一文了解一致性哈希
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文了解一致性哈希相关的知识,希望对你有一定的参考价值。
本文使用软件环境:Java 8
一、数据分布接口定义
概述
在分布式环境下面,我们经常会通过一定的规则来进行数据分布的定义,比如用户1的数据存储到数据库1、用户2的数据存储到数据库2......
一般来说,有这么几种常用的方式:
有一个分布式环境中唯一的中心分发节点,每次在数据存储的时候,都会询问中心节点这个数据该去哪儿,这个分发节点明确告诉这个数据该去哪儿。
通过一定规则产生一个key,对这个key进行一定规则的运算,得出这个数据该去哪儿。本文描述的取模算法和一致性Hash,就是这样一种方式。
接口定义
/*** 数据分布hash算法接口定义* @author xingchuan.qxc**/public interface HashNodeService {/*** 集群增加一个数据存储节点* @param node*/public void addNode(Node node);/*** 数据存储时查找具体使用哪个节点来存储* @param key* @return*/public Node lookupNode(String key);/*** hash的算法* @param key* @return*/public Long hash(String key);/*** 模拟意外情况断掉一个节点,用于测试缓存命中率* @param node*/public void removeNodeUnexpected(Node node);}
(滑动可查看)
二、数据分布算法实现——取模算法
概述
取模算法的应用场景描述如下:
需要在集群中实现一个用户数据存储的负载均衡,集群中有n个存储节点,如何均匀的把各个数据分布到这n个节点呢?
实现步骤大概分成两步:
通过用户的key来取一个hash值
通过这个hash值来对存储节点数n进行取模,得出一个index
上面这个index就是待存储的节点标识
Note:本文例子我生成hash值的方式,我采用CRC32的方式。
代码实现:
/*** 取模数据分布算法实现* @author xingchuan.qxc**/public class NormalHashNodeServiceImpl implements HashNodeService{/*** 存储节点列表*/private List<Node> nodes = new ArrayList<>();public void addNode(Node node) {this.nodes.add(node);}public Node lookupNode(String key) {long k = hash(key);int index = (int) (k % nodes.size());return nodes.get(index);}public Long hash(String key) {CRC32 crc32 = new CRC32();crc32.update(key.getBytes());return crc32.getValue();}public void removeNodeUnexpected(Node node) {nodes.remove(node);}}
(滑动可查看)
通过上述例子我们可以看到,lookupNode的时候,是要先去取这个key的CRC32的值,然后对集群中节点数进行取模得到r,最后返回下标为r的Node。
测试代码如下:
HashNodeService nodeService = new NormalHashNodeServiceImpl();Node addNode1 = new Node("xingchuan.node1", "192.168.0.11");Node addNode2 = new Node("xingchuan.node2", "192.168.0.12");Node addNode3 = new Node("xingchuan.node3", "192.168.0.13");Node addNode4 = new Node("xingchuan.node4", "192.168.0.14");Node addNode5 = new Node("xingchuan.node5", "192.168.0.15");Node addNode6 = new Node("xingchuan.node6", "192.168.0.16");Node addNode7 = new Node("xingchuan.node7", "192.168.0.17");Node addNode8 = new Node("xingchuan.node8", "192.168.0.18");nodeService.addNode(addNode1);nodeService.addNode(addNode2);nodeService.addNode(addNode3);nodeService.addNode(addNode4);nodeService.addNode(addNode5);nodeService.addNode(addNode6);nodeService.addNode(addNode7);nodeService.addNode(addNode8);//用于检查数据分布情况Map<String, Integer> countmap = new HashMap<>();Node node = null;for (int i = 1; i <= 100000; i++) {String key = String.valueOf(i);node = nodeService.lookupNode(key);node.cacheString(key, "TEST_VALUE");String k = node.getIp();Integer count = countmap.get(k);if (count == null) {count = 1;countmap.put(k, count);} else {count++;countmap.put(k, count);}}System.out.println("初始化数据分布情况:" + countmap);
(滑动可查看)
运行结果如下:
初始化数据分布情况:{192.168.0.11=12499, 192.168.0.12=12498, 192.168.0.13=12500, 192.168.0.14=12503, 192.168.0.15=12500, 192.168.0.16=12502, 192.168.0.17=12499, 192.168.0.18=12499}(滑动可查看)
可以看到,每个节点的存储分布数量是大致一样的。
缺点
我们可以很清楚的看到,取模算法是通过数据存储节点个数来进行运算的,所以,当存储节点个数变化了,就会造成灾难性的缓存失效。
举例:
初始集群里面只有4个存储节点
(Node0,Node1,Node2,Node3),这时候我要存储id为1~10的用户,我可以通过id % 4来运算得出各个ID的分布节点
这时候,如果集群新增一个存储节点Node4,会发生什么呢?
