技多不压身:支持向量机在 R 语言中的实现和使用
Posted 数盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技多不压身:支持向量机在 R 语言中的实现和使用相关的知识,希望对你有一定的参考价值。
【数盟致力于成为最卓越的数据科学社区,聚焦于大数据、分析挖掘、数据可视化领域,业务范围:线下活动、在线课程、猎头服务、项目对接】
支持向量机是一个相对较新和较先进的机器学习技术,最初提出是为了解决二类分类问题,现在被广泛用于解决多类非线性分类问题和回归问题。继续阅读本文,你将学习到支持向量机如何工作,以及如何利用R语言实现支持向量机。
支持向量机如何工作?
简单介绍下支持向量机是做什么的:
假设你的数据点分为两类,支持向量机试图寻找最优的一条线(超平面),使得离这条线最近的点与其他类中的点的距离最大。有些时候,一个类的边界上的点可能越过超平面落在了错误的一边,或者和超平面重合,这种情况下,需要将这些点的权重降低,以减小它们的重要性。
这种情况下,“支持向量”就是那些落在分离超平面边缘的数据点形成的线。
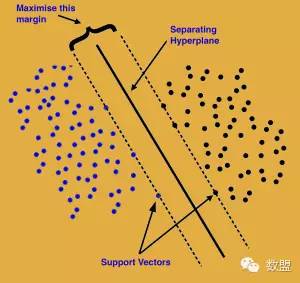
无法确定分类线(线性超平面)时该怎么办?
此时可以将数据点投影到一个高维空间,在高维空间中它们可能就变得线性可分了。它会将问题作为一个带约束的最优化问题来定义和解决,其目的是为了最大化两个类的边界之间的距离。
我的数据点多于两个类时该怎么办?
此时支持向量机仍将问题看做一个二元分类问题,但这次会有多个支持向量机用来两两区分每一个类,直到所有的类之间都有区别。
工程实例
让我们看一下如何使用支持向量机实现二元分类器,使用的数据是来自MASS包的cats数据集。在本例中你将尝试使用体重和心脏重量来预测一只猫的性别。我们拿数据集中20%的数据点,用于测试模型的准确性(在其余的80%的数据上建立模型)。
# Setup library(e1071) data(cats, package="MASS") inputData <- data.frame(cats[, c (2,3)], response = as.factor(cats$Sex)) # response as factor
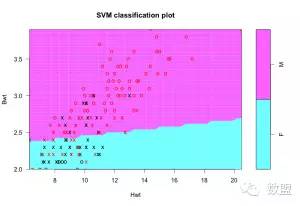
线性支持向量机
传递给函数svm()的关键参数是kernel、cost和gamma。Kernel指的是支持向量机的类型,它可能是线性SVM、多项式SVM、径向SVM或Sigmoid SVM。Cost是违反约束时的成本函数,gamma是除线性SVM外其余所有SVM都使用的一个参数。还有一个类型参数,用于指定该模型是用于回归、分类还是异常检测。但是这个参数不需要显式地设置,因为支持向量机会基于响应变量的类别自动检测这个参数,响应变量的类别可能是一个因子或一个连续变量。所以对于分类问题,一定要把你的响应变量作为一个因子。
# linear SVM svmfit <- svm(response ~ ., data = inputData, kernel = "linear", cost = 10, scale = FALSE) # linear svm, scaling turned OFF print(svmfit) plot(svmfit, inputData) compareTable <- table (inputData$response, predict(svmfit)) # tabulate mean(inputData$response != predict(svmfit)) # 19.44% misclassification error
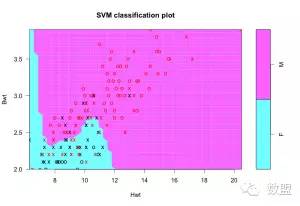
径向支持向量机
径向基函数作为一个受欢迎的内核函数,可以通过设置内核参数作为“radial”来使用。当使用一个带有“radial”的内核时,结果中的超平面就不需要是一个线性的了。通常定义一个弯曲的区域来界定类别之间的分隔,这也往往导致相同的训练数据,更高的准确度。
# radial SVM svmfit <- svm(response ~ ., data = inputData, kernel = "radial", cost = 10, scale = FALSE) # radial svm, scaling turned OFF print(svmfit) plot(svmfit, inputData) compareTable <- table (inputData$response, predict(svmfit)) # tabulate mean(inputData$response != predict(svmfit)) # 18.75% misclassification error
寻找最优参数
你可以使用tune.svm()函数,来寻找svm()函数的最优参数。
### Tuning # Prepare training and test data set.seed(100) # for reproducing results rowIndices <- 1 : nrow(inputData) # prepare row indices sampleSize <- 0.8 * length(rowIndices) # training sample size trainingRows <- sample (rowIndices, sampleSize) # random sampling trainingData <- inputData[trainingRows, ] # training data testData <- inputData[-trainingRows, ] # test data tuned <- tune.svm(response ~., data = trainingData, gamma = 10^(-6:-1), cost = 10^(1:2)) # tune summary (tuned) # to select best gamma and cost
# Parameter tuning of 'svm': # - sampling method: 10-fold cross validation # # - best parameters: # gamma cost # 0.001 100 # # - best performance: 0.26 # # - Detailed performance results: # gamma cost error dispersion # 1 1e-06 10 0.36 0.09660918 # 2 1e-05 10 0.36 0.09660918 # 3 1e-04 10 0.36 0.09660918 # 4 1e-03 10 0.36 0.09660918 # 5 1e-02 10 0.27 0.20027759 # 6 1e-01 10 0.27 0.14944341 # 7 1e-06 100 0.36 0.09660918 # 8 1e-05 100 0.36 0.09660918 # 9 1e-04 100 0.36 0.09660918 # 10 1e-03 100 0.26 0.18378732 # 11 1e-02 100 0.26 0.17763883 # 12 1e-01 100 0.26 0.15055453
结果证明,当cost为100,gamma为0.001时产生最小的错误率。利用这些参数训练径向支持向量机。
svmfit <- svm (response ~ ., data = trainingData, kernel = "radial", cost = 100, gamma=0.001, scale = FALSE) # radial svm, scaling turned OFF print(svmfit) plot(svmfit, trainingData) compareTable <- table (testData$response, predict(svmfit, testData)) # comparison table mean(testData$response != predict(svmfit, testData)) # 13.79% misclassification error
F M F 6 3 M 1 19
网格图
一个2-色的网格图,能让结果看起来更清楚,它将图的区域指定为利用SVM分类器得到的结果的类别。在下边的例子中,这样的网格图中有很多数据点,并且通过数据点上的倾斜的方格来标记支持向量上的点。很明显,在这种情况下,有很多越过边界违反约束的点,但在SVM内部它们的权重都被降低了。
# Grid Plot
n_points_in_grid = 60 # num grid points in a line
x_axis_range <- range (inputData[, 2]) # range of X axis
y_axis_range <- range (inputData[, 1]) # range of Y axis
X_grid_points <- seq (from=x_axis_range[1], to=x_axis_range[2], length=n_points_in_grid) # grid points along x-axis
Y_grid_points <- seq (from=y_axis_range[1], to=y_axis_range[2], length=n_points_in_grid) # grid points along y-axis
all_grid_points <- expand.grid (X_grid_points, Y_grid_points) # generate all grid points
names (all_grid_points) <- c("Hwt", "Bwt") # rename
all_points_predited <- predict(svmfit, all_grid_points) # predict for all points in grid
color_array <- c("red", "blue")[as.numeric(all_points_predited)] # colors for all points based on predictions
plot (all_grid_points, col=color_array, pch=20, cex=0.25) # plot all grid points
points (x=trainingData$Hwt, y=trainingData$Bwt, col=c("red", "blue")[as.numeric(trainingData$response)], pch=19) # plot data points
points (trainingData[svmfit$index, c (2, 1)], pch=5, cex=2) # plot support vectors
文章出处:http://it.taocms.org/03/7221.htm
—————————————————
数盟网站:www.dataunion.org
数盟微博:@数盟社区
数盟微信:DataScientistUnion
数盟【大数据群】272089418
数盟【数据可视化群】 179287077
数盟【数据分析群】 110875722
—————————————————
点击阅读原文,更多精彩技术、资讯内容~
以上是关于技多不压身:支持向量机在 R 语言中的实现和使用的主要内容,如果未能解决你的问题,请参考以下文章