机器学习二十:线性不可分支持向量机与核函数
Posted AI玩转智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习二十:线性不可分支持向量机与核函数相关的知识,希望对你有一定的参考价值。
AI
菌
在前面几篇我们讲到了线性可分SVM的硬间隔最大化和软间隔最大化的算法,它们对线性可分的数据有很好的处理,但是对完全线性不可分的数据没有办法。
本文我们就来探讨SVM如何处理线性不可分的数据,重点讲述核函数在SVM中处理线性不可分数据的作用
一 低纬度到高纬度的思想
在线性回归原理中,我们讲到了如何将多项式回归转化为线性回归。
比如一个只有两个特征的p次方多项式回归的模型:
我们令
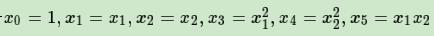
这样我们就得到了下式:
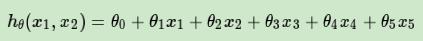
可以发现,我们又重新回到了线性回归,这是一个五元线性回归,可以用线性回归的方法来完成算法
同样,核函数也采用了同样的思想:在线性不可分的情况下,支持向量机通过某种事先选择的非线性映射(核函数)将输入变量映射到一个高维特征空间,并期望映射后的数据在高维空间里是线性可分的。在这个空间中构造最优分类超平面
该映射的效果如下图所示:
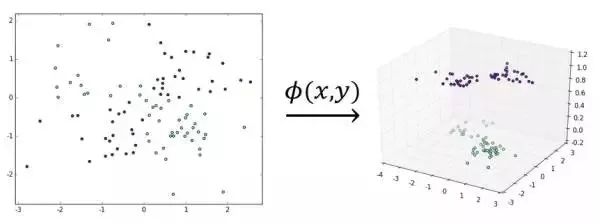
核函数在SVM的引用
刚才我们讲到线性不可分的低维特征数据,我们可以将其映射到高维,就能线性可分
现在我们将它运用到我们的SVM的算法上。回顾线性可分SVM的优化目标函数:
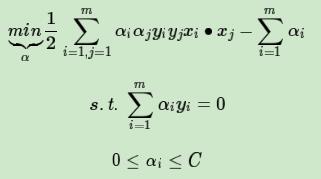
注意到上式低维特征仅仅以内积xi∙xj的形式出现
如果我们定义一个低维特征空间到高维特征空间的映射ϕ(比如上一节2维到5维的映射),将所有特征映射到一个更高的维度,让数据线性可分
我们就可以继续按前两篇的方法来优化目标函数,求出分离超平面和分类决策函数了。也就是说现在的SVM的优化目标函数变成:
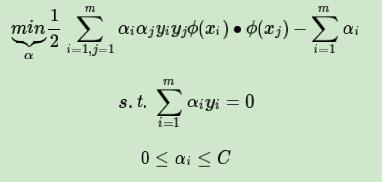
可以看到,和线性可分SVM的优化目标函数的区别仅仅是将内积
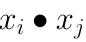
替换为
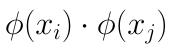
看起来似乎这样我们就已经完美解决了线性不可分SVM的问题了
至此,似乎问题就转化为了如何寻找合适的映射 ϕ ,使得数据集在被它映射到高维空间后变得线性可分
不过可以想象的是,现实任务中的数据集要比上文我们拿来举例的异或数据集要复杂得多、直接构造一个恰当的 ϕ 的难度甚至可能高于解决问题本身
而且假如是一个2维特征的数据,我们可以将其映射到5维来做特征的内积,似乎还可以处理。
但是如果我们的低维特征是100个维度,1000个维度呢?那么我们要将其映射到超级高的维度来计算特征的内积。
这时候映射成的高维维度是爆炸性增长的,这个计算量实在是太大了,而且如果遇到无穷维的情况,就根本无从计算了。
这个时候就可以引入我们的核函数了
什么是核函数
假设ϕ是一个从低维的输入空间χ(欧式空间的子集或者离散集合)到高维的希尔伯特空间的H映射。那么如果存在函数
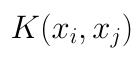
对于任意xi , xj∈χ,都有:
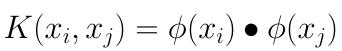
那么我们就称下面这个式子为核函数
仔细观察上式可以发现
的计算是在低维特征空间来计算的,而将实质上的分类效果(利用了内积)表现在了高维上,这样避免了直接在高维空间中的复杂计算
换句话说,核方法的思想如下:
1.将算法表述成样本点内积的组合(这经常能通过算法的对偶形式实现)
2.设法找到核函数
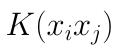
它能返回样本点
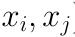
被 ϕ 作用后的内积
3.用
替换
完成低维到高维的映射(同时也完成了从线性算法到非线性算法的转换)
核函数的介绍
事实上,核函数的研究非常的早,要比SVM出现早得多,当然,将它引入SVM中是最近二十多年的事情
对于从低维到高维的映射,核函数不止一个。那么什么样的函数才可以当做核函数呢?这是一个有些复杂的数学问题。这里不多介绍
