数据分片与路由问题(一致性哈希算法)
Posted lorettax数据民工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分片与路由问题(一致性哈希算法)相关的知识,希望对你有一定的参考价值。
| Hi~新朋友,记得点个关注 防止迷路哟 |
常见的数据分片有:哈希分片和范围分片
用图进行分析,图画的实在是不咋地:
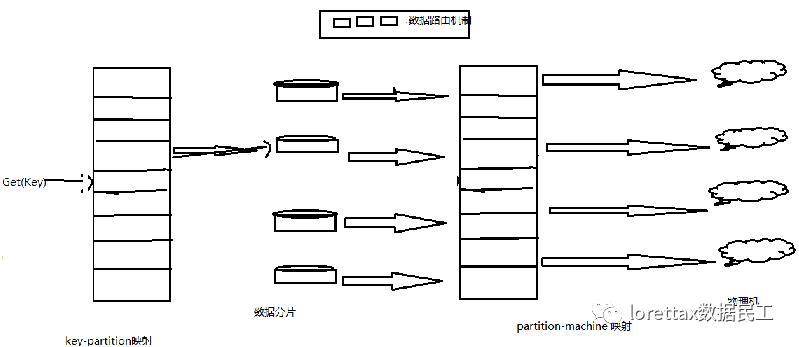
可以将上图看成是一个二级映射关系:
第一级:key-partition映射:将数据记录映射到数据分片空间,特点:多对一的映射关系
第二级:partition-machine映射:将数据分片映射到物理机器中 特点:多对一的映射关系
哈希分片和范围分片都可以映射到上面画的这个抽象模型中,哈希分片:采用 哈希函数来建立key-partition映射关系,支持 点查询(根据某条记录的主键可以获得记录内容),但是它无法支持范围查询。
范围分片:既支持点查询 ,也支持范围查询(指定记录的主键范围内一次读取多条满足条件的数据),向支持范围查询的系统就有 Google的BigTable 系统。
通过哈希函数来进行数据分片比较常见:其中最为常见的三种:
1.Round Robin(哈希取模法)
H(key)=hash(key)mod K
假设有k台物理机,对它进行编号 0到k-1,根据上面的hash函数 ,H(Key)的数值就是存储物理机的编号,将数据全部分配到 K 台物理机上,在查找的时候也可以通过这个函数来找打存储相应信息的物理机。
优点:实现起来非常简单。
缺点:缺乏灵活性。
一旦新增一个物理机到分布式存储系统,此时哈希函数就变成了:
H(key)=hash(key)mod (K+1)
为什么缺乏灵活性:
从上面的模型图中我们可以看到 Round robin 是将物理机和数据分片两个功能 合二为一了,这样造成的结果就是一个物理机对应一个数据分片,这样 key-partition和partition-machine映射也成为一体 ,都由同一个哈希函数来承担, 造成机器个数 K 出现在 映射函数,过度的紧密耦合。只要机器个数变动了,哈希函数也会 跟着变动。
2.虚拟桶(Virtual Buckets)
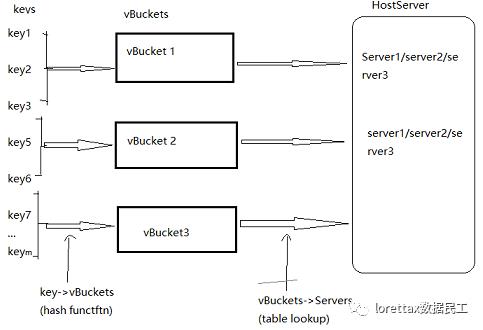
如上图所示,在待存储记录和物理机之间引入了虚拟桶层,所有记录先通过哈希函数映射到对应的虚拟桶,记录和虚拟桶的映射关系:多对一,
第二层映射是 虚拟桶到物理机之间的映射:多对一。 其具体实现方式通过查表来实现,通过内存表来管理这层关系 。
对照第一个图的抽象模型可以看出,虚拟桶层就是对应的 “数据分片” 层,key-partition映射采用哈希函数,而partition-machine 映射采用表格管理来实现。
与Round Robin相比,引入了虚拟桶层,将原先记录到物理机的单层映射解耦成两层映射 ,阿达加强了系统的可扩展性。新的机器加入时,只需要修改partition-machine映射表中的个别条目就能实现扩展。
