样本虽小,支持向量机也能一次搞定!
Posted 哈希大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了样本虽小,支持向量机也能一次搞定!相关的知识,希望对你有一定的参考价值。
哈希大数据致力于互联网、金融、物流等行业大数据采集、分析、营销与决策提供综合解决方案。

支持向量机(Support Vecor Machine,以下简称SVM)虽然诞生只有短短的二十多年,但是自一诞生便由于它良好的分类性能席卷了机器学习领域,并牢牢压制了神经网络领域好多年。如果不考虑集成学习的算法,不考虑特定的训练数据集,在分类算法中的表现SVM说是排第一估计是没有什么异议的。
SVM是一个二元分类算法,线性分类和非线性分类都支持。经过演进,现在也可以支持多元分类,同时经过扩展,也能应用于回归问题。本系列文章就对SVM的原理做一个总结。本篇的重点是SVM用于线性分类时模型和损失函数优化的一个总结。
阅读目录
1.回顾感知机模型
2.函数间隔与几何间隔
3.支持向量
4.SVM模型目标函数与优化
5.线性可分SVM的算法过程

1. 回顾感知机模型
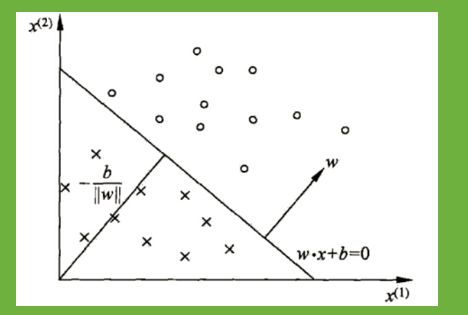
在感知机原理小节中,我们讲到了感知机的分类原理,感知机的模型就是尝试找到一条直线,能够把二元数据隔离开。放到三维空间或者更高维的空间,感知机的模型就是尝试找到一个超平面,能够把所有的二元类别隔离开。对于这个分离的超平面,我们定义为: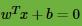 。如下图。在超平面上方的我们定义为y=1,在超平面下方的我们定义为y=-1。可以看出满足这个条件的超平面并不止一个。那么我们可能会尝试思考,这么多的可以分类的超平面,哪个是最好的呢?或者说哪个是泛化能力最强的呢?
。如下图。在超平面上方的我们定义为y=1,在超平面下方的我们定义为y=-1。可以看出满足这个条件的超平面并不止一个。那么我们可能会尝试思考,这么多的可以分类的超平面,哪个是最好的呢?或者说哪个是泛化能力最强的呢?
接着我们看感知机模型的损失函数优化,它的思想是让所有误分类的点(定义为M)到超平面的距离和最小,即最小化式: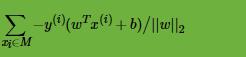
当
w
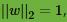 即最终感知机模型的损失函数为:
即最终感知机模型的损失函数为: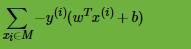
如果我们不是固定分母,改为固定分子,作为分类模型有没有改进呢?
这些问题在我们引入SVM后会详细解释。
2. 函数间隔与几何间隔
在正式介绍SVM的模型和损失函数之前,我们还需要先了解下函数间隔和几何间隔的知识。
在分离超平面固定为的时候,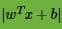
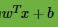 和y是否同号,我们判断分类是否正确,这些知识我们在感知机模型里都有讲到。这里我们引入函数间隔的概念,定义函数间隔
和y是否同号,我们判断分类是否正确,这些知识我们在感知机模型里都有讲到。这里我们引入函数间隔的概念,定义函数间隔
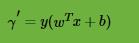
可以看到,它就是感知机模型里面的误分类点到超平面距离的分子。对于训练集中m个样本点对应的m个函数间隔的最小值,就是整个训练集的函数间隔。
函数间隔并不能正常反应点到超平面的距离,在感知机模型里我们也提到,当分子成比例的增长时,分母也是成倍增长。为了统一度量,我们需要对法向量
