一文看懂支持向量机
Posted 量信投资
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂支持向量机相关的知识,希望对你有一定的参考价值。
1
前言
支持向量机(support vector machines,SVM)是我最早接触的有监督分类算法之一。早在MIT修统计学的时候,我用它做过一个旧金山湾区上班族通勤模式的分类研究,但当时只是很粗浅的认识。后来由于工作的关系又非常系统的学习了一下,这其中包括认真学习了斯坦福Andrew Ng(吴恩达)的机器学习课(吴讲的真的非常好,深入浅出),参阅了大量的关于SVM的理论和实际应用的文献,以及和美国的一些机器学习领域专家交换想法,这些使我在判断是否要采用SVM解决量化投资中的问题时逐渐变得游刃有余。
对于有监督分类算法的表现,业界常用大概10种不同的指标来评判,包括Accuracy,LIFT,F-Score,ROC,Precision / Recall Break-Even Point,Root Mean Squared Error等。无论以哪种准确性的评价指标来看,SVM的效果都不输于人工神经网络ANN或者高级的集合算法如随机森林。SVM的另一个特点是其自身可以在一定程度上防止过拟合,这对于其在量化投资上的应用格外重要。这是因为任何人工智能算法有效的前提是:历史样本和未来样本是来自同一个(未知)的整体,满足同分布。只有这样,基于历史样本学习出来的规律才会在未来继续有效。但是对于金融数据来说,这个假设在很多问题上无法满足。因此,如果机器学习算法在历史数据上过拟合的话,那么基本可以肯定这个模型对未来的数据毫无作用。
鉴于我对SVM的钟爱,我很早以前就打算写一篇介绍它的短文,作为对知识的一个梳理。不过后来,我读了一篇来自quantstart.com的文章,名为Support Vector Machines: A Guide for Beginners。作者并没有使用大量的数学公式,而是用精炼的语言和恰如其分的图例对SVM的基本原理进行了阐述。平心而论,让我自己憋几天也不一定能写的比人家更清晰和生动,因此今天不如就索性把这篇文章大致翻译过来,作为对SVM的一个介绍。我会跳过一些不影响理解的文字、对原文的结构做一些改动,并在一些地方加入自己的理解(在第7、8节中,有一些该文没有的核心内容)。对那些阅读英语比阅读中文更舒服的小伙伴,也不妨看看原文。
初识SVM
支持向量机解决的是有监督的二元分类问题(supervised binary classification):
对于新的观测样本,我们希望根据它的属性,以及一系列已经分类好的历史样本,来将这个新样本分到两个不同的目标类中的某一类。
垃圾邮件识别就是这么一个例子:一个邮件要么属于垃圾邮件,要么属于非垃圾邮件。对于一封新邮件,我们希望机器学习算法自动对它分类。为此,我们首先通过人工对大量的历史邮件进行spam或non-spam标识,然后用这些标识后的历史邮件对机器学习算法进行训练。
