一口气讲透分布式理论一致性哈希(Hash)
Posted 架构有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一口气讲透分布式理论一致性哈希(Hash)相关的知识,希望对你有一定的参考价值。
如今云计算、大数据、物联网、AI的兴起,使得分布系统得到了前所未有的广泛应用,然而由于分布式系统具有极高的复杂度,带来了许多难题,一致性哈希就是为了解决分布式难题之一应运而生的,本篇主要图示讲解一致性哈希的原理及其应用,助力码农变身。
简而言之,一致性哈希(Consistent Hash)是为了解决由于分布式系统中节点的增加或减少而带来的大量失效问题,它可以有效地降低这种失效影响,从而提高分布式系统的性能和可用性。
什么是Hash
在深入探讨之前,我们先了解下什么是hash:哈希(hash)简单理解就是将任意长度的输入通过散列算法转换成固定长度的输出,这个输出一般称之为散列码或哈希值。哈希是一种映射思想,散列算法即是一种函数,对比数学函数可以表示如下
f(x)=y → f(输入)=散列码经过计算输出的散列码一般用正整数表示,它比输入要简短的多,因此你会遇到有些朋友会说哈希是一种压缩,但温馨提醒的是这种压缩是不可逆的,也就是说没办法解压缩,所以建议把哈希理解成映射会更妥当些。
比如把“码农神说”作为输入,经过散列算法计算处理,输出对应的散列码“30”,也就是说散列码30是原始输入“码农神说”的映射,这种映射关系是一一对应的(哈希碰撞的特殊情况可暂时忽略,因为自然碰撞的概率极低),使用散列码通过这种映射关系可以找到对应的原始输入,哈希处理及映射关系如下图
