小白python机器学习之路——支持向量机
Posted 生物与化学数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白python机器学习之路——支持向量机相关的知识,希望对你有一定的参考价值。
支持向量机(support vector machines, SVM)
一、类型:监督学习,分类
支持向量机可以理解为感知器的一种扩展,相比起逻辑回归,支持向量机的概念更为形象,更好理解。
如图所示,将(二维)数据用一条直线分开,可能会有很多种分法,支持向量机的优点就是可以选择其中“最好的”直线。
首先要定义一个概念,支持向量(support vector)。支持向量就是(二维)数据分割线两边离分割线最近的一个或几个点,显然,对于一个分类问题,支持向量最少有两个(一边一个);也可能有多个(每一边的所有支持向量到分割线的距离都相等而且最小)。
支持向量机就是基于支持向量工作的,它的成本函数就是图中的Margin,也就是两边的支持向量到分割线之间的距离之和。很好理解,成本函数当然越大越好啦,也就是分割线离两边的点越远越好。
当然,以上的原理图和介绍都是基于二维数据的,我们可以无脑将之推广到多维(“分割线”换成“分割面”,甚至是“分割超平面”;“点”换成“超级点”),反正一定不会错。

二、原理
1、成本函数
为了更好的理解,我们依然以二维的数据为例。
如果将分割线一侧的点的标签视为1,另外一侧的点的标签为-1,而分割线处为0,我们就可以通过净输入得到下面的等式:
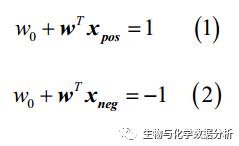
将两等式相减,并用ω向量的长度将等式两侧“标准化”,可以得到margin的表达式:

等式的左侧就是要使其最大化的margin,其实如果从二维的角度理解,就是点到直线的距离。如此的话,分类的标准也可以写成如下形式:
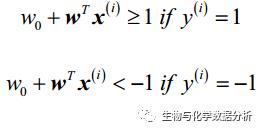
ok,如果要最大化margin,只要优化等式右侧的权值向量相关的函数就可以了。实际使用时,往往采取最小化1/2 * ||ω||^2的办法,可以通过凸二次规划问题的解决方法去求解。这里我们不细说。
2、非线性问题与松弛变量
如果遇到样本非线性可分的情况,像感知器一样,在支持向量机中也要放宽标准。这里引入松弛变量ξ来达到“软边界”的目的。
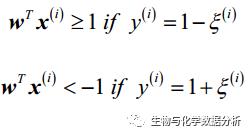
可以看到,较小的ξ可以容许一定的分错,如果ξ很大,那么分类边界可以变得非常“没有下限”。在这种情况下,成本函数就为:
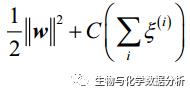
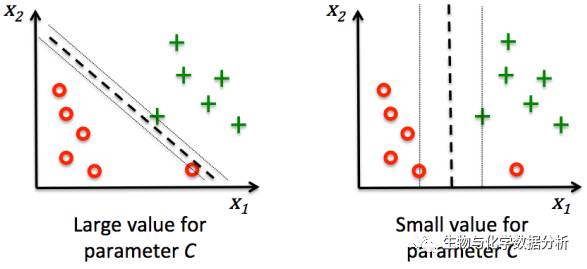
这里的C可以看做是正则化参数,C越大,对于分错的惩罚就越大,和逻辑回归中的超参数C刚好相反。
3、非线性问题与核SVM(kernel SVM)
SVM对于非线性问题的处理是很有一套的,在处理非线性问题时,可以选择将SVM“核化”。什么意思呢?不急,我们先来构造一些非线性可分的数据。
import numpy as np
import matplotlib.pyplot as plt
#设定随机种子
np.random.seed(18)
#生成服从正态分布的200行、2列的随机数
X_xor = np.random.randn(200, 2)
#设置逻辑门分组器
y_xor = np.logical_xor(X_xor[ : , 0] > 0, X_xor[ : , 1] > 0)
#将X_xor中两列都大于零的部分的标签设置为1,其余为-1
y_xor = np.where(y_xor, 1, -1)
plt.scatter(X_xor[y_xor == 1, 0], X_xor[y_xor == 1, 1], marker = "x", label = "1")
plt.scatter(X_xor[y_xor == -1, 0], X_xor[y_xor == -1, 1], marker = "o", label = "-1")
