支持向量机(第一章)
Posted 易智能EasyAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机(第一章)相关的知识,希望对你有一定的参考价值。
支持向量机和核方法是机器学习的一个重要概念,人工智能领域非常重要的著作《神经网络和机器学习》以及《深入理解机器学习》等都会开辟两章来专门介绍。但是这些大而全的专家著作一上来往往就直接用上非常艰深的数学公式,让数学学得不全面的读者一头雾水。因为一般理科本科毕业的学生也不见得全面的学习过概率论,测度论,信息论,最优化理论,统计学,离散数学,偏微分方程……
在国内很难找到一本由浅入深,又不贪大求全的机器学习方面的好书,我也是在硬着头皮看过很多人工智能及机器学习方面的书后,决定痛定思痛,抛开贪婪之心,把自己看作是一个小学生,重新从基础来学习机器学习。有幸让我偶尔从网上翻到这本由SYNCFUSION网站免费推出的 Support Vector Machines Succinctly。
常听人说从小学就可以学习编程,而确实我们身边也有一大堆高中生程序员。当然学历并不重要,重要的是人工智能还是对数学有要求的,我喜欢书中有意无意提到的一句话,先了解数学理论,再编程。
高兴的是,这本书对数学的要求并不高,至少前三章,高中数学水平就可以解决了。这也使这本书不仅仅对学习机器学习的人有用,而对那些想了解机器学习或人工智能到底是怎么回事的文科生也可放心一读。
但简单不是目的,这本书从只需要简单的数学知识开始,逐渐带领你进入机器学习的大门,并且在最后列出继续前进的方向。更难能可贵的是,本书让支持向量机和核方法自成体系,完全可以独立解决很多机器学习方面的问题。
我翻译本书的目的是为了更好的和机器学习爱好者交流,尽管看英文原本更好,必竟我的翻译水平有限,但是还是希望可以帮助到一些不原意看英文书的朋友。
前言
这本书为谁而写?
这本书的目标是提供一个支持向量机的普通概述。你将学到什么是支持向量机,它能解决什么问题,我们怎么使用它。我试图使这本书对各种类型的读者都有用。软件工程师可以找到大量的有简单说明相关算法的代码例子。一个深入的研究者可以知道支持向量机的内部是如何工作的将使你获得更好的实现。
学生们第一次接确支持向量机就可以找到大量的主题来增加学习兴趣。我也尝试
提供更多的资料给感兴趣继续深入学习的朋友。
你该怎样读这本书?
因为本书每一章都是基于其前一章的内容来写的,所以按顺序读这本书是最好的方式。
参考文献
在本书的末尾列出了大量参考文献的列表。文章引用时以每一篇论文或书的作者和出版日期来列。例如,(Bishop,2006)是指文献列表中的这一行:
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
代码表
本书中的代码表中的代码是用Pycharm IDE,Community Editon 2016.2.3来写的,用WinPython 64-bit 3.5.1.2 来执行。你可以在Bitbucket 网站上找到本书的相关源码。
简介
支持向量机(SVM)是性能最好的现有监督学习算法之一。意思是当你有一个问题需要解决并使用了SVM,你将得到了个很好的结果并且没有什么漏洞。之所以这么说,是因为它基于强大的数学理论。有好多种支持向量机,这也是为什么我总是用SVMs来表示。这本书的目标就是让人理解它们是怎样工作的。
SVMs的成功来自于几个人多年的努力。第一个SVM算法归于1963年的Vladimir Vapnic,他后来与Alexey Chervonenkis紧密合作,提出了广为人知的VC理论,试图从统计视角来解释学习过程。
在现实中,SVMs在三个主要领域得到成功的应用:文本分类,图像识别和生物信息学(Cristianini & Shawe-Taylor,2000)。主要应用实例包括新闻分类,手写识别和肿瘤组织采样。
在首章,我们关心一下重要的概念:向量,线性分割和超平面。它们是让你理解SVMs的基石。在第二章,我们将跳出主题,而是学习一个简单的感知器算法。不要跳过——尽管它不是讲SVMs,这章将给你一个宝贵的洞察,为什么SVMs能更好的分类数据。
第三章将一步一步去构造SVM优化问题。第四章,可能是最难的,将展示怎样去解决问题——先是数学理论上的,然后才是编程。在第五章,我们将发现一个新的支持向量机软边界SVM。我们将看到它怎样去改善原始问题。
第六章将介绍核和解释什么叫"核方法"。基于这个方法我们将得核SVM,它是现在非常流行的技术。在第七章,我们将学到SMO,一个快速解决SVM优化算法问题的算法。在第八章,我们将看到SVMs可以用来分类多个类别。
每一章都包含示例代码和图示让你理解这些概念相当容易。当然,这本书没法包含所有主题,所以有些将不被讲到。在本书结尾,你将找到你要学习SVMs的前进方向。
让我们现在就开始愉快的旅程。
第一章 预备知识
本章将介绍一些为了更好理解SVMs所必需知道的一些基础。我们首先看到什么是向量和它的主要属性。然后我们学习数据的线性分割的意思前的一个关键概念:超平面。
向量(Vectors)
在支持向量机里有一个词叫向量。关于向量的一些基本知识对于理解SVMs和怎样使用它是相当重要的。
什么是向量?