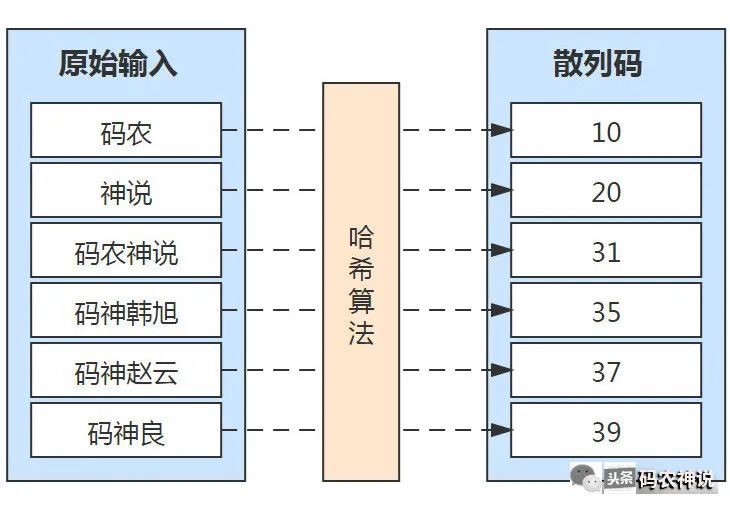
散列码是原始输入的摘要,计算机处理摘要这种短数据比处理原始输入的长数据更容易些、性能也更高,所以哈希的用途十分广泛,如安全加密、唯一标识、数据校验等,常见的散列算法有MD4、MD5、SHA等。
取余%
在计算机中的取余(%)操作除了判断奇偶数等常规用途外,还可以把目标映射在一个区间范围内,比如对5取余,相当于把目标映射在[0,5)开闭区间内,接着上例的图示进一步取余如下图示
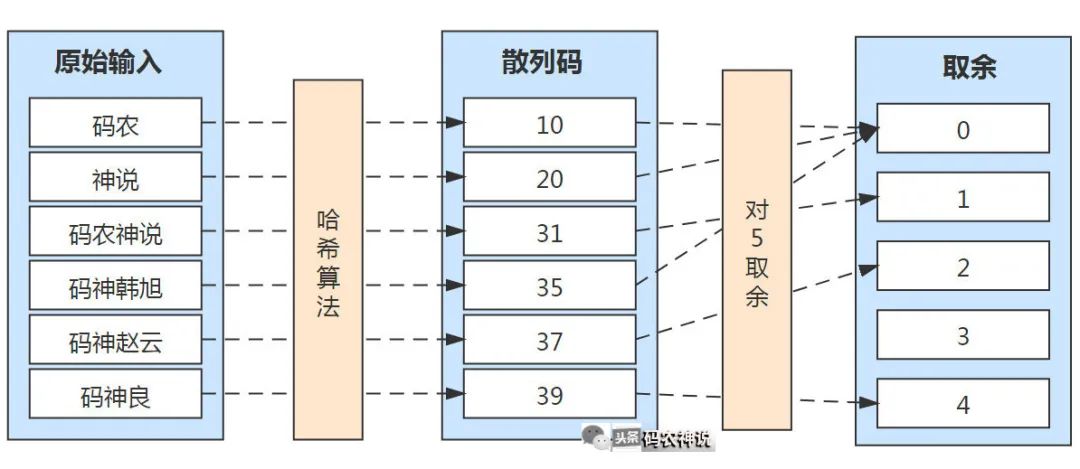
从图中看得出也是一种映射,但这种映射不同于哈希映射,它并非一对一。
取余的应用场景不仅在算法上用途较多,在分布式系统中也广泛应用,它进一步缩小了范围能够让计算机处理更集中、状态更一致,比如有状态的服务集群、缓存的服务集群等等,这些场景都需要把同一个客户的请求寻址发送到同一个固定的节点上,这样不仅达到了负载分散也做到了存储状态一致,避免了数据的复制。
常见的作法比如对用户IP进行哈希,再以集群中节点数量作为基数取余,从而可以寻址到已经排了序的节点并与其绑定。假想一个如下分布式缓存的例子
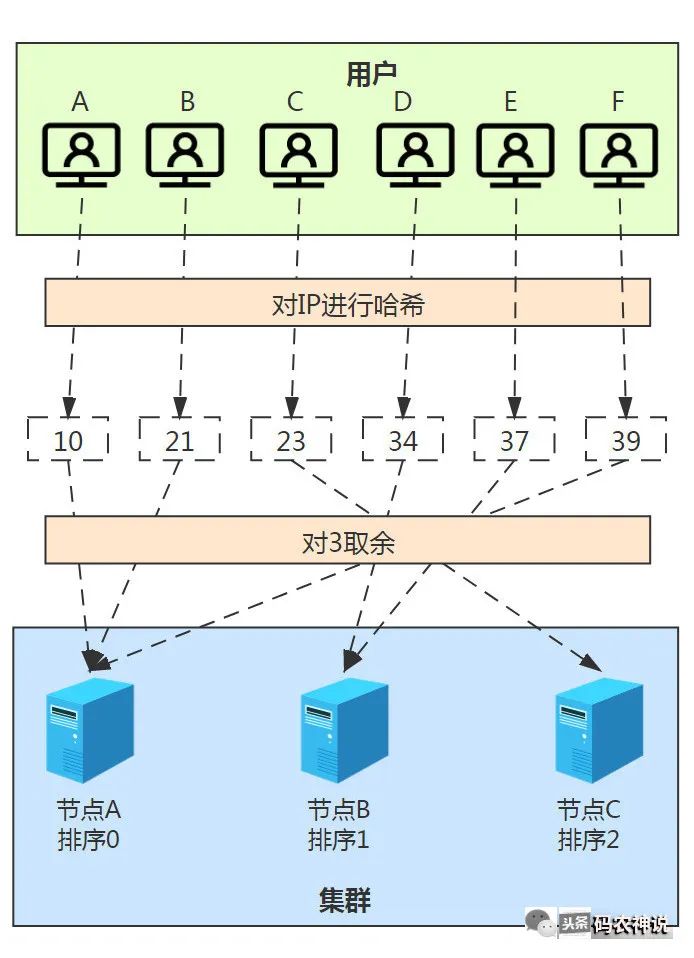
很完美吧≧◠◡◠≦!但是!!
