支持向量机(第二章)
Posted 易智能EasyAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机(第二章)相关的知识,希望对你有一定的参考价值。
第二章 感知器
介绍
感知器是Frank Rosenblatt 1957年提出的一个算法,比最早的SVM还早几年。因为它是简单神经网络(多层感知器)的基石而广为人知。感知器的目标是找到一个可分线性分割数据集的超平面。一旦找到这个超平面,就可以用它来执行二分分类。
给出增强向量![]() 和
和![]() ,感知器用我们前一章提到的相同的假设函数去分类数据点
,感知器用我们前一章提到的相同的假设函数去分类数据点![]() 。
。
![]()
感知器学习算法
给定一个包含m个n-维训练实例![]() 的训练数据集
的训练数据集![]() ,感知器学习算法(PLA)试图找到一个假设函数h正确预测标量
,感知器学习算法(PLA)试图找到一个假设函数h正确预测标量![]() 相对于每一个
相对于每一个![]() 的值。
的值。
这个假设函数就是感知器![]() ,而且我们可以看到
,而且我们可以看到![]() 就是超平面方程式。我们可以看到假设函数的集合
就是超平面方程式。我们可以看到假设函数的集合![]() 是一个n-1维的超平面集合(n-1是因为超平面比其他在空间要少一维)。
是一个n-1维的超平面集合(n-1是因为超平面比其他在空间要少一维)。
重要的一条是要理解w是唯一的未知参数。这个算法的目标就是找到w的值;你找到一个w,你就得到一个超平面。这样就有无限多个超平面(你可以给w赋任何值),所以也就有了无限多个假设函数。
这些表述可以给一个更正式的定义:
给出一个训练集:![]() ,和一个假设函数的集合
,和一个假设函数的集合![]() 。找到
。找到![]() 对于
对于![]() 的每一个取值都有
的每一个取值都有![]() 。
。
这个描述等价于:
给出一个训练集:![]() 和一个假设函数的集合。找到
和一个假设函数的集合。找到![]() 对于的每一个取值都
对于的每一个取值都![]() 。
。
PLA是一个非常简单的算法,可以简要描述如下:
1.随机定义一个超平面(就是定义一个向量w)然后用它来分类数据。
2.找出一个错误分类的例子然后通过改变w的值重新选择一个超平面。
3.用新的超平面来分类数据。
4.得复步聚2和3直到没有错误分类的例子出现。
当这个过程结束后,你得到了一个用来分隔数据的超平面。这个算法见代码表11。
代码表11
import numpy as np
def perceptron_learning_algorithm(X, y):
w = np.random.rand(3) # can also be initialized at zero.
misclassified_examples = predict(hypothesis, X, y, w)
while misclassified_examples.any():
x, expected_y = pick_one_from(misclassified_examples, X, y)
w = w + x * expected_y # update rule
misclassified_examples = predict(hypothesis, X, y, w)
return w
让我们仔细分析这段代码。
perceptron_learning_algorithm 方法用到了几个方法(代码表12)。hypothesis方法就是用python代码写的![]() ;就是我们看到写在最前面的,这个方法返回根据
;就是我们看到写在最前面的,这个方法返回根据![]() 的值以w定义的分类超平面而预测的标量
的值以w定义的分类超平面而预测的标量![]() 的值。predict方法应用hypothesis方法来检测每一个训练例子返回错误的分类例子。
的值。predict方法应用hypothesis方法来检测每一个训练例子返回错误的分类例子。
代码表12
def hypothesis(x, w):
return np.sign(np.dot(w, x))
# Make predictions on all data points
# and return the ones that are misclassified.
def predict(hypothesis_function, X, y, w):
predictions = np.apply_along_axis(hypothesis_function, 1, X, w)
misclassified = X[y != predictions]
return misclassified
当我们得到predict返回的预测值集,我们知道这些都是分类错误的例子,我们用pick_one_from方法从中随机选择一个(代码表13)。
代码表13
# Pick one misclassified example randomly
# and return it with its expected label.
def pick_one_from(misclassified_examples, X, y):
np.random.shuffle(misclassified_examples)
x = misclassified_examples[0]
index = np.where(np.all(X == x, axis=1))
return x, y[index]
我们到了这个算法的核心:修改规则。同在,只要记住去调整w的值就可以了。下面详细解释如何实现。我们又用到predict方法,但这次,我们传给它的是调整后的w。它能让我们看到我们将所有的数据点正确分类,或者我们需要一直重复这个过程。
代码表14示例我们怎样根据perceptron_learning_algorithm方法来处理一组特别简单的测试数据。注意我们需要将w和x这两个向量变成相同的维数。所以我们在调用方法之前需要将每一个X向量变成一个加强向量。
代码表14
# See Appendix A for more information about the dataset
from succinctly.datasets import get_dataset, linearly_separable as ls
np.random.seed(88)
X, y = get_dataset(ls.get_training_examples)