在处理这类分类问题时,SVM的作用对象是样本的特征空间(feature space),它是一个有限维度的向量空间,每个维度对应着样本的一个特征,而这些特征组合起来可以很好的描述被分类的样本。比如在上面的垃圾邮件识别例子中,一些可以有效辨别spam和non-spam邮件的词汇就构成了特征空间。
为了对新的样本分类,SVM算法会根据历史数据在特征空间内构建一个超平面(hyperplane);它将特征空间线性分割为两个部分,对应着分类问题的两类,分别位于超平面的两侧。构建超平面的过程就是模型训练过程。对于一个给定的新样本,根据它的特征值,它会被放在超平面两侧中的某一侧,这便完成了分类。不难看出,SVM是一个非概率的线性分类器。这是因为SVM模型回答的是非此即彼的问题,新样本会被确定的分到两类中的某一类。
在数学上表达上,每一个历史样本点由一个(x, y)元组表示,其中粗体的x是特征向量,即x = (x1, …, xp),其中每一个xj代表样本的一个特征,而y代表该样本的已知分类(通常用+1和-1表示两个不同的类)。SVM会根据这些给定的历史数据来训练算法的参数,找到最优的线性超平面。理想情况下,这个超平面可以将两类样本点完美的分开(即没有错分的情况)。对于给定的训练数据,可以将它们完美分开的超平面很可能不是唯一的,比如一个超平面稍微旋转一个角度便得到一个仍然能够完美分割的超平面。在众多的能够实现分类的超平面中,只有一个是最优的。我们会在下文介绍这个“最优”的定义。
在实际应用中,很多数据并非是线性可分的。SVM的强大之处在于它不仅仅局限于是一个高维空间的线性分类器。它通过非线性的核函数(kernel functions)把原始的特征空间映射到更高维的特征空间(可以是无限维的),在高维空间中再将这些样本点线性分割。高维空间的线性分割对应着原始特征空间的非线性分割,因此在原始特征空间中生成了非线性的决策边界。此外,这么做并不以增加计算机的计算负担为代价。因此SVM相当高效。
下面,我们会解释如何找到最优的线性超平面。基于它引出最大间隔分类器(maximal margin classifier)的概念。通过实例,我们会发现最大间隔分类器有时无法满足实际问题,这是因为不同类型的样本点错综的交织在一起,让它们无法被完美分割。为了解决这个问题,我们必须允许分类器故意的错误划分一些点,从而得到对整体样本总体分类效果的最优,这便引出了支持向量分类器(support vector classifier)。最后,我们介绍核函数的概念。支持向量分类器结合核函数便得到了支持向量机。最后,我们总结SVM的优缺点。
线性超平面
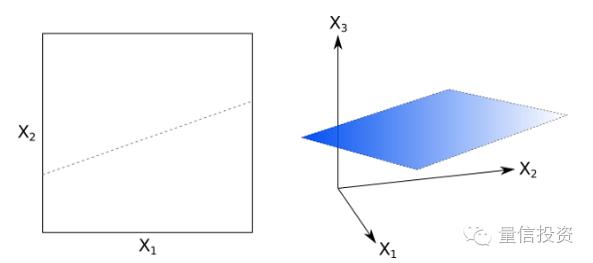
线性超平面是SVM的核心。对于一个p维空间,超平面是一个p-1维的物体,它将这个p维空间一分为二。下图分别是2维和3维特征空间中超平面的例子。在2维特征空间中,超平面就是一条1维的直线,在3维特征空间中,超平面是一个2维的平面。(注意,我们并不要求超平面一定要通过特征空间的原点。)
对于一个p维的特征空间x = (x1, …, xp),我们可以通过下面这个式子来定义一个超平面:
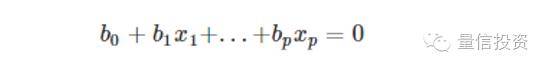
如果用向量和内积来表达,这个式子变为 b•x + b0 = 0。任何满足这个式子的向量x都落在这个p-1维超平面上。该超平面将p维特征空间分为两个区域,如下图所示(示意图,假设p=2,两个颜色代表特征空间中两个不同的区域):
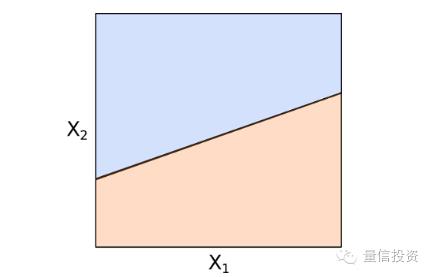
如果一个向量x满足b•x + b0 > 0,则它会落在超平面上方的区域;如果一个向量x满足b•x + b0 < 0,则它会落在超平面下方的区域。通过判断b•x + b0的符号,就可以对x分类。
分类问题
在邮件识别的例子中,假设我们有n个历史邮件,每一封都被标识为spam(+1)或者non-spam(-1)。每一封邮件中都有一些词被选为关键词。所有这n封邮件中不重复的关键词就组成了我们的特征。假设不重复的关键词一共有p个。
如果将上面这个问题用数学语言转化为分类问题,则我们有n个训练样本,每一个样本都是一个p维的特征向量xi。此外,每一个训练样本都有一个已知的分类yi(例如spam或者non-spam)。因此,我们有n对训练样本(xi, yi)。分类器将通过学习这些训练样本来优化自身的参数,得到最终的分类模型。我们使用测试样本来检查分类器的分类效果。
让我们来看一个简化的例子。考虑2维特征空间并假设训练样本都是完美可分的(如下图所示)。图中,红色和蓝色代表了两类不同的样本点。三天虚线表示三个不同的超平面;它们都可以将这些点完美分开。
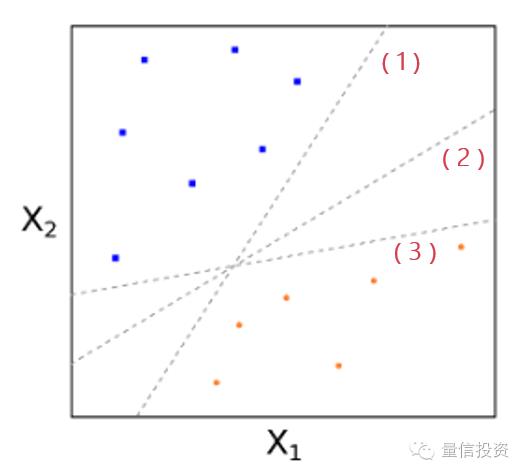
在这个例子中,这三条线都可以将特征空间一分为二。然而,我们如何确定哪条线才是最优的呢?直观上说,无论是(1)还是(3),都离某些红色和蓝色的样本点太近了,给我们的感觉是这两条线仅是“将将”把这些点分开;而位于中间的(2)号虚线离任何红色的和蓝色的点都比较远,给我们的感觉是它非常清晰地将这些点区分开了。因此,如果从这三条里面选的话,(2)号虚线应该是最好的选择。在数学上,上述直观感受被精确的翻译为数学优化方程,即最大间隔超平面。
最大间隔超平面
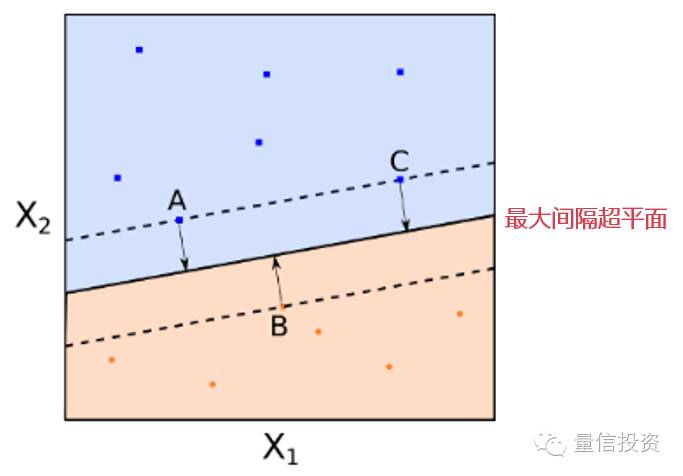
在上一节中,我们看到能够实现分类的超平面可能不唯一。在这种情况下我们需要找到最优的。对于一个给定的超平面,我们可以计算每个样本点到该平面的距离,这些距离中最小的一个就是这个超平面的间隔距离(margin)。因此,对于每一个超平面我们可以计算出它的margin。所有可行的超平面中,margin最大的那个就是我们要找的最优超平面,即最大间隔超平面(maximal margin hyperplane)。使用该超平面进行分类的分类器就称为最大边界距离分类器。
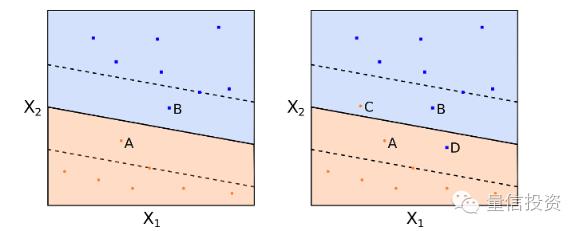