向量是一个数学对象可以表示为一个箭头(图1)。
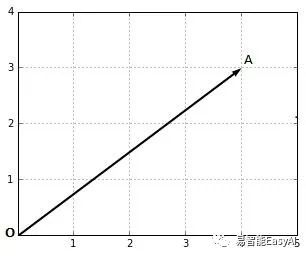
图1:向量表示
当我们计算时,我们注意到向量在坐标上的端点(箭头的终点)。在图1中,点A的坐标是(4,3)。我们可以写成:
![]()
如果我们想,我们可以给这个向量一个另外的名称,比如,a。
![]()
从这个点来看,我们可能会以为向量是用它的坐标来定义的。
然而,假如我给你一张白纸上面仅有一条横线请你画出与图1相同的向量,你还是能做到的。
你只要知道两个信息:
这个向量有多长?
这个向量与横线的夹角多大?
这让我们用下面的定义来定义向量:
向量是一个有数值和方向的对象。
向量的值
值或者长度,对于向量x可以写成||X||,称之为范数(norm)。
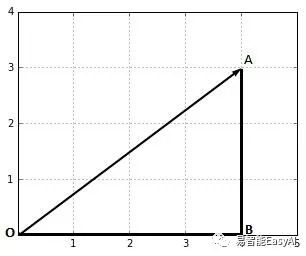
图2:向量的值是线段OA的长度
在图2,我们能用毕达哥拉期定理计算向量![]() 范数||OA||:
范数||OA||:
![]()
![]()
![]()
![]()
![]()
通常,我们计算向量![]() 的范数可用欧几里德的范数公式:
的范数可用欧几里德的范数公式:
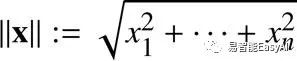
用Python,计算范式用numpy模块的norm方法可以很容易得到范式,见代码表1。
代码表1
import numpy as np
x = [3,4]
np.linalg.norm(x) # 5.0
向量的方向
方向是向量的第二个组成部分。根据定义,它是用从原点出发的向量的坐标除以范式得到的一个新的向量。
这个向量的方向是向量![]() 可表示为:
可表示为:
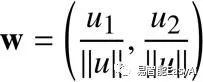
它可以用Python来计算,代码见代码表2:
代码表2
import numpy as np
# Compute the direction of a vector x.
def direction(x):
return x/np.linalg.norm(x)
它是怎么来的呢?几何上 。图3展示了向量u与模纵坐标线的角度。角![]() (theta)是向量与横坐标的夹角,角
(theta)是向量与横坐标的夹角,角![]() (alpha)是向量与纵坐标的夹角。
(alpha)是向量与纵坐标的夹角。
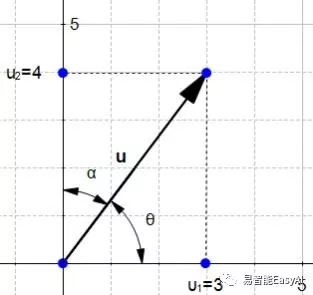
图3:在坐标上,向量u和它的两个夹角
应用初等几何,我们知道
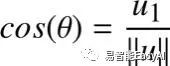 和
和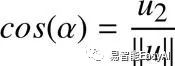 ,所以w又
,所以w又
可以定义为:
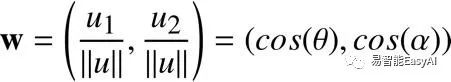
w的坐标用余弦来定义。所以,当u与坐标的夹角发生变化,则u的方向也发生了变化。我们可以计算出w的值(代码表3),我们发现它的坐标是(0.6,0.8)。
代码表3
u = np.array([3,4])
w = direction(u)
print(w) # [0.6 , 0.8]
有趣的是如果两个向量的方向相同,则它们有相同的方向向量(代码表4)。
代码表4
u_1 = np.array([3,4])
u_2 = np.array([30,40])
print(direction(u_1)) # [0.6 , 0.8]
print(direction(u_2)) # [0.6 , 0.8]
此外,方向向量的范数恒为1。我们可以用向量w=(0.6,0.8)来验证(代码表5)。
代码表5
np.linalg.norm(np.array([0.6, 0.8])) # 1.0
我们现在知道,任何一个向量的方向向量都可以表示成一个范数为1的向量,它是简单易行的。所以,一个方向向量如w经常被定义为单位向量。
向量的维数
请注意数字的个数是非常重要的,因为,我们说一个n-维的向量意思是它有n个实际数字。
比如,w=(0.6,0.8)是2-维向量;我们常常写成![]() (w属于
(w属于![]() )
)
,类似的,向量u=(5,3,2)是3-维向量,![]()
。
点积
点积是两个向量进行运算返回一个数值。这个数值有时称为数量(scalar);这就是为什么点积有时也称为数量积。
人们往往对点积感到困惑因为它看起来没有道理。但是通过运算知道两个向量之间的关系又是相当重要的,这里有两个方向让我们来思考点积。
点积的几何定义
几何学上,点积是两个向量的欧几里德数值和这两个向量之间夹角的余弦的积。
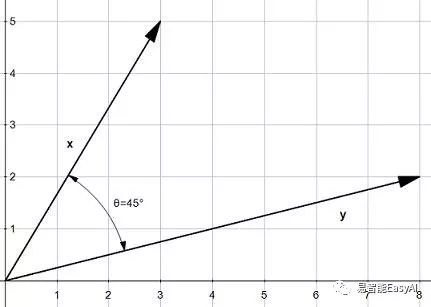
图4:两个向量x和y
意思是假如我们有两个向量,x和y,它们的夹角为(图4),则它们的点积为:
![]()
通过下面的公式,我们可以看到点积受到夹角的强烈影响:
当![]() ,我们得到
,我们得到![]() 和
和![]()
当![]() ,我们得到
,我们得到![]() 和
和![]()
当![]() ,我们得到
,我们得到![]() 和
和![]()
记住这些,当我们学到传感器学习数法时它将非常有用。
我们可以写一个简单的Python方法根据定义来计算点积(代码表6)和用它来得到图4所显示的向量的点积(代码表7)。
代码表6
import math
import numpy as np
def geometric_dot_product(x,y, theta):
x_norm = np.linalg.norm(x)
y_norm = np.linalg.norm(y)