分布式系统中横向伸缩或节点故障等,会形成节点的自动增加或删除。比如节点B如果故障,会自动从集群中被剔除,那么取余基数则变成了2,当请求过来时新的哈希过程就会变更如下
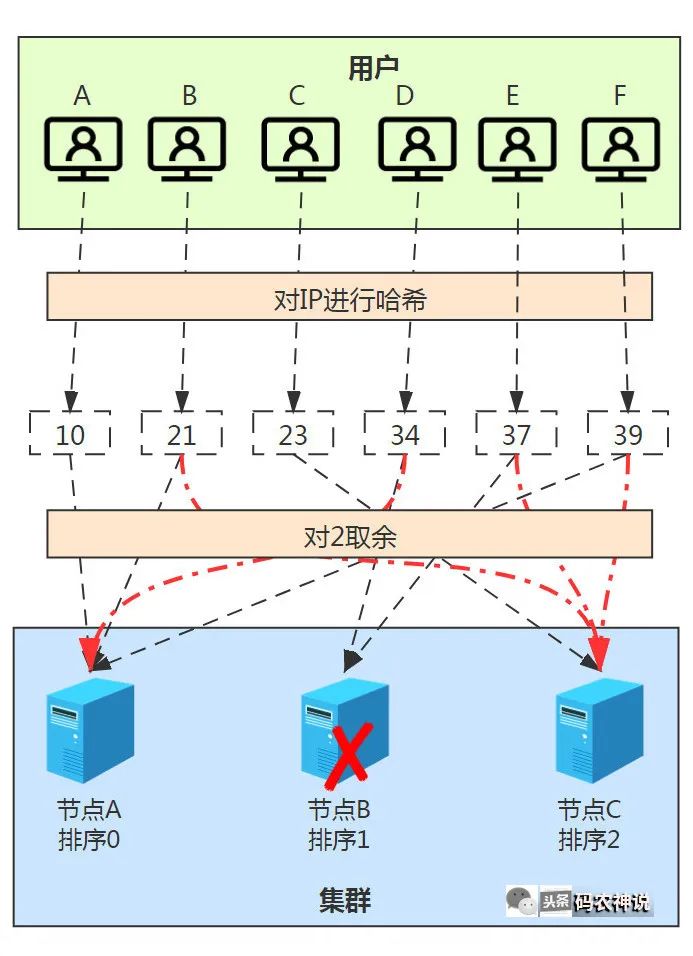
这就比较尴尬了,用户D和E的绑定节点变更可以理解,但用户B和F绑定的节点也需要变更,导致之前的数据失效。那么如果增加了一个节点D排序为4呢,你猜会怎样
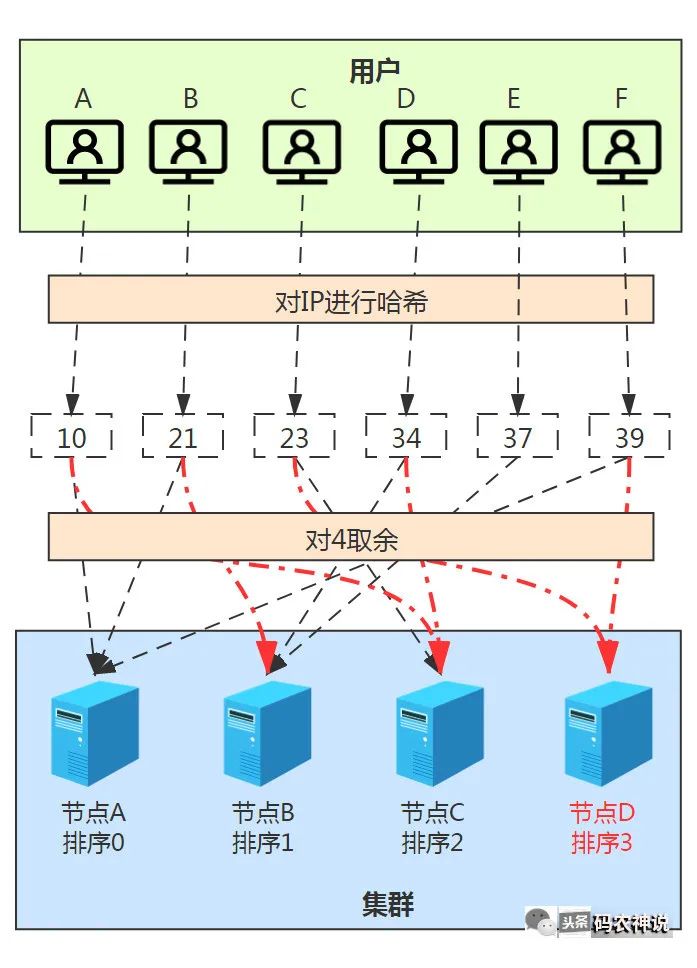