考虑下面这个2维特征空间示意图。图中有红色和蓝色两类样本点。黑色的实线就是最大间隔超平面。在这个例子中,A,B,C三个点到该超平面的距离相等。注意,这些点非常特别,这是因为超平面的参数完全由这三个点确定。该超平面和任何其他的点无关。如果改变其他点的位置,只要其他点不落入虚线上或者虚线内,那么超平面的参数都不会改变。A,B,C这三个点被称为支持向量(support vectors)。最大间隔超平面非常依赖支持向量的位置(这很明显是个缺点,我们会在后面解决)。
在数学上,求解最大间隔超平面参数相当于求解下面这个最优化问题:
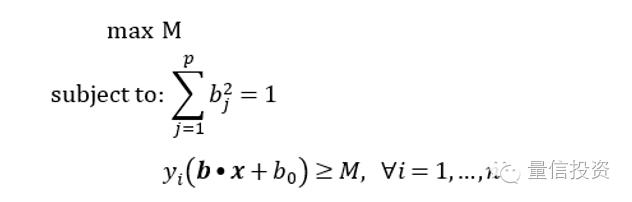
这个优化问题虽然看起来复杂,但是它非常容易求解,不过关于它的求解过程不在本文的讨论范围内。
需要强调的是,上面的假想例子假设两类样本点是可以完美的被分开的。而在在实际问题中,这样的情况几乎是不存在的。考虑下面的例子,红蓝两类样本点纠结在一起,我们无法找到一个超平面将它们完美的分开。
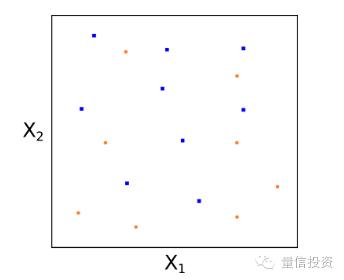
在这种情况下,我们怎么办呢?解决的思路是放松我们的要求,即我们不要求所有的训练样本都被正确的分类,由此引出软间隔(soft margin)和支持向量分类器(support vector classifier)的概念。
支持向量分类器
引出软间隔和支持向量分类器的概念有两个动机。
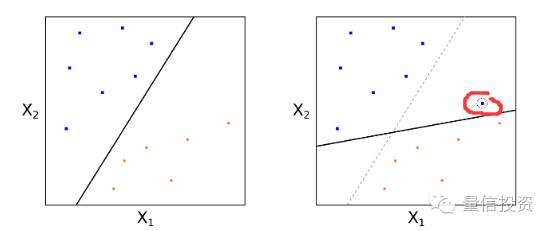
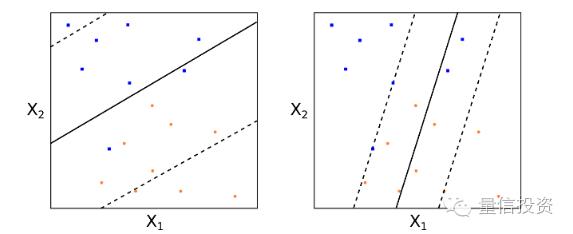
第一个动机是最大间隔分类器非常依赖支持向量的位置,这使得它对新的训练样本非常敏感。考虑下面这个例子,右图中仅仅因为增加了一个训练样本而它恰好是支持向量,前后得到的超平面完全不同。很显然,左图中的超平面对所有点的整体分类效果更好,而右图中因为一个新样本的加入,造成了模型的过拟合。
第二个动机就是上一节最后提到的,实际问题中,训练样本几乎无法被完美分开。
为了解决这两种情况,我们允许一部分样本点被错误的分类,并以此为代价追求分类器的鲁棒性以及分类器在全局所有样本点上分类效果的整体最优。一个支持向量分类器允许一些样本点出现在最大间隔线之内甚至是超平面错误的一侧。下图左图中,A、B两点虽然没有被分错类,但它们出现在了最大间隔边界(虚线)之内;下图右图中,C和D两点则出现在超平面错误的一侧。然而付出这些代价所换取的都是中间这条整体分类效果非常好的超平面(黑色实线)。
在数学上,引入soft margin后,优化问题变为如下形式:
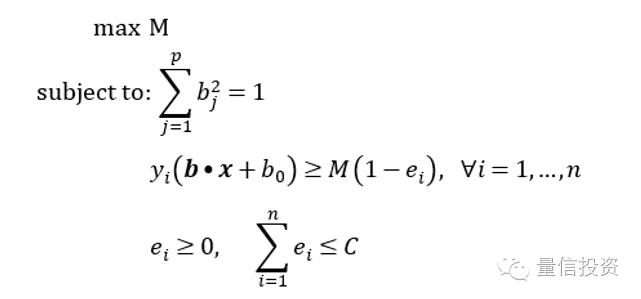
其中,对于每一个训练样本点i,定义了一个非负的松弛系数ei,它的取值表示该点是否满足最大间隔。ei等于0则表示该点满足最大间隔;如果ei在0和1之间,说明这个样本点在最大间隔边界之内但仍然分类正确;如果ei大于1这说明该点被分到了超平面的错误一侧。
系数C表示我们允许soft margin的程度。C越小意味着我们越不允许出现不满足最大间隔的情况。从直观上说,C的取值决定了最多有多少个训练样本点可以被分类错误。下面的例子说明,对于不同的C的取值,得到的超平面也会有很大差异。
