西瓜书学习—支持向量机之最优化
Posted 探索中的机械人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了西瓜书学习—支持向量机之最优化相关的知识,希望对你有一定的参考价值。
最优化理论
什么是最优化理伦呢?最优化理论是针对最优化问题而言的,通常情况下,我们的最优化问题涉及到以下三种情况:
1)无约束优化问题
形如:min f(x);
对于此类问题,我们采用fermat定理,即对函数求导得到导数为0的点,该点也就是极值。将候选点带入,得到最优点。
2)有等式约束的优化问题
形如:
对于此类问题,根据高数知识,我们采用拉格朗日乘子法。把等式约束h_i(x)用一个系数与f(x)写为一个式子。再对该式子的参数求偏导数,然后令偏导数为0,可以求得候选值集合,带入求得最优值。但是,为什么呢?当时没有讲,其实这类问题也是第三类问题的特殊情况。
3)有不等式约束的优化问题
形如:
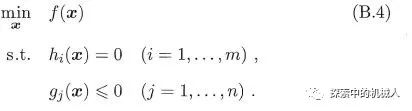
此类问题需要将不等式约束和等式约束都写到一个拉格朗日式子里面,如下:
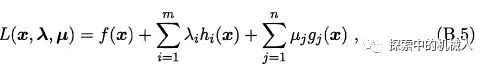
好了,我们现在得到了优化问题中的第一个问题初始问题(primal problem)。
KKT条件是说最优值必须满足以下条件:
g(x)≤0;
μ≥0;
μ*g(x)=0;
由上篇可知,根据第三个条件我们得到了SVM只关注支持向量的特征。
好了,问题来了,为什么拉格朗日乘子法和KKT条件可以得到最优值呢?KKT条件又是怎么得到的呢?
(1)我们先讲拉格朗日乘子法对偶问题的由来:
我们有了上面的拉格朗日乘子式(初始问题)后,根据式子让他针对λ和μ进行最大化,令:
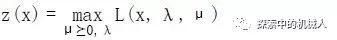
这里μ ≥0即向量μ非负,λ的意思是其大小任取。
函数z(x)对于满足约束条件的x来说,就等于f(x)。因为,根据约束条件,h(x)=0,则第二项为0。然后,μ≥0,g(x)小于零,则z(x)要取最大值的话,μ*g(x)应为0。因此,对于符合约束条件的x来说,f(x)=z(x)。
同样的,函数z(x)对于不满足约束条件的x来说,可以得到z(x)=∞。这个是很容易理解的,既然是取最大值,那么我们令h(x)>0,g(x)>0很容易就取到无穷大了。接下来,我们可以发现,我们可以将有约束的优化问题(对x)转化成无约束的优化问题(对λ和μ)。如下:
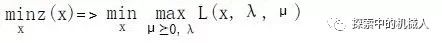
好了,我们现在对将符号min和max互换位置就得到,初始问题的变种对偶问题,其自变量是对偶变量(dual variable)λ和μ,如下:
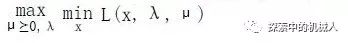
好,至此我们就解释了lagrange乘子式对偶问题的来源,我们将内函数叫做lagrange dual function。接下来,我们讲述什么是弱对偶和强对偶条件。
(2)通过对偶问题来得到初始问题的最优值
我们现在得到了上面的lagrange对偶函数的来源,我们将其定义为Τ(λ,μ)。
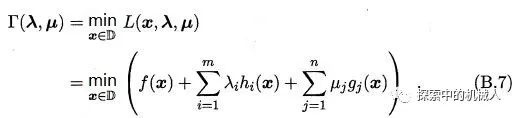
若X0为初始问题(B.4)可行域中的点,我们总有:
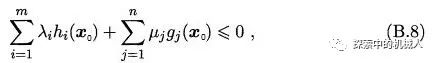
这是很容易理解的,因为h(x)是0,且μ≥0,g(x)≤0,则必有上式成立。
进而有:
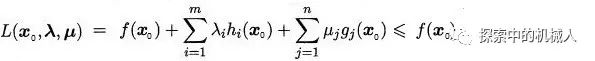
于是有:
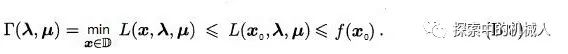
这样一来就引出了Τ(λ,μ)的下界性质。即,Τ(λ,μ)是初始问题的一个下界。这也就明白了我们为什么要研究Τ(λ,μ)的上界,也就是研究对偶问题的上界。假设初始问题的最优值是p*,就有如下:

总结一下:
其实直观来看,我们可以直接根据式子(B.4)中的目标函数来理解,我们期望得到的是目标函数的最小值,但其最小值我们希望可以通过对关于λ和μ两个变量的对偶问题的上界研究(优化)来得到其初始问题的下界。也就是说对偶问题的上界(d*)越接近初始问题的下界(p*)越好,这也就引出了如下:
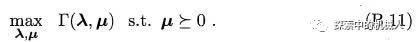
同时也就引出了对偶条件。假设对偶问题的上界是d*。有
当d*≤p*时,即是弱对偶性。
当d*=p*时,即是强对偶性,此时我们可以通过对偶问题的上界得到初始问题的下界。一般的优化问题,强对偶性一般不成立。但是如果初始问题是凸优化问题(后面再讲)且满足slater条件的话,则强对偶性成立。
d*-p*叫做duality gap。
(3)KKT条件
引:
上面我们讲到凸优化问题,比如式(B.4):
f(x)和g(x)都是凸(二次)函数;
hi(x)是仿射函数(形如wx+b);
形如这种的问题叫做凸优化问题。如果其可行域中至少有一点使不等式约束严格成立(形如hi(x)=0,g(x)<0),这称之为Slater条件;式(B.4)恰好符合这两个条件,于是该问题符合强对偶性。
好了,我们正式开始。假设x*,(λ*,μ*)分别是初始问题和对偶问题的两个极值点,同时有d*=p*。于是有:

然后我们根据式(B.9)得到如下:
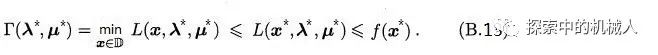
我们可以看到上下两式的结果一致,于是式(B.13)中的不等号都可以换成等号。于是,根据第一个不等号(现在是等号),x*是L(x,λ*,μ*)的一个极值点。于是得到,L(x,λ*,μ*)在此处的梯度为0,于是有下:
又根据第二个不等式(现在是等式),如下:
有:μ*g(x*)=0。因为等式两边消去了f(x*),然后h(x*)=0;这个条件叫做complementary slackness。显然,如果μ*>0,则g(x*)为0。同理,如果g(x*)>0,则μ*为0。这就是SVM的只关注支持向量的特性由来。
然后,我们只要把前面的显而易见约束与这条约束组合到一起,就得到了传说中由不等式约束引出的KKT条件。
4)总结
到这里我们就知道了KKT条件的由来,同时本篇也就到此结束了。说实话,本人智商有限,对这部分内容前后看了3到4天,总数不下10遍,就是为了搞懂它!欣慰的是,最后还是搞懂了。唯一的感悟就是人与人之间的差距真的不是一般的大,大神pluskid在大三时就搞懂了这部分内容,而且理解深刻,讲解深入浅出,按照时间推算,现在他应该快从MIT博士毕业了吧。但这有什么呢?喜欢就要坚持下去,送给关注我的朋友,也送给自己!
后续,我还会再讲解二次规划理论和SMO算法。
以上是关于西瓜书学习—支持向量机之最优化的主要内容,如果未能解决你的问题,请参考以下文章