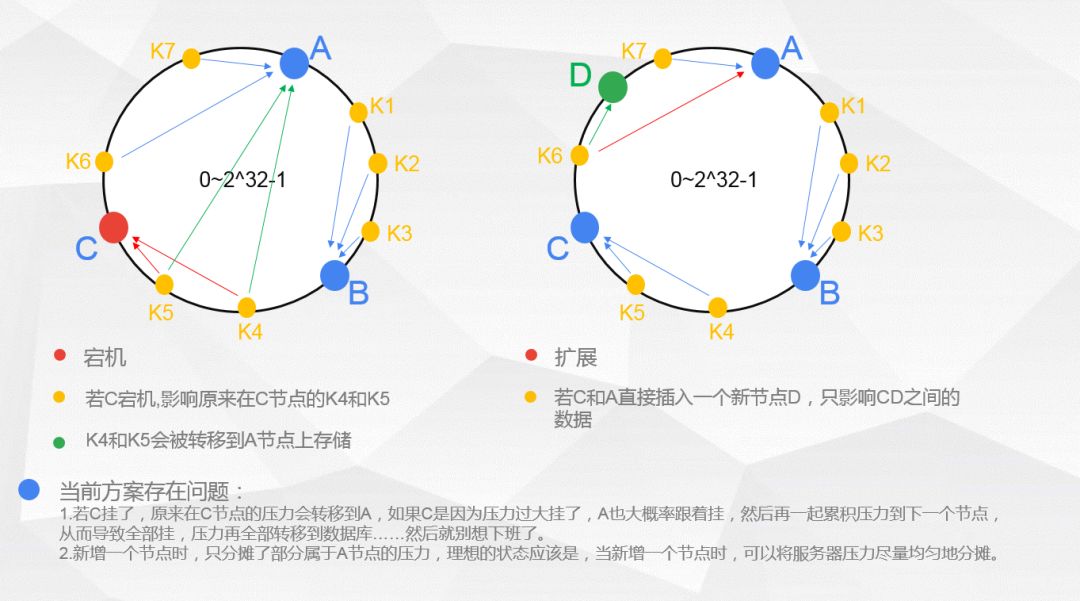
为了解决上述方案存在的问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,例如将节点 A 映射为 “VA1”、“VA2”、“VA3” 三个虚拟节点,此处 ABC 三台机子映射为9个虚拟节点(实际运用中虚拟节点数量会远大于这个数,具体可以自己测试最优数量。一般经验值为150左右)。
总结
通过这种算法做数据分布,在增减节点的时候,可以大大减少数据的迁移规模,提高系统稳定性。
参考文档
《大型网站技术架构—核心原理与案例分析》 李智慧著 电子工业出版社
《深入分布式缓存—从原理到实践》 于君泽,曹洪伟,邱硕等著 机械工业出版社
END
致力于提供更好的技术
以上是关于缓存与一致性哈希的主要内容,如果未能解决你的问题,请参考以下文章