13支持向量机SVM:SMO算法
Posted FinTech修行僧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了13支持向量机SVM:SMO算法相关的知识,希望对你有一定的参考价值。
支持向量机SVM
4、序列最小最优化算法SMO
本节讨论支持向量机的具体实现。
我们知道,支持向量机的学习问题可以形式化为求解凸二次规划问题,这样的凸二次规划具有全局最优解,并且有许多最优化算法可以用于这一问题的求解。
但是,当训练样本容量很大时,这些算法往往变得非常低效,以致无法使用,所以,如何高效地实现支持向量机学习就成为关键,而序列最小最优化算法(sequential minimal optimization,SMO)便可以解决这个问题。
其中, (xi,yi)为训练样本数据,xi为样本特征,yi ∈{+1,-1}为样本标签,C是惩罚系数且由用户自己设定。
上述问题是要求解N个参数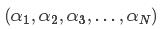 ,其他参数(指x,y和C)均为已知,有多种算法可以对上述问题求解,但是算法复杂度均很大。
,其他参数(指x,y和C)均为已知,有多种算法可以对上述问题求解,但是算法复杂度均很大。
但1998年,由Platt提出的序列最小最优化算法(SMO)可以高效的求解上述SVM问题,它把原始求解N个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解2个参数。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。

SMO算法的基本思想
SMO算法是一种启发式算法,其核心思想是:如果所有变量的解都满足此最优化问题的KKT条件,那么这个最优化问题的解就得到了。
SMO的基本思路是:每次选择两个变量αi和αj,并固定其他参数(即其余N-2个α)。这样,在参数初始化后,SMO不断执行如下两个步骤直至收敛:
(1)选取一对需要更新的变量αi和αj ;
(2)固定αi和αj以外的参数,求解下式,获得更新后的αi和αj ;
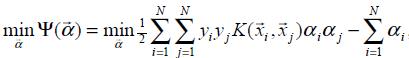
注意:αi和αj的选择不是任意的,应按照相应的准则,之后会详细解释这个准则;
SMO算法之所以高效,恰由于在固定其他参数后,仅优化两个参数的过程能做到非常高效。
整个SMO算法包括两大部分:求解两个变量二次规划的解析方法和选择变量的启发式方法。
求解两个变量二次规划的解析方法

将最优化目标函数视为一个二元函数
