机器学习:支持向量机SVM
Posted 残留的存在主义
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:支持向量机SVM相关的知识,希望对你有一定的参考价值。
支持向量机SVM(二)

编程语言:Python
机器环境:Windows
参考书籍:《机器学习实战》
参考学习视频:
吴恩达机器学习视频:
https://study.163.com/course/courseMain.htm?courseId=1004570029
注:一些公式推导,可以参照周志华的书籍《机器学习》。
线性分类器
是一类通过将样本特征进行线性组合来作出分类决策的算法,其目标是找到一个能够分割不同类别样本的超平面。这样在预测的时候,我们就可以根据样本位于超平面的哪一边来作出决策。
数学表示
用数学语言来描述,一个线性函数可以简单表示为:
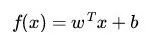
数学上可以理解为一阶导数为常数的函数。而线性分类器则根据线性函数的结果进行分类决策。
核函数
在上节我们说到对于线性可分的可以用最大间隔来寻找分隔超平面来分类,对于非线性可分的就要寻找核函数来将数据映射到高维空间,来解决在原始空间中线性不可分的问题。比如用新的特征来表示高次特征项,核函数会用一个函数来表示出新的特征。
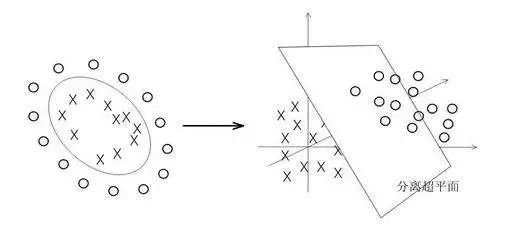
核函数的分类
线性核函数(linear):解决线性分类问题,即不用核函数的SVM,类似逻辑回归的效果.
高斯核函数(rbf):解决非线性分类问题。
以上是最常用的两个核函数,除此之外,还有多项式核函数、字符串核函数、卡方核函数等等。
高斯核函数
高斯核函数的新特征的近似函数:
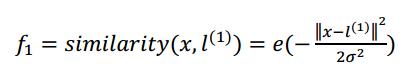
如果一个训练样本与地标L之间的距离近似于0,则新特征f就近似于exp(-0)=1,如果距离很远,则新特征f就近似于exp(-NaN)=0。(推导过程可以参照吴恩达教学视频)
下面是基于高斯核函数(rbf)的SVM的两个参数C和σ的影响(C=1/λ,λ即正则化参数):C较大时,相当于λ较小,可能会导致过拟合,高方差;
C较小时,相当于λ较大,可能会导致欠拟合,高偏差。
σ较大时,可能会导致低方差,高偏差;
σ较小时,可能会导致低偏差,高方差。
惩罚系数C的影响
scikit-learn
scikit-learn是python的机器学习的包,简称sklearn,里面集成了数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。sklearn是基于NumPy, SciPy, matplotlib的。
SVC
sklearn中SVM既可以处理分类问题,也可以处理回归问题,前者是SVC模块,后者是SVR模块。
示例
from sklearn import svm
X = [[0,0],[1,1],[1,0]] #training samples
y = [0,1,1] # training target
clf = svm.SVC() #classifier
# clf = svm.SVC('linear')
clf.fit(X,y) #training the svc model
result = clf.predict([[2,2]]) #predict the target of testing samples
print(clf) #classifier param
print(result) #target of testing samples打印结果:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
[1]第一个打印出分类器,这里使用的是SVM的分类器SVC,没有指定参数,默认使用的是带高斯核函数(rbf)的SVM.也可以在构造方法里指明参数:
C:惩罚系数,默认为1.
kernel:核函数,默认是rbf.
gamma:不同核函数,表示不同含义,对于rbf,表示σ的值。
第二个打印出的是预测结果1。
下期 机器学习(十):决策树(一)
机器学习系列:
家明将与大家一起学习机器学习,借助于网上的教程与书籍指导,家明总结,与大家一起进步,共同应对AI时代。
以上是关于机器学习:支持向量机SVM的主要内容,如果未能解决你的问题,请参考以下文章