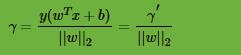
几何间隔才是点到超平面的真正距离,感知机模型里用到的距离就是几何距离。
3. 支持向量
在感知机模型中,我们可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点都离超平面远。但是实际上离超平面很远的点已经被正确分类,我们让它离超平面更远并没有意义。反而我们最关心是那些离超平面很近的点,这些点很容易被误分类。如果我们可以让离超平面比较近的点尽可能的远离超平面,那么我们的分类效果会好有一些。SVM的思想起源正起于此。
如下图所示,分离超平面为,如果所有的样本不光可以被超平面分开,还和超平面保持一定的函数距离(下图函数距离为1),那么这样的分类超平面是比感知机的分类超平面优的。可以证明,这样的超平面只有一个。和超平面平行的保持一定的函数距离的这两个超平面对应的向量,我们定义为支持向量,如下图虚线所示。
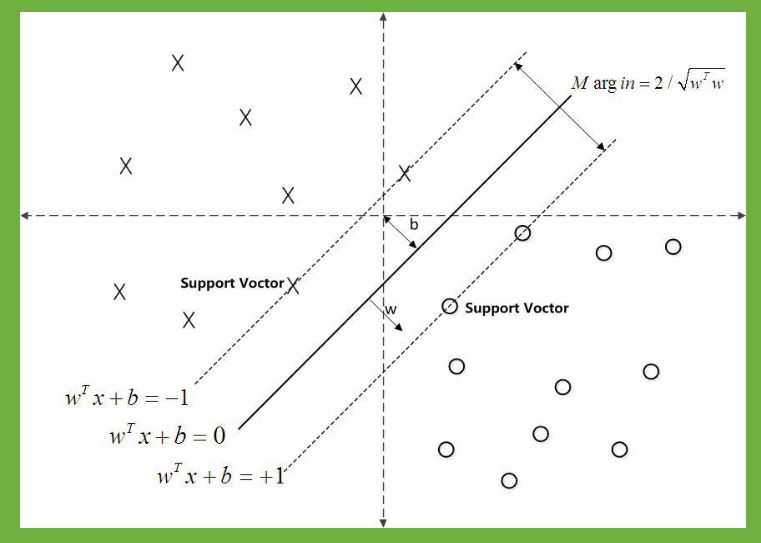
支持向量到超平面的距离为
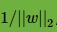 ,两个支持向量之间的距离为
,两个支持向量之间的距离为 。
。
4. SVM模型目标函数与优化
SVM的模型是让所有点到超平面的距离大于一定的距离,也就是所有的分类点要在各自类别的支持向量两边。用数学式子表示为:
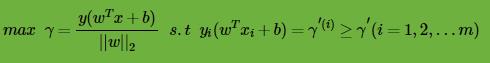
一般我们都取函数间隔
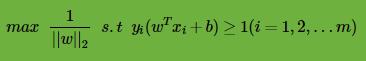
也就是说,我们要在约束条件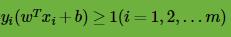 下,最大化
下,最大化
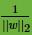 。可以看出,这个感知机的优化方式不同,感知机是固定分母优化分子,而SVM是固定分子优化分母,同时加上了支持向量的限制。
。可以看出,这个感知机的优化方式不同,感知机是固定分母优化分子,而SVM是固定分子优化分母,同时加上了支持向量的限制。
由于的最大化等同于 的最小化。这样SVM的优化函数等价于:
的最小化。这样SVM的优化函数等价于:
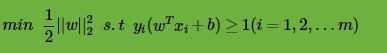
由于目标函数凸函数,同时约束条件不等式是仿射的,根据凸优化理论,我们可以通过拉格朗日函数将我们的优化目标转化为无约束的优化函数,这和最大熵模型原理小结中讲到了目标函数的优化方法一样。具体的,优化函数转化为:
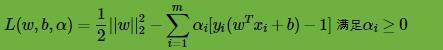
由于引入了朗格朗日乘子,我们的优化目标变成:
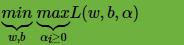
和最大熵模型一样的,我们的这个优化函数满足KKT条件,也就是说,我们可以通过拉格朗日对偶将我们的优化问题转化为等价的对偶问题来求解。如果对凸优化和拉格朗日对偶不熟悉,建议阅读鲍德的《凸优化》。
也就是说,现在我们要求的是:

从上式中,我们可以先求优化函数对于
首先我们来求
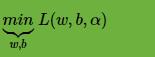 。这个极值我们可以通过对
。这个极值我们可以通过对
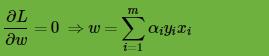
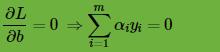
从上两式子可以看出,我们已经求得了
好了,既然我们已经求出
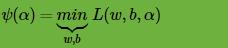
现在我们来看将