为了求解N个参数,首先想到的是坐标上升法。例如,求解α1,可以固定其他N-1个参数,于是便可以将目标函数的优化问题,看成关于α1的一元一次函数求解。
但是注意到上述问题的等式约束条件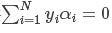 ,当固定其它参数时,参数α1也就被固定了,因此这种方法不可用。
,当固定其它参数时,参数α1也就被固定了,因此这种方法不可用。
SMO算法选择同时优化两个参数,固定其他N-2个参数。假设选择的参数为α1和α2,固定其他参数 。由于参数的固定,可以简化目标函数为只关于α1,α2的二元函数,
。由于参数的固定,可以简化目标函数为只关于α1,α2的二元函数,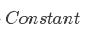 表示常数项(即不包含参数α1,α2的项),即
表示常数项(即不包含参数α1,α2的项),即
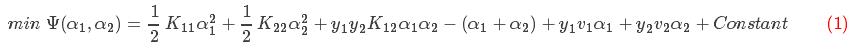
其中,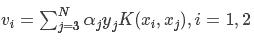
进而视为一元函数
由等式约束得: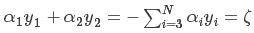 ,可见 ξ 为定值。
,可见 ξ 为定值。
等式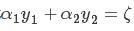 两边同时乘以y1,
两边同时乘以y1,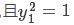 ,得:
,得:
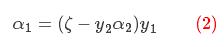
将(2)式带回到(1)中得到只关于参数α2的一元函数,由于常数项不影响目标函数的解,以下省略掉常数项,如下所示:
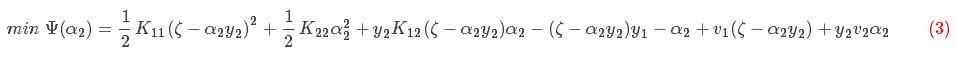
对此一元函数求极值点
上式中关于参数α2的函数,对上式求导,并令其为0得:
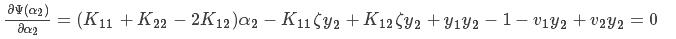
从上式中我们可求出α2的解,具体推导如下:
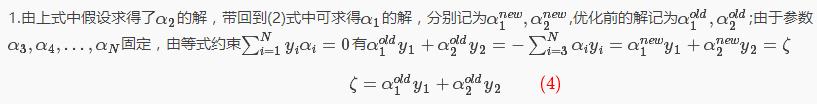

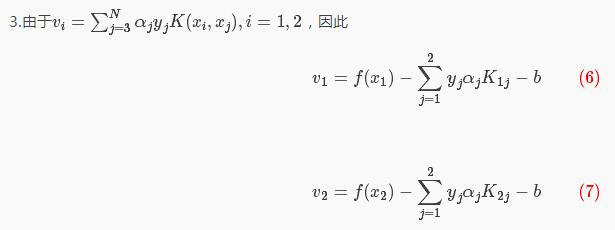
把(4)(6)(7)式带入下式中:
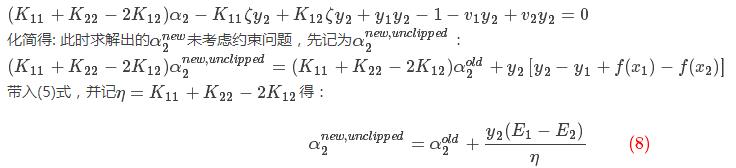
对上述中求得的原始解进行修剪
上述求得的解未考虑到约束条件:
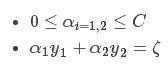
在二维平面上直观表达上述两个约束条件,如下:
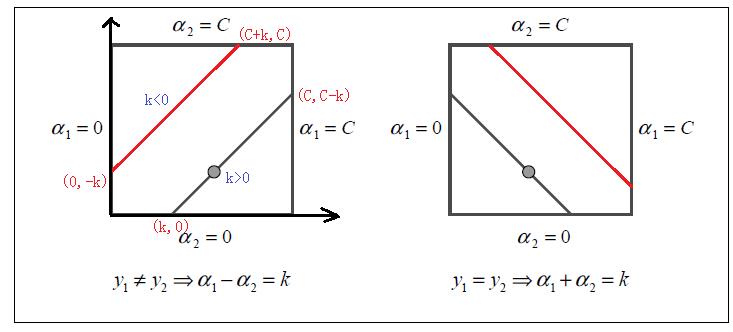