# transform X into an array of augmented vectors.
X_augmented = np.c_[np.ones(X.shape[0]), X]
w = perceptron_learning_algorithm(X_augmented, y)
print(w) # [-44.35244895 1.50714969 5.52834138]
理解修改规则
为什么要用这样一个特别的修改规则?当我们随机选择一个分类错误的例子后,现在我们要让感知器正确的分类这个例子,为了做到这个,我们决定去调整w。这儿有一个非常简单的主意,从w和x的点积的正负值我们知道错误原因,去改变它们之间的夹角,就可以得到正确的结果。
如果预测结果值是1,w和x的夹角小于![]() ,我们就加大它。
,我们就加大它。
如果预测结果值是-1,w和x的夹角大于,我们就缩小它。
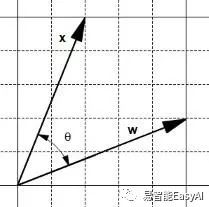
图15:两个向量
让我们看看,两个向量,w和x,之间有一个夹角![]() (图15)。一方面,相加运算产生一个新的向量w+x 且在向量x与w+x之间有一个夹角
(图15)。一方面,相加运算产生一个新的向量w+x 且在向量x与w+x之间有一个夹角![]() 小于(图16)。
小于(图16)。
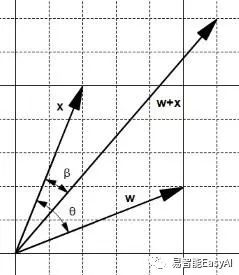
图16:相加运算产生一个小的夹角
另一方面,相减运算产生一个新的向量w-x且在向量x和w-x之间有一个夹角大于(图17)。
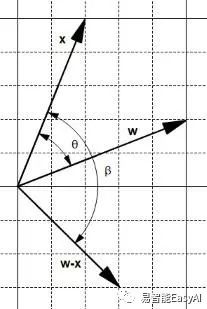
图17: 相减运算产生一个大夹角
我们可以用这两个发现来调整角度:
如果预测结果值是1,w和x的夹角下于,我们就加大它。所以我们设w=w-x。
如果预测结果值是-1,w和x的夹角大于,我们就缩小它。所以我们设w=w+x。
我们调整角度公对出现错误例子,当我们得到一个预测值,这个值正好如正确值相反,所以我们可以重写上面的句子:
如果预测结果值是-1,w和x的夹角下于,我们就加大它。所以我们设w=w-x。
如果预测结果值是+1,w和x的夹角大于,我们就缩小它。所以我们设w=w+x。
我们把它写成Python代码如代码表15,而且我们看到它完全与代码表16等价,这就是我们的修改规则。
代码表15
def update_rule(expected_y, w, x):
if expected_y == 1:
w = w + x
else:
w = w - x
return w
代码表16
def update_rule(expected_y, w, x):
w = w + x * expected_y
return w
我们可以验证这个修改规则能不能正常工作,可以测试一下他能不能将假设函数调整成能返回正确的值。
代码表17
import numpy as np
def hypothesis(x, w):
return np.sign(np.dot(w, x))
x = np.array([1, 2, 7])
expected_y = -1
w = np.array([4, 5, 3])
print(hypothesis(w, x)) # The predicted y is 1.
w = update_rule(expected_y, w, x) # we apply the update rule.
print(hypothesis(w, x)) # The predicted y is -1.
注意到在这个例子中修改方法不用首先改变假设函数的值。但是有时又是必要的如代码表18。这不是一个问题,当我们循环遍历所有的错误分类的例子时,我们需要一直使用修改方法直到没有错误分类为止。当我们需要使用修改规则时,我们就改变夹角让它变得正确(加大或缩小)。
代码表18
import numpy as np
x = np.array([1,3])
expected_y = -1
w = np.array([5, 3])
print(hypothesis(w, x)) # The predicted y is 1.
w = update_rule(expected_y, w, x) # we apply the update rule.
print(hypothesis(w, x)) # The predicted y is 1.
w = update_rule(expected_y, w, x) # we apply the update rule once again.
print(hypothesis(w, x)) # The predicted y is -1.