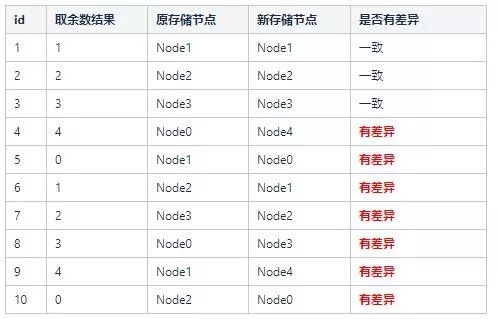
这里我们会发现,大量的存储节点的key和原先的对应不上了,这时候我们如果在生产环境,就需要做大量的数据迁移。
删除一个节点,原理同上,不再赘述。
代码模拟一个分布式缓存存储,使用取模的方式,新增一个节点带来的问题。测试代码如下:
HashNodeService nodeService = new NormalHashNodeServiceImpl();Node addNode1 = new Node("xingchuan.node1", "192.168.0.11");Node addNode2 = new Node("xingchuan.node2", "192.168.0.12");Node addNode3 = new Node("xingchuan.node3", "192.168.0.13");Node addNode4 = new Node("xingchuan.node4", "192.168.0.14");Node addNode5 = new Node("xingchuan.node5", "192.168.0.15");Node addNode6 = new Node("xingchuan.node6", "192.168.0.16");Node addNode7 = new Node("xingchuan.node7", "192.168.0.17");Node addNode8 = new Node("xingchuan.node8", "192.168.0.18");nodeService.addNode(addNode1);nodeService.addNode(addNode2);nodeService.addNode(addNode3);nodeService.addNode(addNode4);nodeService.addNode(addNode5);nodeService.addNode(addNode6);nodeService.addNode(addNode7);nodeService.addNode(addNode8);//用于检查数据分布情况Map<String, Integer> countmap = new HashMap<>();Node node = null;for (int i = 1; i <= 100000; i++) {String key = String.valueOf(i);node = nodeService.lookupNode(key);node.cacheString(key, "TEST_VALUE");String k = node.getIp();Integer count = countmap.get(k);if (count == null) {count = 1;countmap.put(k, count);} else {count++;countmap.put(k, count);}}System.out.println("初始化数据分布情况:" + countmap);// 正常情况下的去获取数据,命中率int hitcount = 0;for (int i = 1; i <= 100000; i++) {String key = String.valueOf(i);node = nodeService.lookupNode(key);if (node != null) {String value = node.getCacheValue(key);if (value != null) {hitcount++;}}}double h = Double.parseDouble(String.valueOf(hitcount))/ Double.parseDouble(String.valueOf(100000));System.out.println("初始化缓存命中率:"+ h);// 移除一个节点Node addNode9 = new Node("xingchuan.node0", "192.168.0.19");nodeService.addNode(addNode9);hitcount = 0;for (int i = 1; i <= 100000; i++) {String key = String.valueOf(i);node = nodeService.lookupNode(key);if (node != null) {String value = node.getCacheValue(key);if (value != null) {hitcount++;}}}h = Double.parseDouble(String.valueOf(hitcount))/ Double.parseDouble(String.valueOf(100000));System.out.println("增加一个节点后缓存命中率:"+ h);
(滑动可查看)
运行结果如下:
初始化数据分布情况:{192.168.0.11=12499, 192.168.0.12=12498, 192.168.0.13=12500, 192.168.0.14=12503, 192.168.0.15=12500, 192.168.0.16=12502, 192.168.0.17=12499, 192.168.0.18=12499}初始化缓存命中率:1.0增加一个节点后缓存命中率:0.11012
(滑动可查看)
三、分布式数据分布算法——一致性Hash
概述
取模算法的劣势很明显,当新增节点和删除节点的时候,会涉及大量的数据迁移问题。为了解决这一问题,引入了一致性Hash。
一致性Hash算法的原理很简单,描述如下:
想象有一个巨大的环,比如这个环的值的分布可以是 0 ~ 4294967296
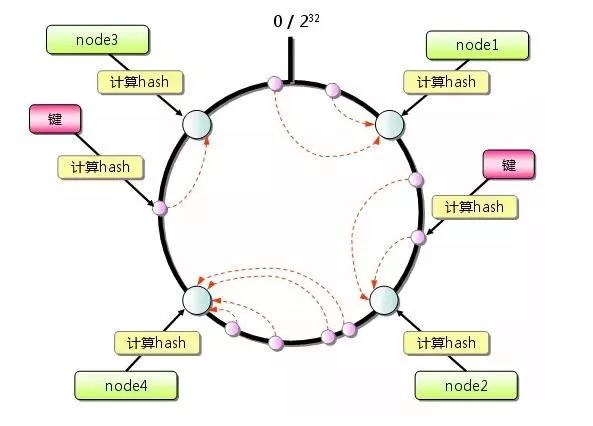
还是在取模算法中的那个例子,这时候我们假定我们的4个节点通过一些key的hash,分布在了这个巨大的环上面。
用户数据来了,需要存储到哪个节点呢?通过key的hash,得出一个值r,顺时针找到最近的一个Node节点对应的hash值nodeHash,这次用户数据也就存储在对应的这个Node上。
那么问题来了,如果只有4个节点,可能会造成数据分布不均匀的情况,举个例子,上图中的Node3和Node4离的很近,这时候,Node1的压力就会很大了。如何解决这个问题呢?虚拟节点能解决这个问题。
什么是虚拟节点?