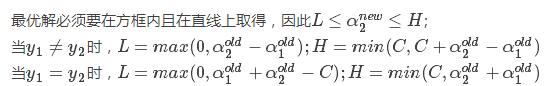
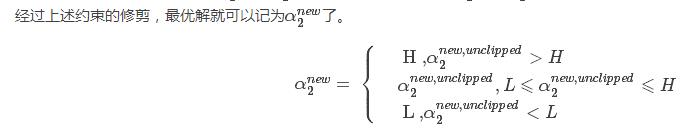
求解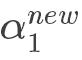 :
:
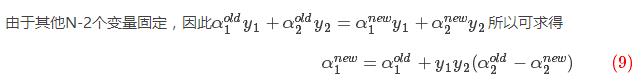
取临界情况



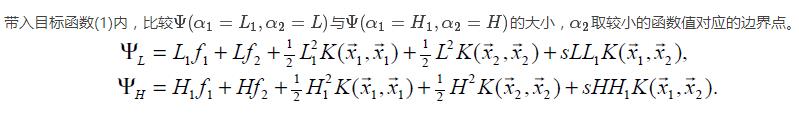
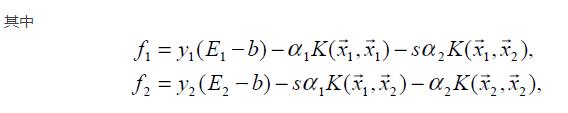
选择变量的启发式方法(选取参数的准则)
第1个变量的选择(外循环)
SMO称选择第1个变量的选择过程为外循环。
外层循环首先遍历整个样本集,选择违反KKT条件最严重的样本点,并将其对应的变量作为第一个变量。具体地,检验训练样本点(xi,yi)是否满足KKT条件,即
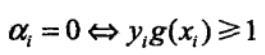
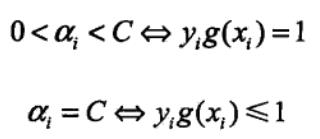
其中,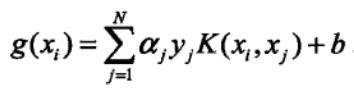 为分类决策函数。
为分类决策函数。
在检验过程中,外层循环首先遍历所有满足条件0<αi<C的样本点,即在间隔边界上的支持向量点,检验它们是否满足KKT条件。
如果这些样本点都满足KKT条件,那么遍历整个训练集,检验它们是否满足KKT条件。
第2个变量的选择(内循环)
SMO称选择第2个变量的过程为内循环。
假设在外循环中找到第1个变量并记为α1,第2个变量选择的标准是希望能使α2有足够大的变化。
令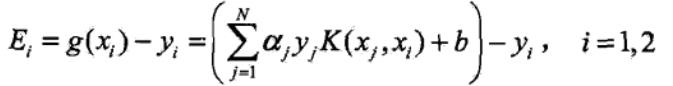
当 i = 1,2时,Ei为函数g(x)对输入 xi 的预测值与真实输出 yi 之差。
由于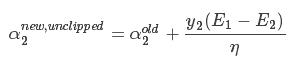 和
和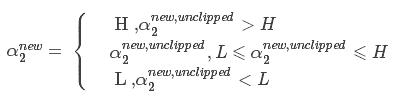
,我们知道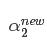 是依赖于|E1-E2|的,为了加快计算速度:
是依赖于|E1-E2|的,为了加快计算速度:
选择α2的第一种方法是,选择α2使其对应的|E1-E2|最大。
因为α1已定,E1也就确定了。如果E1为正,那么选择最小的Ei作为E2;如果E1是负的,那么选择最大的Ei作为E2。通常将所有的E值保存在一个列表中。
选择α2的第二种方法
如果内层循环通过第一种方法选择的α2不能使目标函数有足够的下降,那么采用以下启发式规则继续选择α2:
首先,遍历在间隔边界上的支持向量点,依次将其对应的变量作为α2试用,直到目标函数有足够的下降;
若找不到合适的α2,那么遍历训练数据集;
若仍找不到合适的α2,则放弃第1个α1,再通过外层循环寻求另外的α1 。
阈值b的计算
在每次完成两个变量的优化后,都要重新计算阈值b,因为b 的值关系到f(x)的计算,即关系到下次优化时Ei 的计算。
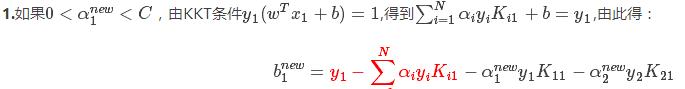
由(5)式得,上式前两项可以替换为:
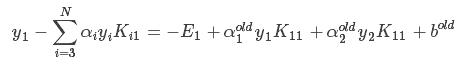
得出:
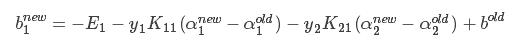
2、如果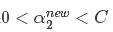 ,则:
,则:
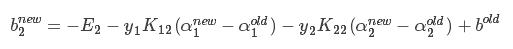
3、如果同时满足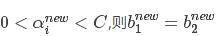 ;
;
4、如果同时不满足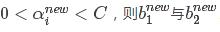 以及它们之间的数都是符合KKT条件的阈值,这时选择它们的中点作为bnew。
以及它们之间的数都是符合KKT条件的阈值,这时选择它们的中点作为bnew。
SMO算法总结
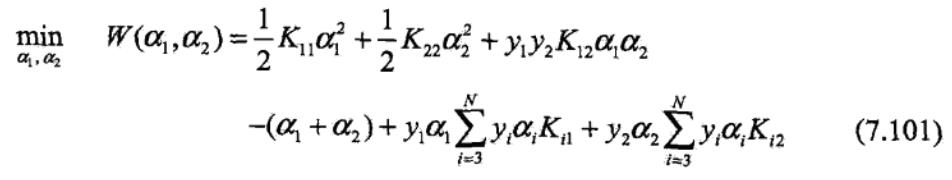
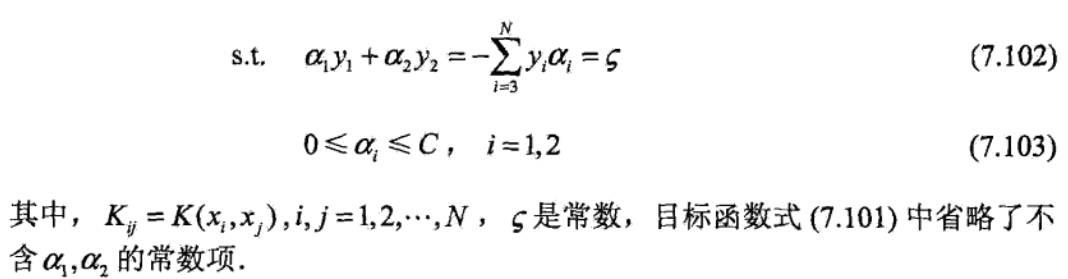
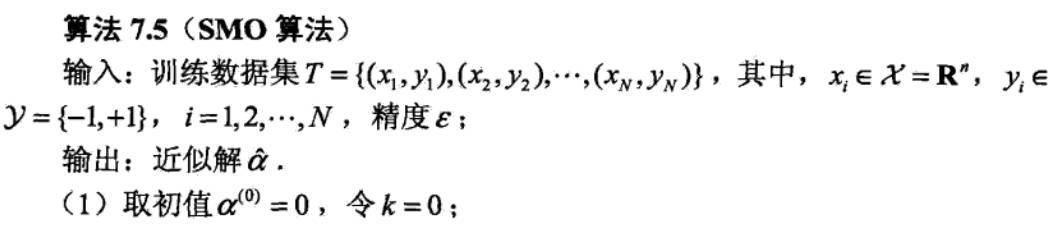

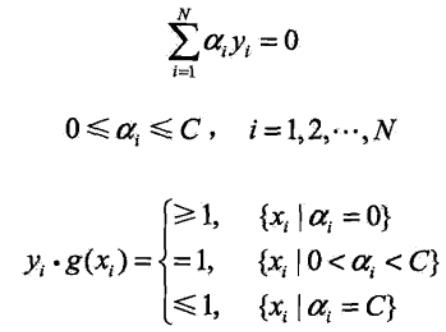
【1】李航 · 统计学习方法 · 清华大学出版社 第七章
【2】周志华 · 机器学习 · 清华大学出版社 第六章
【3】SMO算法剖析 http://blog.csdn.net/luoshixian099/article/details/51227754
【4】用讲故事的办法帮你理解SMO算法 http://www.jianshu.com/p/55458caf0814
【5】SMO算法 http://blog.csdn.net/susu_love/article/details/53377010
【6】Sequential Minimal Optimization:A Fast Algorithm for Training Support Vector Machines,John C. Platt
以上是关于13支持向量机SVM:SMO算法的主要内容,如果未能解决你的问题,请参考以下文章