return x_norm * y_norm * math.cos(math.radians(theta))
不管怎样,我们需要知道的值才能计算点积。
代码表7
theta = 45
x = [3,5]
y = [8,2]
print(geometric_dot_product(x,y,theta)) # 34.0
点积的代数定义
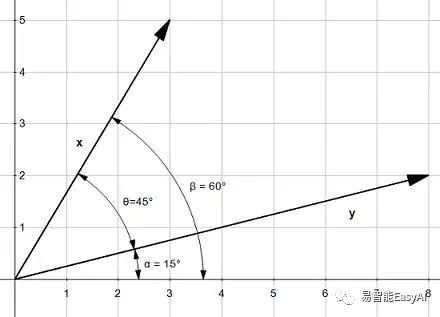
图5:利用这三个角可以简化点积
在图5中,我们可以看到三个角![]() ,
,![]() (beta), and
(beta), and![]() (alpha):
(alpha):
![]()
意思是计算![]() 和计算
和计算![]() 是一回事。
是一回事。
用这个表示方法求余弦我们得到:
![]()
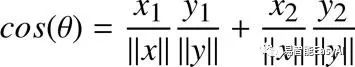
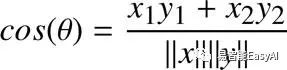
如果我们两边都除以![]() 得:
得:
![]()
我们已经知道:
![]()
这就意味着点积也可以写成:
![]()
或:
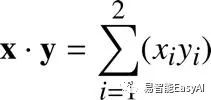
在更一般化的情况下,n-维向量的点积,我们可以写成:
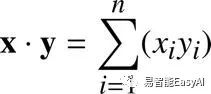
这就是代数定义的点积公式。
代码表8
def dot_product(x,y):
result = 0
for i in range(len(x)):
result = result + x[i]*y[i]
return result
这个公式非常有用因为我们不用去知道角就可以计算点积。我们可以写一个方法去计算这个值(代码表8)且可以得到与几何定义相同的结果(代码表9)。
代码表9
x = [3,5]
y = [8,2]
print(dot_product(x,y)) # 34
当然,我们也可以直接计算点积用numpy(代码表10)。
代码表10
import numpy as np
x = np.array([3,5])
y = np.array([8,2])
print(np.dot(x,y)) # 34
我们花了大量的时间来理解点积及如何计算它。这是因为点积是一个你学习向量机需要掌握的基本概念。接下来将要看到另一个重要的概念,线性分割。
理解线性分割(linear separability)
在这一部分,我们用一个简单的例子来介绍线性分割。
线性可分数据
想像一下,你是一个葡萄酒生产商。你出售两种不同批次的葡萄酒:
高端葡萄酒售价为$145一瓶。
普通葡萄酒售价为$8一瓶。
最近,你开始接到买了高端酒的用户的投诉,他们说瓶里装的是廉价酒,以次充好。这严重影响了公司的声誉,导致客户不再购买你的葡萄酒了。
用酒精度来区分葡萄酒
你决定寻找一种方法来辨别这两种葡萄酒。你知道它们的酒精含量不一样,所以你打开一些瓶子,测量酒精深度,并标注下来。
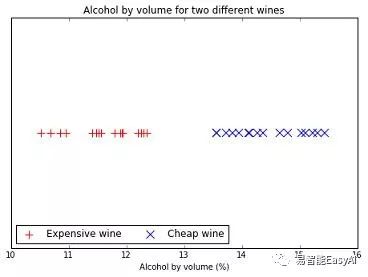
图6:一个线性可分数据的例子
在图6中,你可以清楚的看到昂贵的葡萄酒的酒精度要比便宜的小。事实上,你可以找到一点将这两种酒分开。这样的数据我们说他线性可分。现在,你决定在高端葡萄酒装瓶之前自动测量酒精度。如果超过13%,这个产品线就停下来然后你的员工必须去做检查。这个改进戏剧性的降低了投诉,然后你的生意又红火起来。
这个例子太简单了——真实情况下,数据不会这么简单。事实上,科学家真实测量葡萄酒的酒精度,得到的结果如图7所示。这是一个非线性可分数据的例子,它能帮你更好的理解线性可分。在很多情况下,我们先开始线性可分的情形(因为它简单)然后再观察非线性可分的情形。