一个分类器的误差由它的偏差和方差共同决定。在选取C时,我们必须权衡这两者。一个很小的C往往意味着模型有很低的偏差但是很高的方差(因为新的样本点会很容易改变超平面的参数);一个很大的C通常意味着模型有很高的偏差(无法充分利用数据、找到有效的支持向量)和较低的方差。在实际应用中,C的取值可以通过交叉验证来确定。
支持向量机
支持向量分类器是一个很好的线性分类器(在允许错误样本分类的前提下,找到对整体最优的超平面)。然而对于有的问题,数据本身的特性决定了线性分类器无论如何也不可能取得很好的效果。考虑下面这个例子。
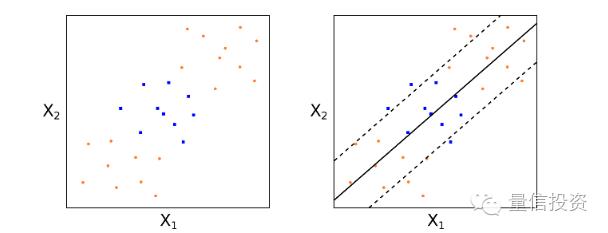
如果仅使用线性的支持向量分类器,则只能得到上图中黑色实线表示的超平面。它的分类效果是非常差的。这时,我们就需要对这个分类器进行非线性的变换,这就是支持向量机。
这里变换的核心是对特征空间进行非线性的变换。比如,对于p个特征x1, …, xp,我们可以通过平方把它们变换到2p维的特征空间,即x1, x12, …, xp, xp2。然后在2p空间内寻找线性的超平面进行分类。虽然超平面在2p维度是线性的,但是由于它是原始特征的二次函数,因此从原始特征空间来看,我们实际上得到了一个非线性的分类器!
那什么是核函数呢?在求解超平面参数的最优化问题中,最优参数的取值仅仅依赖于训练样本特征向量之间的内积。假设两个样本点的特征向量为x和z,则它们的内积为x•z(或者xTz)。假设特征空间的非线性映射为phi,因此在映射后我们的样本特征向量变为phi(x)和phi(z)。在这个新的特征空间求解超平面时,我们需要使用的实际上是phi(x)•phi(z)。对于这个映射,我们定义它对应的核函数为:K(x, z) = phi(x)•phi(z)。
因此,在优化问题的求解中,我们只要把x•z都替换为K(x, z)就相当于是在phi这个映射下的特征空间内求解超平面。当我们知道映射phi的形式后,可以通过分别计算phi(x)和phi(z),然后再求它们的内积得到K(x, z)。然而,这对于计算机来说是非常低效的。假如原始特征空间的维度为p,而我们把它映射到维度为p2的特征空间,则SVM算法的计算量就由O(p)变成了O(p2)。如果p很大的话(在很多实际问题中,p是非常大的),这么做会大大的损害SVM的效率。
对此,核函数的优势是,对于很多应用中常见的特征空间映射phi函数,核函数K(x, z)存在一个非常方便计算的解析式。通过计算这个解析式,我们便可以绕过计算phi(x)和phi(z),而直接得到K(x, z)的取值。然后我们只需要将K(x, z)的值带到最优化参数的解中,便可得到最优的超平面。这大大的降低了SVM的计算时间,使其成为高维空间分类的利器。
让我们来看一个例子,考虑下面这个核函数(它又称作多项式核):
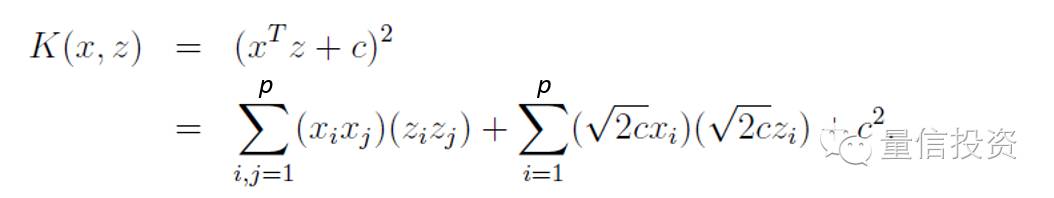
它的计算量只有O(p)。当p=3时,它对应的映射phi却是下面这个13维空间!

仅仅通过计算核函数的表达式就相当于巧妙的进行了从3维到13维空间的非线性映射,这是多么美妙!