其中,(1)式到(2)式用到了范数的定义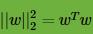 ,(2)式到(3)式用到了上面的
,(2)式到(3)式用到了上面的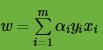 ,(3)式到(4)式把和样本无关的
,(7)式到(8)式用到了向量的转置。由于常量的转置是其本身,所有只有向量
,(3)式到(4)式把和样本无关的
,(7)式到(8)式用到了向量的转置。由于常量的转置是其本身,所有只有向量
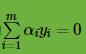 ,(9)式到(10)式使用了
,(9)式到(10)式使用了
从上面可以看出,通过对
对
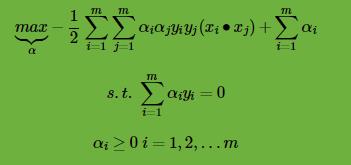
可以去掉负号,即为等价的极小化问题如下:
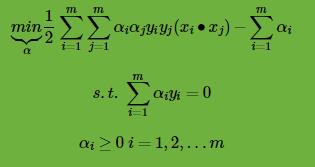
只要我们可以求出上式极小化时对应的
那么我们根据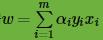 ,可以求出对应的
,可以求出对应的
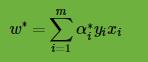 。
。
求b则稍微麻烦一点。注意到,对于任意支持向量 ,都有
,都有
假设我们有S个支持向量,则对应我们求出S个
怎么得到支持向量呢?根据KKT条件中的对偶互补条件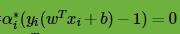 ,如果
,如果
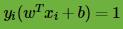 即点在支持向量上,否则如果
即点在支持向量上,否则如果
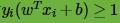 ,即样本在支持向量上或者已经被正确分类。
,即样本在支持向量上或者已经被正确分类。
5. 线性可分SVM的算法过程
这里我们对线性可分SVM的算法过程做一个总结。
输入是线性可分的m个样本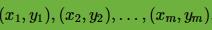 ,其中x为n维特征向量。y为二元输出,值为1,或者-1。
,其中x为n维特征向量。y为二元输出,值为1,或者-1。
输出是分离超平面的参数
算法过程如下:
1)构造约束优化问题
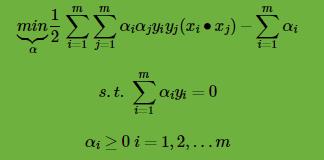
2)用SMO算法求出上式最小时对应的
3) 计算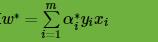
4) 找出所有的S个支持向量,即满足 对应的样本
对应的样本 通过
通过
 ,
计算出每个支持向量对应的
,
计算出每个支持向量对应的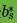 ,计算出这些
,计算出这些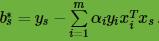 。所有的对应的平均值即为最终的
。所有的对应的平均值即为最终的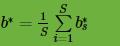 。
。
这样最终的分类超平面为: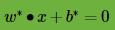 ,最终的分类决策函数为:
,最终的分类决策函数为: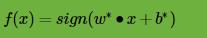 。
。
线性可分SVM的学习方法对于非线性的数据集是没有办法使用的, 有时候不能线性可分的原因是线性数据集里面多了少量的异常点,由于这些异常点导致了数据集不能线性可分, 那么怎么可以处理这些异常点使数据集依然可以用线性可分的思想呢? 我们在下一节的线性SVM的软间隔最大化里继续讲。


SVM周正式开启,接上次推送的刘建平老师的感知机原理,一一讲解支持向量机原理,将陆续推出以下五大内容:
支持向量机原理(一) 线性支持向量机
支持向量机原理(二)线性支持向量机的软间隔最大化模型
支持向量机原理(三)线性不可分支持向量机与核函数
支持向量机原理(四)SMO算法原理
支持向量机原理(五)线性支持回归
刘建平老师的博客:
http://www.cnblogs.com/pinard

如果我们可以用颜色比喻,
那是爱过你才能成为灰色的自己
——《灰色》
以上是关于样本虽小,支持向量机也能一次搞定!的主要内容,如果未能解决你的问题,请参考以下文章