同样,在很多问题上,我们不是只工作在一维,像图不6那样。真实生活中的问题会有更多的挑战不像我们刚举的像玩具一样的例子。有些会有成千的维数,让事情变得非常抽象。然而,抽象不见得更复杂。本书大部分的例子还是基于两维的。它们简单而且容易直观的表示,而且可以应用基本的几何知识,让你去理解SVMs的基本原理。
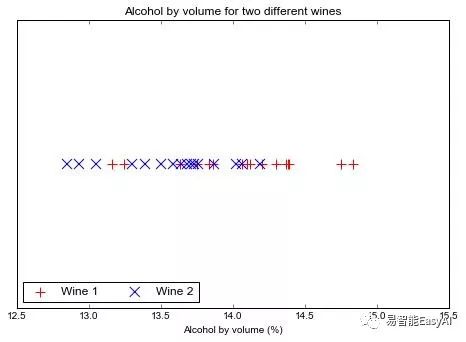
图7:真实的洒精度的点集
在图6的例子中,仅有一维:一个数据点由一个数来表示。当有多维时,我们用向量表示每一个数据点。每当我们增加一维,分割这些数据的对像也跟着改变。确实,我们可以用一个点来分割图6的数据,同时我们需要用一条直线(点集)来分割两维的数据,而三维则需要一个平面(也是点集)。
总结一下,数据线性可分当:
一维时,你可以找到一个点分割数据(图6)。
二维时,你可以找到一条直张分割数据(图8)。
三维时,你可以找到一个平面分割数据(图9)。
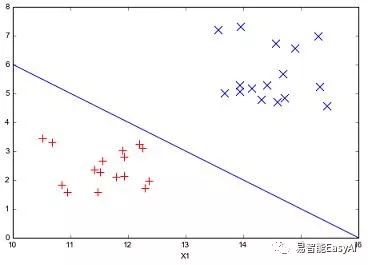
图8:直线分割数据
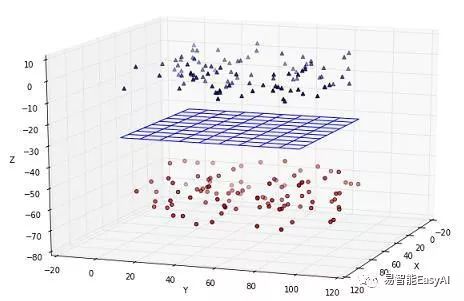
图9: 平面分割数据
同理,当数据不是线性可分时,我们不能找到分割它们的点,线或平面。
图10和图11 展示二维和三维非线性可分的例子。
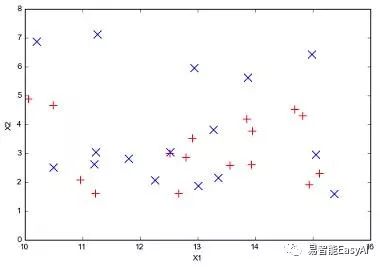
图10:2维非线性分割数据
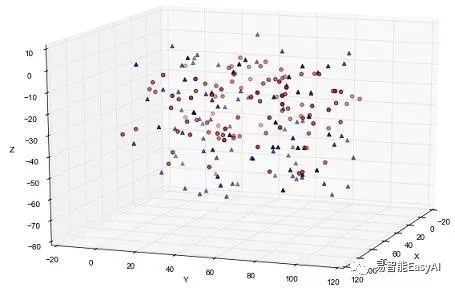
图11:3维非线性分割数据
超平面
用什么来分割超过3维的数据呢?我们称之为超平面。
什么是超平面?
在几何上,一个超平面就是比它所在空间少一维的子空间。
这个定义,虽然不错,但是非常不直观。在使用它之前,我们先学习直线平试着理解什么是超平面。
我们回忆从学校里学到的数学知识,你肯定知道一条真线可以用一个方程式
![]() 来表示,其中常量a表示斜率,b是直线与y轴的截距。有无数的值x符合这个方程,我们称符合方程点集为一条直线。
来表示,其中常量a表示斜率,b是直线与y轴的截距。有无数的值x符合这个方程,我们称符合方程点集为一条直线。
使人迷惑的是在微积分课程里你学过函数
![]() ,你将学到一个函数和一个变量。
,你将学到一个函数和一个变量。
然而,重要的是注意到直线方程式y=ax+b有两个变量,分别为y和x,我们可以按照我们的想法给它们命名。
比如,我们可以把y改名为x2和x改名为x1,这样方程式就变为:![]() 。
。
等价于![]() 。
。
如果我们定义二维向量![]() 和
和![]() ,我们得到这个方程式的另一种记法(
,我们得到这个方程式的另一种记法(![]() 表示w和x的点积)。
表示w和x的点积)。
![]()
用向量来表示的这个方程式看起来很漂亮。虽然我们是用二维向量推导出来的,但是它适用于任意维向量。事实上,它就是一个超平面。
从这个方程式中,我们可以发现超平面的另外性质:它是满足的点集。如果我们抓住这个本质超平台可以定义为:一个超平面就是一个点集。
我们能从一个直线方程式推导出一个超平面方程式,那是因为一条真线就是一个超平面。再回忆一下超平面的定义,你会注意到,确实,一条直线在一个三维空间中的一个平面上。类似的,点和平面都是超平面。
理解超平面方程式
我们从直线方程式推导出超平面方程式。反推也很有意思,这样我们更能够清楚它们之间的关系。
给出向量
![]()
,![]() 和b,我们可以用下面的方程式定义超平面:
和b,我们可以用下面的方程式定义超平面:
这个式子等价于:
![]()
![]()
我们将y提出得:
![]()
如果我们定义a和c:
![]()
![]()
