分布式必须要了解下Consistent-Hash(一致性哈希算法)
Posted java大牛爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式必须要了解下Consistent-Hash(一致性哈希算法)相关的知识,希望对你有一定的参考价值。
前言
在分布式系统中,常常需要使用缓存,而且通常是集群,访问缓存和添加缓存都需要一个 hash 算法来寻找到合适的 Cache 节点。
但,通常不是用取余hash,而是使用我们今天的主角—— 一致性 hash 算法。
今天楼主就来说说这个一致性 hash 算法。
1. 为什么普通的 hash 算法不行?
普通的 hash 算法通常都是对机器数量进行取余,比如集群环境中有 3 台 redis,当我们放入对象的时候,通常是对 3 进行取余。这种做法在大部分情况下是没有问题的。但是,注意:如果缓存机器需要增减,问题就来了。
什么问题呢?
假设原本是 3 个 redis,这时候,加了一台 redis,那么取余算法就变成了取余 4。
这样有什么问题呢?
答:当使用负载均衡的时候,负载均衡器根据对象的 key 对机器进行取余,这个时候,原有的 key 取余现有的机器数 4 就找不到那台机器了!笨一点的办法,就是在增加机器的时候,清除所有缓存,但这会导致缓存击穿甚至缓存雪崩,严重情况下引发 DB 宕机。
2. 一致性 hash 怎么解决这个问题?
很简单,既然问题出在对机器取余上,那么就不对机器取余。
具体怎么做呢?
答:我们可以假设有一个 2 的 32 次方的环形,缓存节点通过 hash 落在环上。而对象的添加也是使用 hash,但很大的几率是 hash 不到缓存节点的。
怎么办呢?找离他最近的那个节点。 比如顺时针找前面那个节点。
能解决问题吗?想象一下:当增减机器时,环形节点变化的只会影响一个节点,就是新节点的顺时针方向的前面的节点。
这个时候,我们只需要清除那一个节点的数据就足够了,不用想取余 hash 那样,清除所有节点的数据。
具体类似于下图:
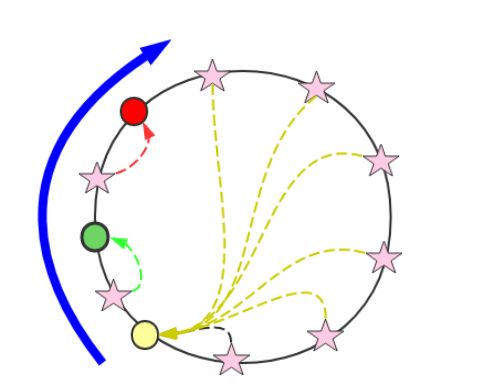
上图中,节点中的五角星代表对象,红绿黄代表节点,每个对象都会找他的上一个节点。如有增减,只影响一个节点。
如下图所示:
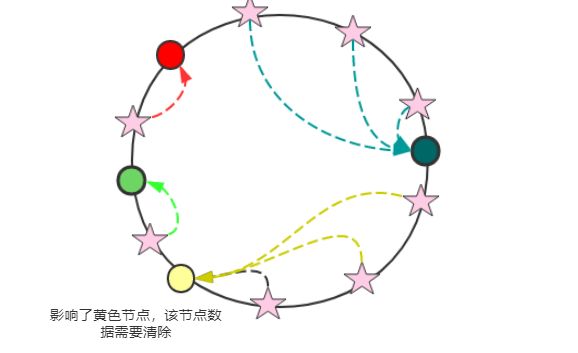
红色和绿色节点不受影响。
3. 一致性 hash 有什么问题呢?
是否这么做就完美了呢?
不是的。
如果认真看是上面的图的话,会发现,黄色节点的负载压力最大,这个集群环境负载不够均衡。
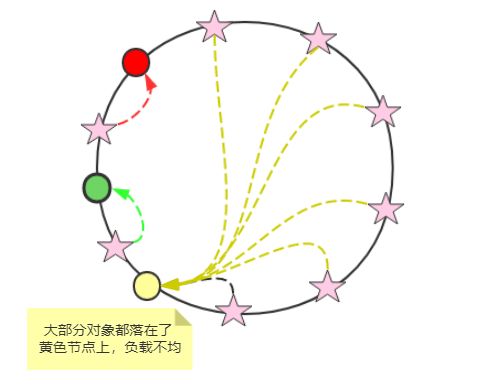
什么原因导致的呢?原因是:如果缓存节点分布不均匀,就会出现这样的情况。但是,你不能奢望是均匀的。
怎么办呢?
我们可以在不均的地方给他弄均匀。在空闲的地方加入 虚拟节点,这些节点的数据映射到真实节点上,就可以了,如下图所示:
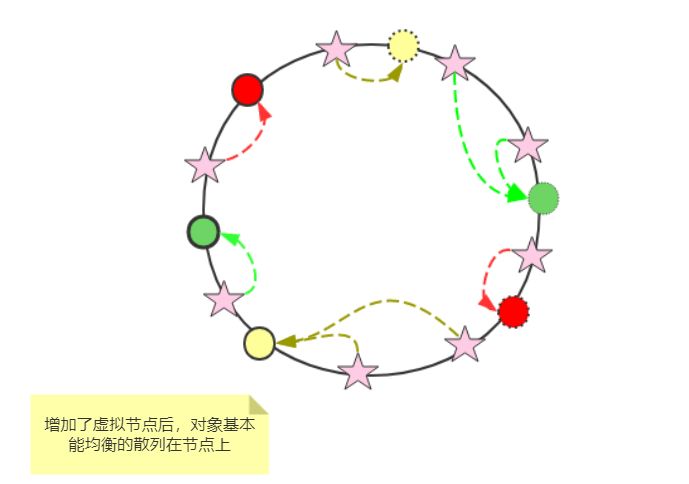
上图中,我们给每个节点都做了虚拟节点(虚线),从而让整个集群在 hash 环比较均匀,从图中也可以看出,这样现对比之前均匀多了,黄色节点的负载和绿色节点额的负载相同。
4. 总结
总的来说,一致性 hash 还是比较简单的。核心思想是,不使用对机器取余的算法。这样就能避免机器增减带来的影响。
同时,使用 就近寻址 的方式找到最近的节点。当然,这会引起负载不均衡,所以需要引入虚拟节点的方式,变相的增加节点,让整个集群的负载能够均衡。
后面,我们将自己写一个一致性 hash 算法以加深印象。
原文:http://thinkinjava.cn/2018/03/
设置星标不迷路

有你想看的精彩

Java大牛爱好者:每天一篇java技术文章,不定时java干货发送
欢迎长按(扫描)二维码关注:java大牛爱好者
【高级java架构师学习资料】-年薪百万不是梦!
【java学习电子书】-从入门到架构!
更多惊喜等你去发现~
以上是关于分布式必须要了解下Consistent-Hash(一致性哈希算法)的主要内容,如果未能解决你的问题,请参考以下文章