SVM的核心就是通过使用核函数(某一个给定的非线性方程),将原始的特征空间变换为更高维的特征空间。
常见的核函数除了上面这个多项式核外,还有径向基(高斯)核。它的表达式如下,这里不再赘述。
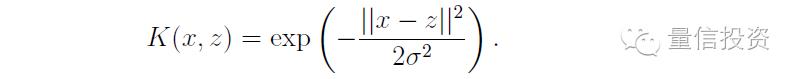
对于前面那个线性分类器无能为力的例子,在使用了适当的核函数后,我们可以在原始特征空间得到非线性的分类边界(下面左图使用了多项式核,右图使用了高斯核)。显然,它们的分类效果比线性分类器的效果要好很多,这是因为它们充分利用了训练数据的非线性特征。
SVM的优缺点
优点:
1 高维度:SVM可以高效的处理高维度特征空间的分类问题。这在实际应用中意义深远。比如,在文章分类问题中,单词或是词组组成了特征空间,特征空间的维度高达10的6次方以上。
2 节省内存:尽管训练样本点可能有很多,但SVM做决策时,仅仅依赖有限个样本(即支持向量),因此计算机内存仅仅需要储存这些支持向量。这大大降低了内存占用率。
3 应用广泛:实际应用中的分类问题往往需要非线性的决策边界。通过灵活运用核函数,SVM可以容易的生成不同的非线性决策边界,这保证它在不同问题上都可以有出色的表现(当然,对于不同的问题,如何选择最适合的核函数是一个需要使用者解决的问题)。
缺点:
1 不易解释因子重要性(这是我自己加的,我认为这条最重要):SVM取得优异的分类效果固然可喜,但人们更愿意知道是哪些因子起了作用(解释因子的重要性)。在这方面,SVM更像是一个黑盒(这可能也是增加其神秘色彩的直接原因)。SVM在特征空间构建了最优的超平面。在数学上,超平面是这p个特征的线性组合,SVM的分类依据是将待分类样本点的特征值带入到这个线性组合中,然后看它的结果是大于0还是小于0。不难看出,在因子的线性组合中,每个因子的系数bj的绝对值的大小可以在一定程度上反映因子的重要性,这是因为当某个因子的系数非常接近0时,该因子对于线性组合的符号的影响会非常微弱。
然而,这种方便的解释仅仅在我们没有使用非线性核的时候适用。当我们使用了一些复杂的非线性核函数将原始特征空间扩展到更高维的特征空间后,我们很难知道新生成的特征长什么样子(即求解时,我们只关心核函数的解析表达式,而“不关心”该核函数对应的特征空间映射phi长什么样子,因此我们就无法知道映射后的特征长什么样子)。因此,即便我们知道某个映射后的因子的系数(的绝对值)很大,如果我们不知道因子的表达式,我们仍然无法解释。再退一步说,即便我们知道映射phi的形式,也知道映射后因子的表达式,映射后的因子仍然是原始因子的非线性方程,例如x1*sqrt(x2)/x3,这种原始因子的复杂非线性组合也许很难从问题本身的业务逻辑中得到令人满意的解释。
2 非概率性:在某些分类问题中,我们希望分类器告诉我们这个样本多大的概率属于第一类,多大的概率属于第二类,这些概率有助于我们判断分类的可信程度。SVM无法直接回答这个问题,因为样本只能在超平面的某一侧。但是我们仍然可以通过计算样本点到超平面的距离来做近似的判断:样本点越远离超平面,它属于该类的可能性越高;样本点越靠近超平面,它属于该类的可能性也相应降低。
3 要求样本数大于特征数:特征数p大于样本数n会使SVM的效果大打折扣。这很好理解。因为如果没有足够的样本,就无法在特征空间中找到真正有效的支持向量,这样在面对新的待分类样本时,SVM的分类效果就会变得很差。
结语
SVM算是有监督分类算法的一个利器。它原理清晰、计算高效、易在高维空间处理非线性关系。但是,和任何一个机器学习算法一样,最难的不是使用一个算法,而是真正明白我们要解决的问题。如果问题的本质需要非线性分类边界,而我们使用了线性的核函数,那结果可想而知。反过来也是一样。
在今后的讨论中,我们还会进一步从实战的角度介绍如何有效的使用SVM。
以上是关于一文看懂支持向量机的主要内容,如果未能解决你的问题,请参考以下文章