我们可以看出当![]() 时,直线方程式中的偏量c等于超平面方程式中的偏量b。所以你就不要奇怪超平面方程式中的b并不是直线与纵坐标的截距(我们下面的例子将看到)。此外,如果
时,直线方程式中的偏量c等于超平面方程式中的偏量b。所以你就不要奇怪超平面方程式中的b并不是直线与纵坐标的截距(我们下面的例子将看到)。此外,如果![]() 和
和![]() 同号,则斜率a必为负值。
同号,则斜率a必为负值。
用超平面分割数据
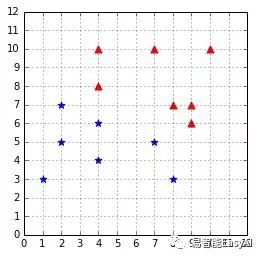
图12:一个线性可分的数据集
图12给出了线性可分的数据,我们可以用一个超平面去二分它们。
例如,用向量w=(0.4,1.0)和b=-9得到超平面如图13。
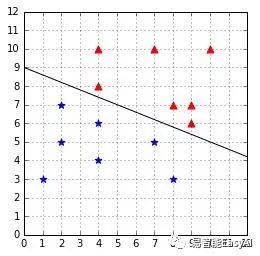
图 13:超平面分割数据
我们联想到每一个向量![]() 对应一个标量
对应一个标量![]() ,我们可以只用+1和-1(如图1用三角和星来表示)。
,我们可以只用+1和-1(如图1用三角和星来表示)。
我们定义一个假设(hypothesis)函数h:
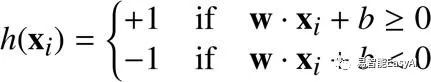
等价于:
![]()
它是用来根据x相对超平面的位置来预测标量y的值。在超平面的一边每一个数据点都被分配一个标量,剩下的另一边的数据点分配另一个标量。
例如,取x=(8,7),x在超平面的上方。当我们代入方程式计算,可得![]() ,结果是一个正数,所以h(x)=+1。
,结果是一个正数,所以h(x)=+1。
同理,取x=(1,3),x在超平面的下方。H将返回-1因为![]() 。
。
因为它是用超平面方程式而产生一组线性可分的值,所以这个函数被称为线性分类器。
一个更好的方法,我们移去常量b让这个h公式更简单。首先,我们加入一元![]() 到向量
到向量![]() 。我们得到向量
。我们得到向量![]() (读作"
(读作"![]() hat"因为我们给它加了一个帽子)。同样,我们加一元
hat"因为我们给它加了一个帽子)。同样,我们加一元![]() 到向量
到向量![]() ,变为
,变为![]() 。
。
![]() 注意:在本书下面部分,我将称呼加了人为坐标的向量为增强向量。
注意:在本书下面部分,我将称呼加了人为坐标的向量为增强向量。
当我们用增强向量时,假设函数就变为:
![]()
如果我们有一个像图13中那样的分割数据集的超平面,使用假设函数h,我们可以完美的预测每一点的值。
但这个主要问题是:我们怎样找到这个超平面呢?
我们怎样找到这个超平面呢(能否分割数据)?
我们再来看看用增强形式的超平面方程式![]() 。现解只有w的变化才能影响超平面的形状变化很重要。我们已知二维分类的例子里超平面是一条真线。当我们建立一个增强的三维向量,得到
。现解只有w的变化才能影响超平面的形状变化很重要。我们已知二维分类的例子里超平面是一条真线。当我们建立一个增强的三维向量,得到![]() 和
和![]() 。你可以看到向量w包含a和b,它是一条直线的两个主要组成部分。当改变w的值就能得到不同的超平面(直线),如图14所示。
。你可以看到向量w包含a和b,它是一条直线的两个主要组成部分。当改变w的值就能得到不同的超平面(直线),如图14所示。
图14:w的不同取值得到不同的超平面
小结
介绍了向量和线性分割之后,我们知道了什么是超平面和为什么我们可用它来分类数据。我们看到学习算法的目标是通过学习一个分类器去寻找一个超平面来分割数据。最后,我们发现寻找一个超平面等价于寻找一个向量w。
我们将要知道一个学习算法用来寻找可分割数据的超平面。在了解SVMs之前,我们先介绍一个最简单的模型:感知器。
以上是关于支持向量机(第一章)的主要内容,如果未能解决你的问题,请参考以下文章