增加一个基点导致几乎所有的绑定失效,大量失效会造成了某个时间点的网络抖动和性能急剧下降。
一致性Hash算法
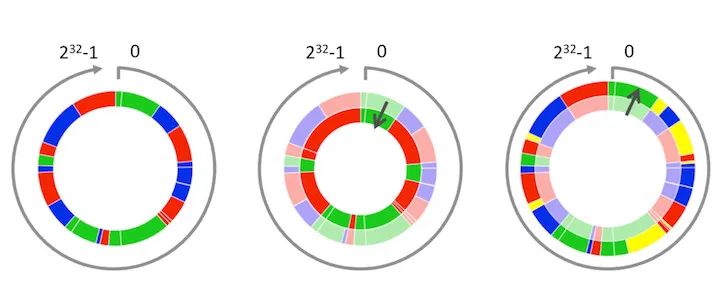
一致性hash算法就是为了解决上述大量失效问题,失效的最主要原因是取余的基数是根据集群中的节点数动态变化的!一致性hash算法把取余的基数固定为一个常数2^32,这样可以做到以不变应万变。一致性hash算法把散列码对2^32取余从而把范围控制在[0,2^32-1]的区间范围内,并把这个区间按照顺时针的方向均匀分布在一个圆环上,称之为HASH环。hash环正上方的点代表0,按顺时针依次是1、2、3.....2^32-1。
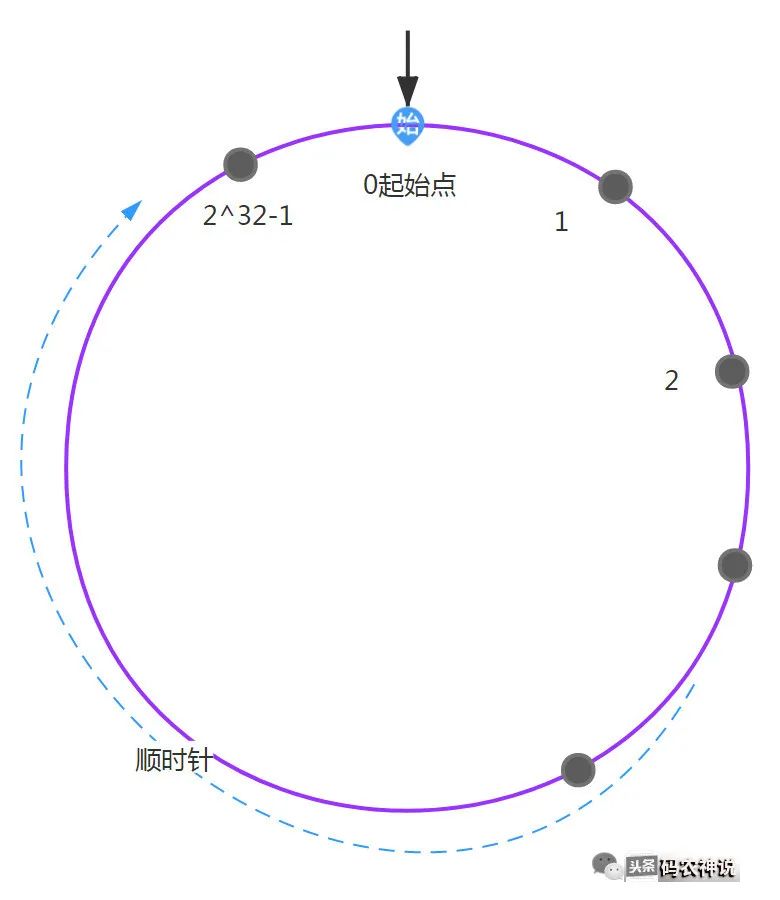
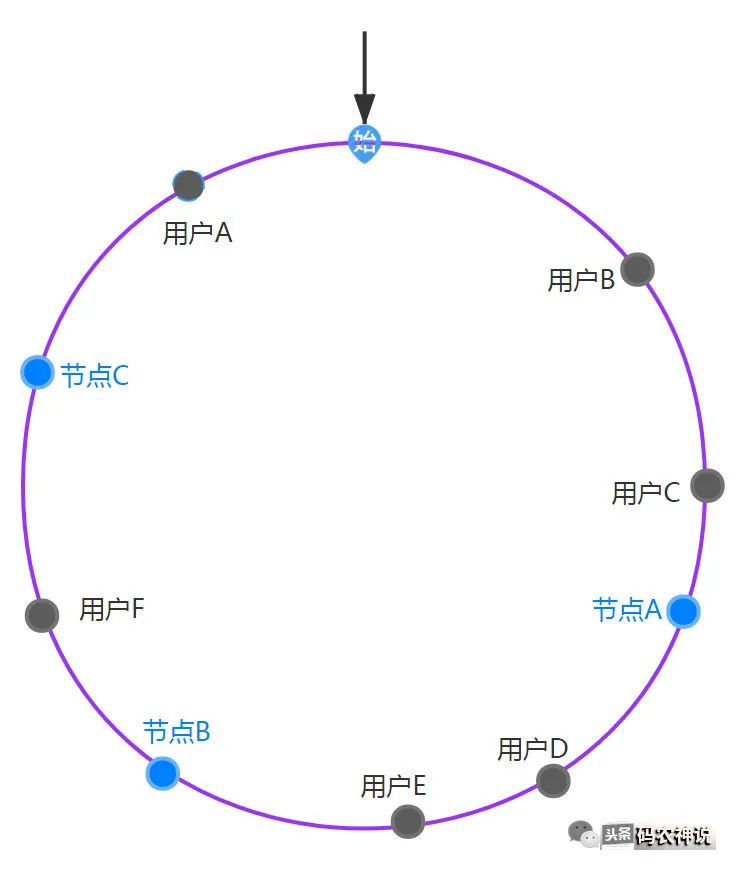
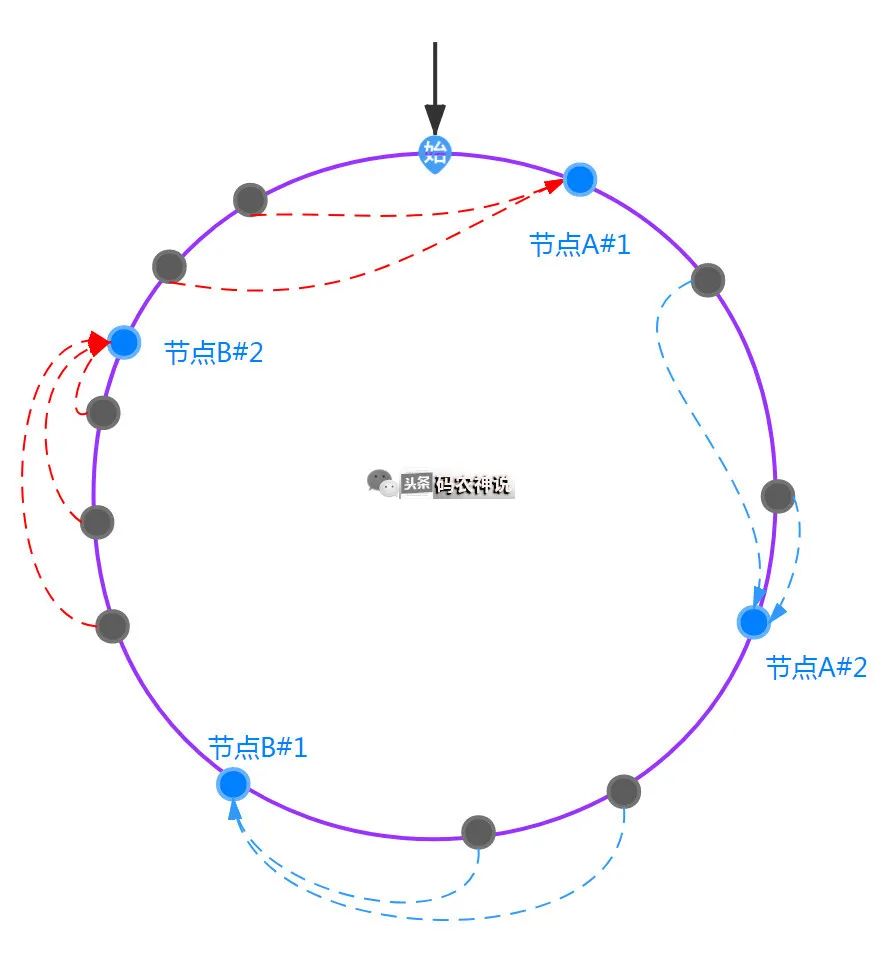
hash环上的用户以顺时针方向寻找环上最近的节点,则此用户的请求就绑定到该