plt.ylim(-3, 3)
plt.legend(loc = "best")
plt.show()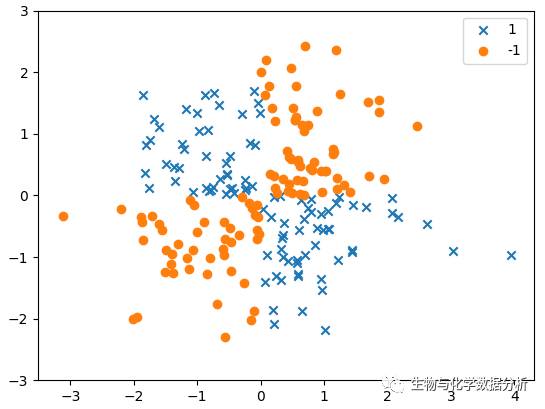
这个数据用一条直线怎么分都很难分得开吧。核SVM此时就会将在二维难以线性分割的数据映射到三维,之前有看过一个形象的比喻:桌上有一堆散落的苹果和梨,想要用一根棍子把他们分开,怎么都做不到,这时突然来了一个武林高手,“喝”的一声就向着桌子一掌拍了上去,苹果和梨都飞了起来;由于苹果和梨的形状不同,下落的速度也不同,武林高手用棍子在空中“刷”的一下(摆拍),完美的将苹果和梨分开了。
核SVM做的就是这样一件事情,用一个映射函数Φ(·)将低维线性不可分的数据映射到高维,分开之后再映射回去:
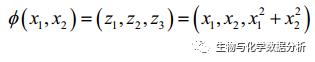
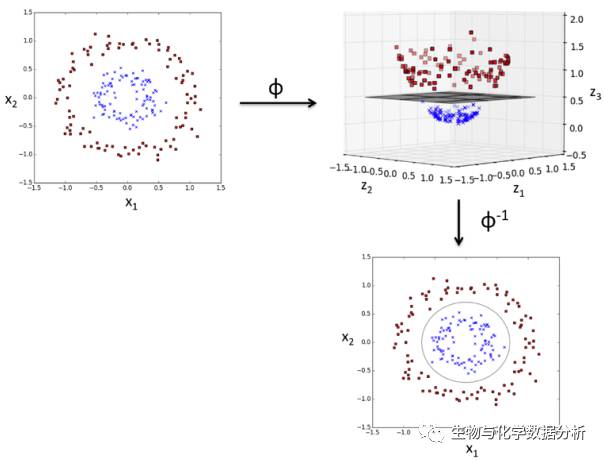
比如说,这里的第三个维度就是x1和x2的平方和,原来2维的特征空间变成了新的3维的特征空间,那么分割起来就是这样的效果:
常用的核函数就那么几种,在sklearn中使用kernel参数都可以进行设置,包括rbf、linear、poly、sigmoid。那么如何选择核函数呢?说真的,真正做数据科学比赛的时候,我都是一个一个试的,不是说搞清楚理论再去选择不重要,而是现阶段这样做更为高效。
rbf核函数可以表示两组样本之间的相似度,它是这样的:
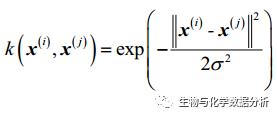
将分母提出来化简:
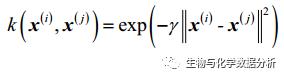
其中的γ就是原来的分母。由于有e为底,整个结果会落到0-1之间,如果两组样本距离很远,k会趋近于0,代表两组样本相似性很小;反之亦然。这里的γ就成为了模型中的一个超参数,可以进行设置,它对于模型的影响我们可以在代码的部分更好的理解。
三、python实现
sklearn.svm拥有SVM的各种实现函数,这里我们使用SVC,顾名思义就是SVM的classifier(分类器)。
首先我们测试一下rbf kernel SVC对于上面的非线性数据能够做到怎样的效果,还是利用之前的plot_decision_regions对边界进行可视化。
from matplotlib.colors import ListedColormap
from sklearn.svm import SVC
svm = SVC(kernel = "rbf", random_state = 0, gamma = 0.1, C = 10)
svm.fit(X_xor, y_xor)
plot_decision_regions(X_xor, y_xor, classifier = svm)
plt.legend()
plt.show()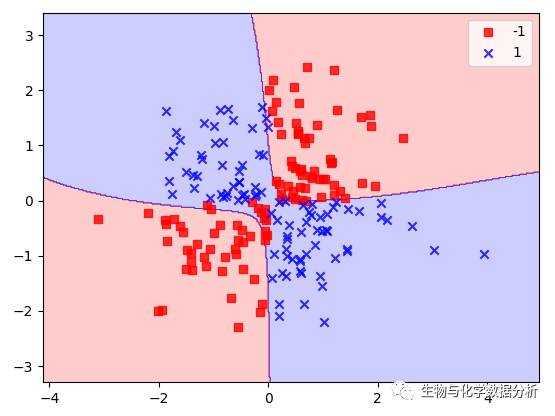
如果将γ调大一些呢?
svm = SVC(kernel = "rbf", random_state = 0, gamma = 10, C = 10)
svm.fit(X_xor, y_xor)
plot_decision_regions(X_xor, y_xor, classifier = svm)
plt.legend()
plt.show()
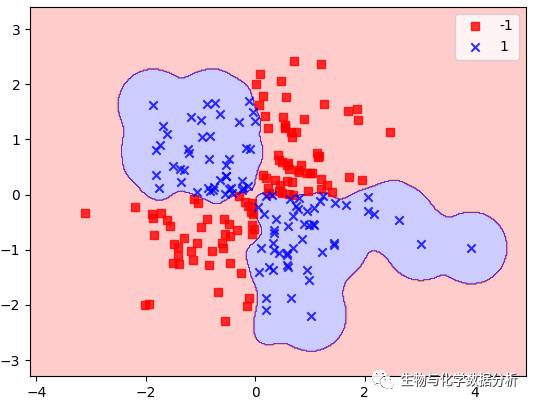
可以看到边界变得更“软”了,但是这样做看起来会更容易过拟合,因此参数还是要好好的调一下的。
参考文献
【1】Python Machine Learning, 2015, Sebastian Raschka
小白python机器学习之路系列:
欢迎我的关注微信公众号——生物与化学数据分析,化学狗与生物狗学习数据分析的好地方!有问题随时提出哦!
以上是关于小白python机器学习之路——支持向量机的主要内容,如果未能解决你的问题,请参考以下文章