还要注意到有时我们碰到特殊的x,当用修改规则调整w时会使以前正确的分类变成错误的。所以,假设函数会在调整之后变得更糟。图18的图表显示,需要分类的数据和需要迭代的次数之间的关系。一个解决办法是记住w被修改的次数,仅在发现修改w之后让错误分类的例子减少时才使用。这样修改之后的PLA就是广为人知的口袋算法(因为我们把w放在口袋里)。
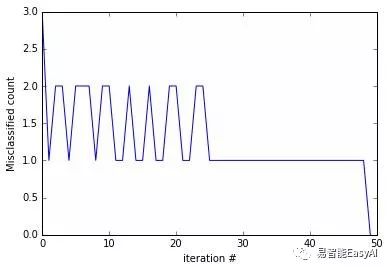
图18:PLA修改规则波形图
算法的收敛性
我们说我们一直调用修改规则直到没有错误的分类点为止。但是我们能确定能达到目标而不出意外吗?幸运的是,数学家已经注意到这个问题。我们可以确信,感知器收敛理论能保证两个集合P和N(各自代表正数(positive)和负数(negative)的例子)能线性分割,向量w仅仅修改有限次。这个理论首先由Novikoff 在1963年提出的(Rojas,1996)。
理解PLA的局限
有一点我们知道,PLA算法开始时所用到的权值和分类错误用例是随机选择的,我们每一次调用这个算法都可能得到不同的超平面。图19显示我们几次用PLA算法分类相同的数据集的结果。你可以看到,PLA算法找到了四个不同的超平面。
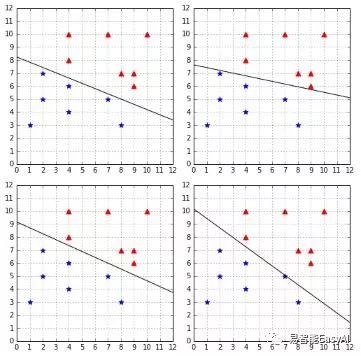
图19:PLA每次都找到不同的超平面。
刚开始,我们可能不认为这是个问题。毕意这四个平面都能分类数据,所以它们都同样好,对吗?然后,我们用机器学习算法比如PLA,我们的目标不仅仅是找到一个方法完美的分类现有数据,而是要找到一个方法去正确分类将来要接收到的数据。
让我们介绍一些术语来清晰的描述这件事。训练一个模型,我们选择现有的数据例子称为训练集。我们训练这个模型,让它成为一个假设函数(我们的例子是超平面)。我们可以测试这个假设函数的效果用训练集:我们称为实验误差(或训练误差)。一旦我们对假设函数满意,我们决定用它来检验不可见数据(测试数据)来代替训练数据。我们测量这个假设函数在测试数据中的效果,我们称之为非实验数据误差(也称为一般误差)。
我们的目标是要取得最小的非实验数据误差。
在我们用的PLA用例中,假设函数如图19所示都完美的分类数据:他们的实验误差为0。但是我们真正关心的是非实验误差。我们用测试数据如图20所示来检验出它们的非实验误差。
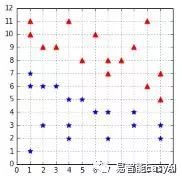
图20:测试数据集
这时你们可以看到图21,右边的两个假设函数,尽管完美的分类了训练数据,但是在测试数据面前出现了错误。
现在我们可以很好的理解它为什么是有问题的。我们用感知器线性分割数据,我们可以保证找到一个0实验误差的假设函数,但我们不能保证它能推广到不可见数据(如果一个算法泛化很好,它的非实验误差应逼近实验误差)。如何让我们的假设方法泛化很好呢?我们将看到下一章,这是SVMs的目标之一。
图21:不是所有的假设函数都完美的0非实验误差
小结
在这一章,我们学习了什么是感知器。我们看到感知器学习算法的工作细节和修改方法的背后机制。之后学习了PLA可以保证收敛,我们看到不是所有的假设函数都是相同的,其实有一些在泛化方面比另一些好。最后,我们发现感知器没法选出最少非实验误差的假设函数代替的是随机选出一个最少实验误差的假设函数。
以上是关于支持向量机(第二章)的主要内容,如果未能解决你的问题,请参考以下文章