下面我们来看看常见的核函数:
线性核函数
其实就是我们前两篇的线性可分SVM,表达式为:
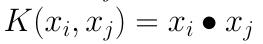
我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
多项式核函数
多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为:
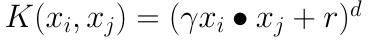
其中,γ,r,d都需要自己调参定义,可以实现将低维的输入空间映射到高纬的特征空间
但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算
高斯核函数
高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF)
它是非线性分类SVM最主流的核函数。libsvm默认的核函数就是它。表达式为:
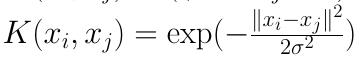
其中,γ大于0,需要自己调参定义
该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数
Sigmoid核函数
Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为:
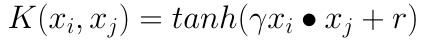
其中,γ,r都需要自己调参定义
采用sigmoid核函数,支持向量机实现的就是一种多层神经网络
因此,在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证的方法,来试用不同的核函数,误差最下的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。
在吴恩达的课上,也曾经给出过一系列的选择核函数的方法:
1.如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
2.如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
3.如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
分类SVM的算法小结
引入了核函数后,我们的SVM算法才算是比较完整了。现在我们对分类SVM的算法过程做一个总结。不再区别是否线性可分。
输入是m个样本
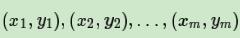
其中x为n维特征向量。y为二元输出,值为1,或者-1.
输出是分离超平面的参数和 w∗ 和 b∗和分类决策函数。
算法过程如下:
1)选择适当的核函数和一个惩罚系数C>0, 构造约束优化问题
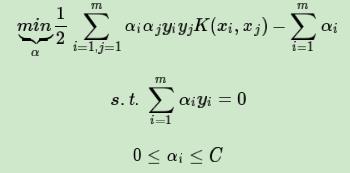
2)用SMO算法求出上式最小时对应的α向量的值α∗向量
3) 得到
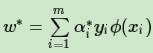
此处可以不直接显式的计算w∗
4) 找出所有的S个支持向量,即满足
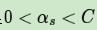
对应的样本 (xs,ys) 通过
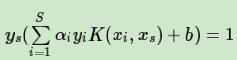
计算出每个支持向量 (xs,ys) 对应的 bs∗,计算出这些
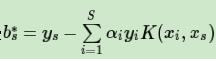
.所有的bs∗对应的平均值即为最终的
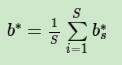
这样最终的分类超平面为:
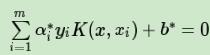
,最终的分类决策函数为:
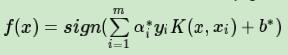
AI
菌
至此,我们的分类SVM算是总结完毕,唯一的漏网之鱼是SMO算法,这个算法关系到,我们如何求出优化函数极小化时候的α∗,进而求出w,b,我们将在下一篇讨论这个问题。
不失初心,不忘初衷
AI玩转智能
以上是关于机器学习二十:线性不可分支持向量机与核函数的主要内容,如果未能解决你的问题,请参考以下文章