优点:具有较强的灵活性。
3.一致性哈希算法
分布式存储中常见的一项技术就是 :分布式哈希表。它是哈希表的分布式的扩展,就是在多台机器的情况下,每个机器只存储一些数据,如何通过 哈希方式 对 数据 进行增,删,改,查等一些数据操作。
一致性哈希算法就是其中的一种实现方式。
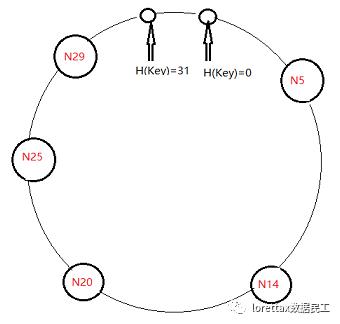
上图是表示长度为5的二进制数值的 一致性哈希算法 的环状序列 的示意图 (m=5),所以这个哈希数值空间可以表达的值是从 0~31。
每个机器可以通过 Ip和端口号 经过 哈希函数 映射到 哈希数值空间内。所以上面的每个 大圆 均表示了 一个机器节点。N (x)中的 X 表示的是哈希数值内对应的哈希数值。
举例:N20节点 存储的是 落在 N14到N20的哈希空间范围内的数据(经过哈希后的),N5存储的是N29后落在 30~31,0~5范围内的数据。
一致性哈希算法的路由:
一种高效的路由查找方式就是: 每个机器节点都配置路由表。
原因:它原先是依靠有向环查找的,这样查找效率不太高,首先接收到 查询请求 的机器节点要根据函数 解出要查找的主键的哈希值,从本身节点的范围内先查找这个哈希值,如果不在就将它交个后趋节点,这样直到查找那个范围内有哈希值 的那个机器节点。
输入:机器节点N(i)发起初始查询请求,查询主键 Key对应的值H(Key)=j。
输出:N(i)给出对应的键值Value,或者返回键值不存在的信息。
算法:通过不同节点之间发送消息来写作完成。假设当前执行的节点为N(c),其初始值是N(i),N(c)的后趋节点为N(s).重复执行下列步骤。
步骤一:判断 c<=j<=s,如果是,结束查找,说明key如果存在,就在N(c)的后趋节点N(s)上,所以N(c)发消息给N(s)查找Key的值value,查找到后,N(s)将结果返回给N(i)。(每个消息都包含消息源 N(i).)
步骤二:否则,N(c)查找其对应的路由表,找到小于 j的最大编号N(h),N(c)向N(h)发送消息,请求它代表N(i)查找Key的值value,N(h)此时成为当前节点N(c), 继续按照步骤一和步骤二递归执行。
比如:
N(14)节点接到查询Key的键值请求,其中 H(Key)=27。
操作过程下图(红线部分):
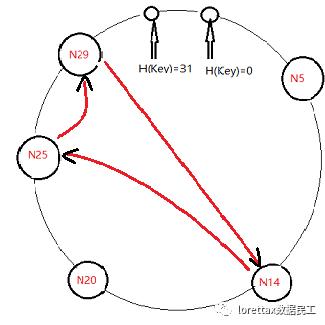
通常情况下,路由算法发送的消息不会多于m条,因为这个过程类似于 在 0~(2的m次方-1)数值空间上的二分查找法,每次当节点 N(c)通过路由表把消息发送给节点N(h),N(h)到目标所在节点N(d)的距离不会超过N(c)到N(d)的距离的一半,所以其可以通过不超过 m 条消息查找整个数值空间。
END~
觉得不错记得点个关注再走呗~
|
以上是关于数据分片与路由问题(一致性哈希算法)的主要内容,如果未能解决你的问题,请参考以下文章