简单说,就是在环上模拟很多个不存在的节点,这时候这些节点是可以尽可能均匀分布在环上的,在key的hash后,顺时针找最近的存储节点,存储完成之后,集群中的数据基本上就分配均匀了。唯一要做的,必须要维护一个虚拟节点到真实节点的关系。
一致性Hash的实现
下面,我们就来通过两个进阶,实现一个一致性Hash。
进阶一我们不引入虚拟节点,进阶二我们引入虚拟节点
一致性Hash实现,进阶一,关键代码如下:
public void addNode(Node node) {nodeList.add(node);long crcKey = hash(node.getIp());nodeMap.put(crcKey, node);}public Node lookupNode(String key) {long crcKey = hash(key);Node node = findValidNode(crcKey);if(node == null){return findValidNode(0);}return node;}/*** @param crcKey*/private Node findValidNode(long crcKey) {//顺时针找到最近的一个节点Map.Entry<Long,Node> entry = nodeMap.ceilingEntry(crcKey);if(entry != null){return entry.getValue();}return null;}public Long hash(String key) {CRC32 crc = new CRC32();crc.update(key.getBytes());return crc.getValue();}
(滑动可查看)
在lookupNode的时候,我们是顺时针去找最近的一个节点,如果没有找到,数据就会存在环上顺时针数第一个节点。
测试代码如下:
和取模算法的一样,唯一不同的,就是把算法实现的那一行改掉HashNodeService nodeService = new ConsistentHashNodeServiceImpl();
(滑动可查看)
运行结果如下:
初始化数据分布情况:{192.168.0.11=2495, 192.168.0.12=16732, 192.168.0.13=1849, 192.168.0.14=32116, 192.168.0.15=2729, 192.168.0.16=1965, 192.168.0.17=38413, 192.168.0.18=3701}初始化缓存命中率:1.0增加一个节点后缓存命中率:0.97022
(滑动可查看)
这里我们可以看到,数据分布是不均匀的,同时我们也发现,某一个节点失效了,对于缓存命中率的影响,要比取模算法的场景,要好得多。
一致性Hash的实现,进阶2,引入虚拟节点,代码如图:
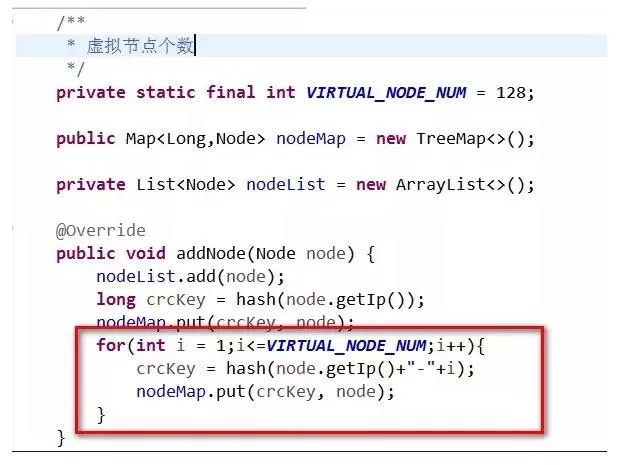
我们在新增节点的时候,每个真实节点对应128个虚拟节点
删除节点的代码如下,对应的虚拟节点也一并删掉。

再次测试数据分布和缓存命中率
测试代码不变,运行结果如下:
初始化数据分布情况:{192.168.0.11=11610, 192.168.0.12=14600, 192.168.0.13=13472, 192.168.0.14=11345, 192.168.0.15=11166, 192.168.0.16=12462, 192.168.0.17=14477, 192.168.0.18=10868}初始化缓存命中率:1.0增加一个节点后缓存命中率:0.91204
(滑动可查看)
这时,我们发现数据分布的情况已经比上面没有引入虚拟节点的情况好太多了。
总结
我理解一致性Hash就是为了解决在分布式存储扩容的时候涉及到的数据迁移的问题。
但是,一致性Hash中如果每个节点的数据都很平均,每个都是热点,在数据迁移的时候,还是会有比较大数据量迁移。
新福利:
上周获奖名单:布拉没有格

1、
2、
3、
4、
以上是关于一文了解一致性哈希的主要内容,如果未能解决你的问题,请参考以下文章