节点上,绑定对应如下图,比如用户A、B、C按顺时针在hash环上绑定到节点A上
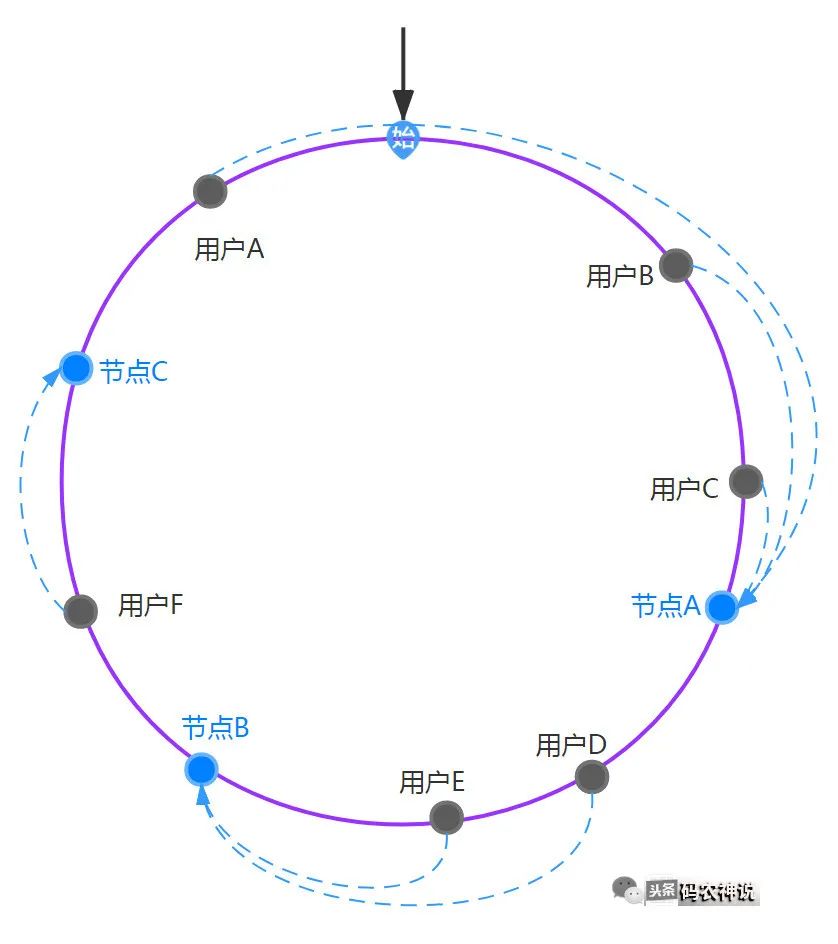
如果此时节点B出现了故障,则B会被从集群中剔除,剔除后按照一致性hash算法后绑定如下图
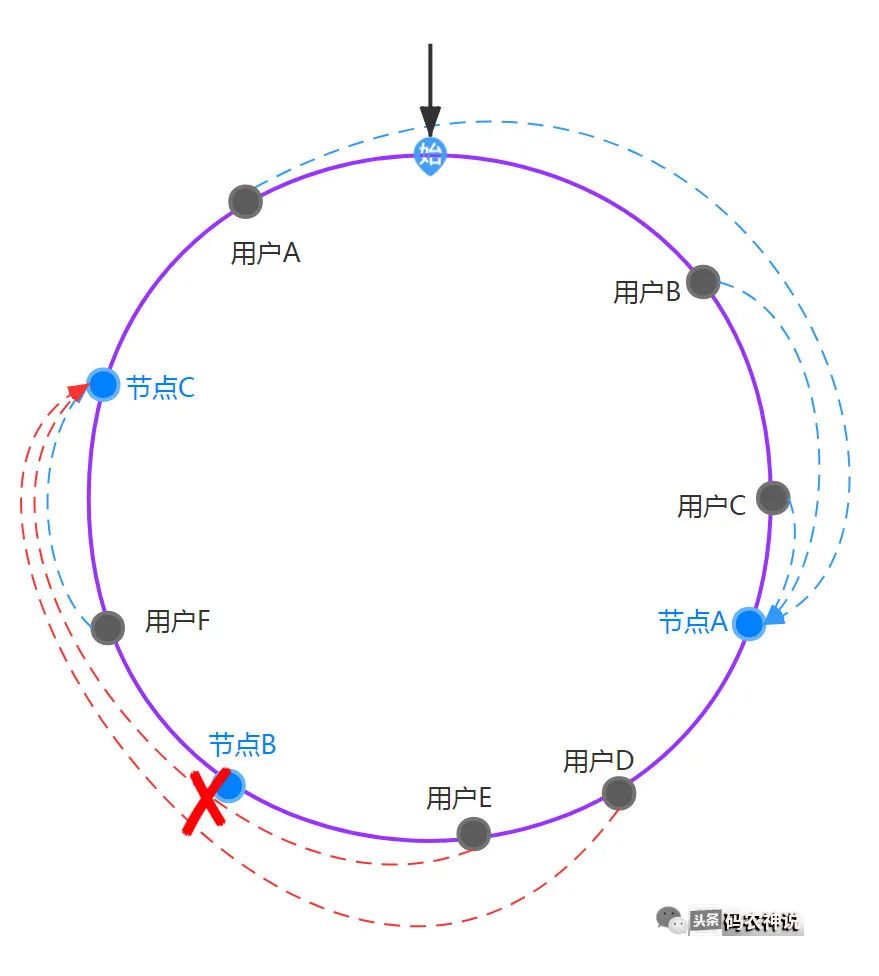
可以观察到,只会影响到D、E用户的节点绑定,对比发现绑定的失效量相对较少,如果增加一个节点D呢,只用影响到用户A的节点绑定,大大降低了失效率
