支持向量机大全(SVCSVRSVDDDTSVMTSVMSVCSTM)
Posted 互联网大数据处理技术与应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机大全(SVCSVRSVDDDTSVMTSVMSVCSTM)相关的知识,希望对你有一定的参考价值。
以往推送的原创文章(部分):
...
支持向量机SVM应用非常广泛,但SVC、SVR、SVDD、DTSVM、TSVM、SVC(没错,是另一个SVC)、STM,这些与SVM相关的概念和模型经常把人弄糊涂。总的看,SVM包含了SVC和SVR两种类型,分别用于做分类和回归,取决于输入数据的不同(输入标签为连续值则做回归,输入标签为分类值则做分类)。
1、SVC (C是分类)
SVC是SVM的一种类型,是用来的做分类的,是我们平常用得最多的,以至于很多人就把它称为SVM。
SVC实现了不平衡训练数据集上的处理,通过设置类别权重参数给每一个类别设置不同的权重,可以减小非平衡的影响。
2. SVR (R是回归)
SVC分类器可以扩展用来做回归,称之为支持向量回归。支持向量回归算法主要是通过升维后,在高维空间中构造线性决策函数来实现线性回归。
从下面可以看出在特征空间中,该决策函数的优化目标。从回归例子可以看出,SVR能够避免一些噪声点的影响。
3.支持向量域SVDD(Support Vector Domain Description)
SVDD是一类分类(one class SVM)的实现方法,通过对给定的一类数据进行训练,获得一个最小的超球面,但又要尽可能把更多的数据点包含到超球里面,一些比较边缘的点可能就会被排除在外。之所以称它为一种description,就是因为SVDD生成了数据的轮廓。
判断一个新的数据点是否属于该类时,如果数据点落在超球面内,就是这个类,否则不是。类似于SVC,落在超球体表面的点被称为Support Vector (SV) 支持向量。
4. SVC (C是聚类)
称为支持向量聚类,是在SVDD基础上衍生出来的,是一种聚类算法。本质上是一个SVDD+贴类标的过程。
它的基本思想是:利用高斯核,将数据空间中的点映射到高维空间中。在该空间中寻找一个能包围尽可能多点且半径最小的球,再将这个球映回到原始数据空间,从而得到包含数据点的等值线集。这些等值线就是簇的边界。每一条闭合等值线包围的点属于同一个聚类。
SVC具有显著优势是,能产生任意形状的簇边界,能分析噪声数据点且能分离相互交叠的簇。这是许多聚类算法无法做到的。但SVC消耗更多的时间。
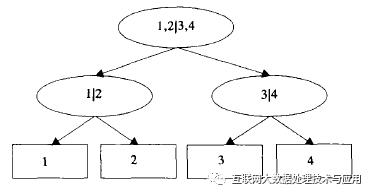
5. DTSVM 决策树SVM分类器 (DT就是决策树)
普通的SVM(准确的说是SVC)只能用于两类分类,DTSVM是SVM用于多类时的一种模型。众多的SVM分类器按照二叉决策树的拓扑结构结合起来, 构成树形结构的多类别分类器, 从而将多类别分类问题转化为两类分类问题。如图,图中椭圆是一个SVM分类器。
6. TSVM 直推式SVM
直推式支持向量机(Transductive Support Vector Machine , TSVM)是标准的支持向量机算法在半监督学习问题上的一种扩展,它采用了直推式学习(Transductive Learning)。TSVM同时使用已标识样本和未标识样本来寻找最优分类边界, 使其包含的分类间隔能最大地分隔原始的已标识样本和未标识样本(经TSVM 学习后其标识将变为已知), 新找到的最优分类边界应该满足对原始的未标识样本的分类具有最小的泛化误差。
7.STM 支持张量机模型
对于SVM所处理的点来说,它们所在的维度空间具有一种无结构的特征,是向量数据。但是在视频、文本分析、社交媒体用户行为中,如果将数据当作张量数据,可能会提高分析性能。因此,基于张量学习(STL)将支持向量机扩展到支持张量机( support tensor machine ,STM) 。
在LibSVM等支持向量机软件系统中,SVM的类型一般有C-SVC、nu-SVC、one-class SVM、e-SVR、nu-SVR。这些都在上面介绍的里面,只不过多了一些可设置的参数。例如,C-SVC的C是惩罚参数,C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
点击阅读原文链接,查看图书详情信息(目录、引言)。
以上是关于支持向量机大全(SVCSVRSVDDDTSVMTSVMSVCSTM)的主要内容,如果未能解决你的问题,请参考以下文章