一致性哈希的简单介绍!!!!
Posted 烟草的香味
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希的简单介绍!!!!相关的知识,希望对你有一定的参考价值。
分布式经典结构
如图所示的结构, 当前端接收到请求时, 通过计算key的哈希值, 将哈希值模3, 然后分布到不同的后端服务器上
但是, 这样的结构当添加或减少后端服务器时就暴露了问题, 每次添加或减少后端服务器, 放在服务器中的所有数据都要全部重新计算哈希, 将哈希值摸新的台数, 重新添加. 如此, 数据迁移的成本太高了, 由此引出了一致性哈希
一致性哈希
前端服务端结构不变, 以下都是后端服务器.
假设哈希函数计算出的值在 0-2^64 范围内, 将其想想成一个环, 如下:
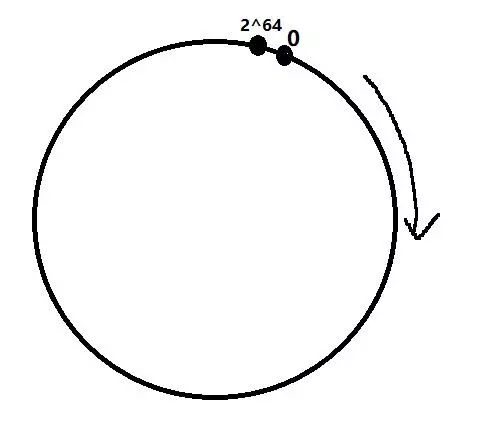
将服务器打在这个环上, 那么服务器也要有一个哈希值, 通过服务器唯一的标志来计算(ip, mac, hostname等), 如下:
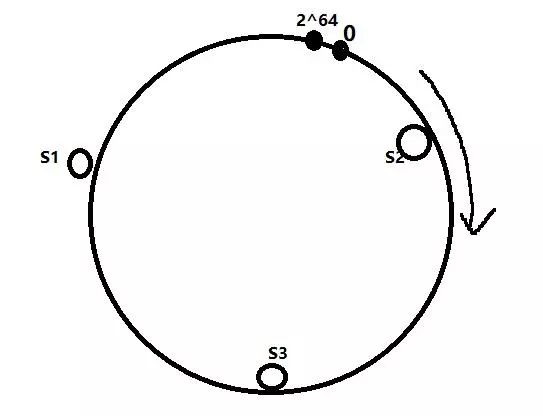
当请求到来时, 计算请求的哈希值, 哈希值定会打在这个环上, 然后将请求发给顺时针找到的第一个服务器, 如下:
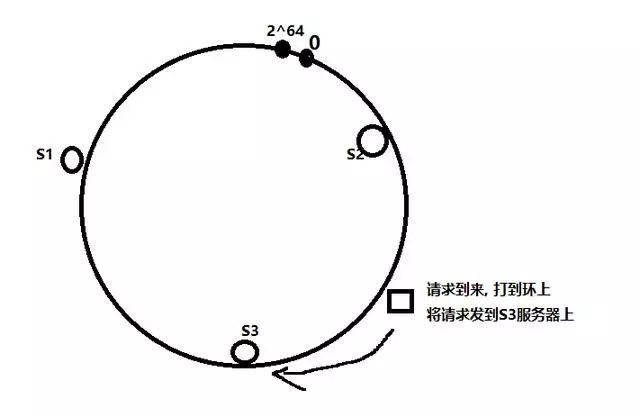
也就是找到比请求哈希值大的第一台服务器.
实现这个结构后, 若是向服务器中添加一台, 只要找到原本负责这个区域的服务器, 然后将应该负责区域的数据拿过来并从原服务器中删除即可, 如下:
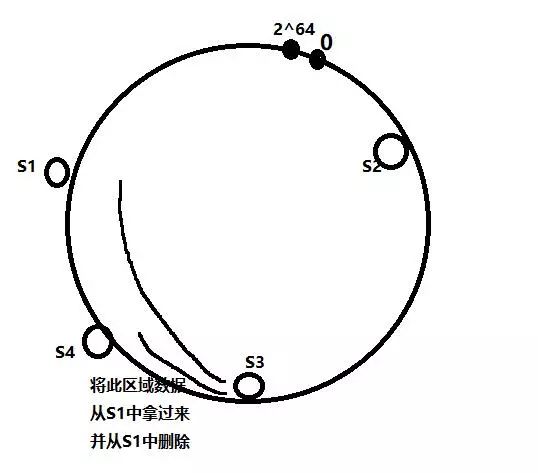
删除一台服务器也是同样的道理
如此一来, 数据的迁移成本确实减少了, 但是新的问题出现的, 数据的均衡性得不到保证, 因为哈希函数计算出的哈希值是随机的, 所以很可能出现两台服务器分布不均的情况:
这时, 大部分数据都是S1负责, 而S2只负责少部分数据, 即使恰巧分布均匀,S1和S2正好打在环的两端, 但是新加一台服务器也势必会破坏均衡:
这样肯定是不行的, 那么如何解决这个问题呢?
这个问题是什么导致的呢? 是因为哈希函数所导致的, 哈希函数是当数据量大的时候, 可以保证均匀的分布, 但是当数据量小的时候并不能保证, 那就让数据量大就好了.
我们给每台服务器分配1万个虚拟节点, 令虚拟节点分布到环上, 服务器负责的区域是这1万个虚拟节点负责区域的总和, 这样计算哈希的时候就保证了数据量, 即保证其哈希值会均匀分布到环上, 问题解决.
以上, 就是一致性哈希的简单介绍!!!
以上是关于一致性哈希的简单介绍!!!!的主要内容,如果未能解决你的问题,请参考以下文章
[ Redis ] 从一致性哈希算法说起,到 RedisCluster 集群的介绍