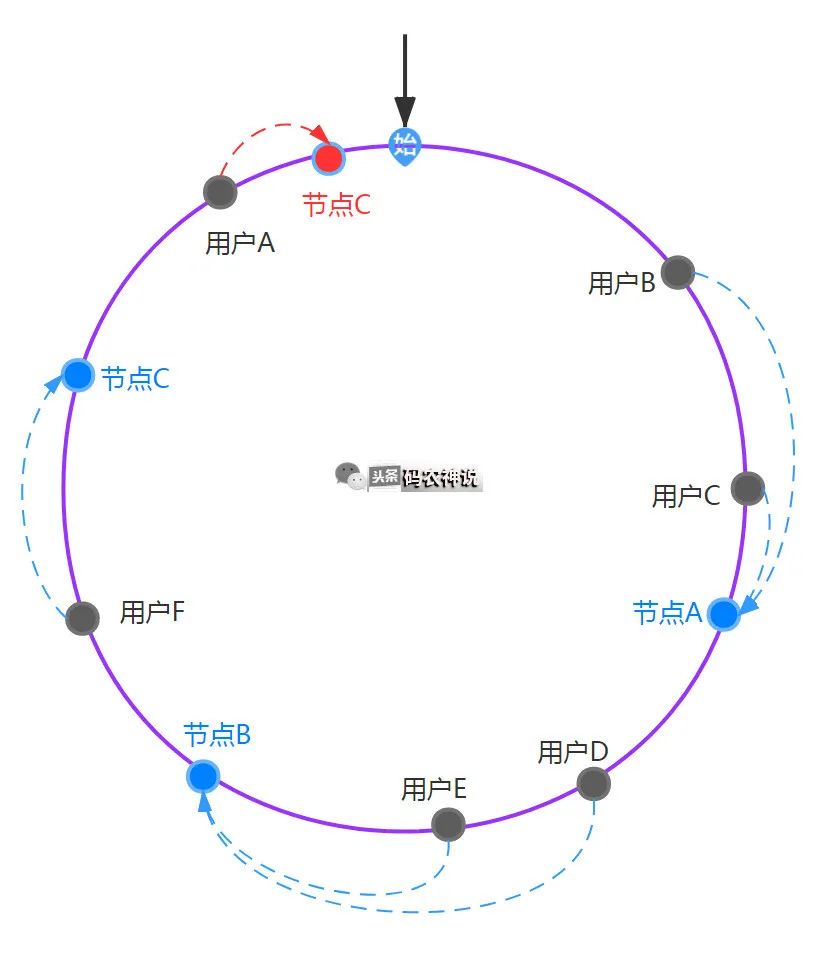
所以一致性hash不管是在集群中剔除节点还是增加节点,对比直接hash取余都会降低失效率,充分体现了一致性hash算法的优势。
虚拟节点
如果集群中的节点太少,则会造成数据倾斜问题,就是负载不均衡,导致有些节点超负荷
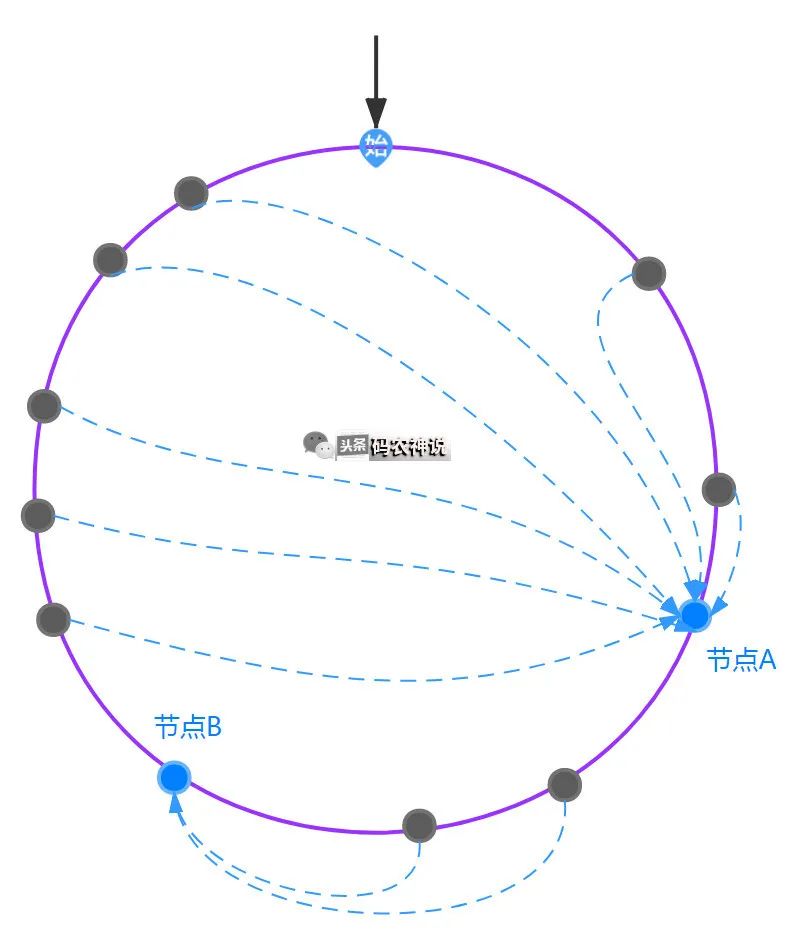
此时使用虚拟节点,通过对同一个节点使用不同散列算法得到不同的散列码,尽量在hash换上分布均匀,就可以缓解数据倾斜问题,如下
不适合做什么
一致性hash只能把失效率降到最低,但无法完全避免,它最初是针对分布式cache设计的,那么Cache失效后毕竟数据源里还有数据,大不了再拿一次,数据不会丢失。但如果是有状态服务集群,比如session状态,一旦丢失将会导致大面积用户重新登录,给用户体验带来极不痛快的体验。这种问题只能通过高可用的其他方案进行弥补。

以上是关于一口气讲透分布式理论一致性哈希(Hash)的主要内容,如果未能解决你的问题,请参考以下文章