使用支持向量机(SVM)在Oracle自治数据仓库云中进行机器学习
Posted 甲骨文云技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用支持向量机(SVM)在Oracle自治数据仓库云中进行机器学习相关的知识,希望对你有一定的参考价值。
背景
Oracle自治数据仓库云服务(以下简称为ADW)为数据科学家提供可一个可自助进行各种数据探索和数据建模的环境-Oracle Machine Learning。数据科学家可以通过前端的Apache Zeppeline Notebooks方便的对ADW中的数据进行浏览、处理、分析、建模和验证等工作。
Oracle ADW内置了用于机器学习的算法包DBMS_DATA_MINING,通过该算法包,数据科学家可以方便的创建诸如分类、聚类、回归、异常检测、特征提取等模型,模型的结果可以方便的部署到业务系统中支持实时的商业决策。
本文以共享单车的数据集为示例,基于单车使用的历史数据,使用ADW Notebooks和DBMS_DATA_MINING中提供的SVM数据模型算法构建回归预测模型,对共享单车的未来使用量进行预测。
数据准备
共享单车示例数据集分为两个数据集-训练数据集(bike_train_data)和预测数据集(bike_predict_data),通过Notebooks我们可以方便的使用熟悉的sql语句,对数据集内的数据进行浏览。
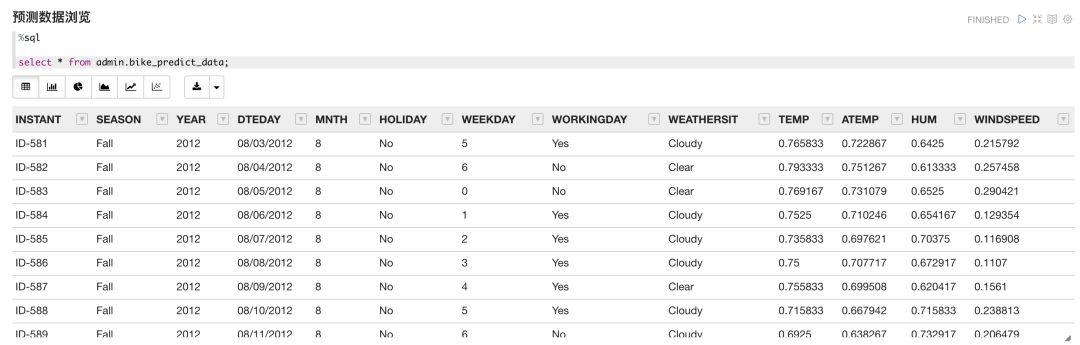
从数据集内容可以看出,训练数据集包含一个时间段内的每日单车使用量(count),以及当日的其他相关信息,比如季节、天气情况、温度、风速等,而预测数据集内容基本相同除了没有单车使用量(此为我们需要进行预测的数值)。
从训练数据集数据可以看出,部分的数据是字符型数据,在进行回归建模前我们需要将该部分数据转化为数值型。以季节(season)和天气(weathersit)为例,我们需要先分析该变量的取值范围,我们可以使用ADW Notebooks提供的数据结果可视化能力进行快速分析。
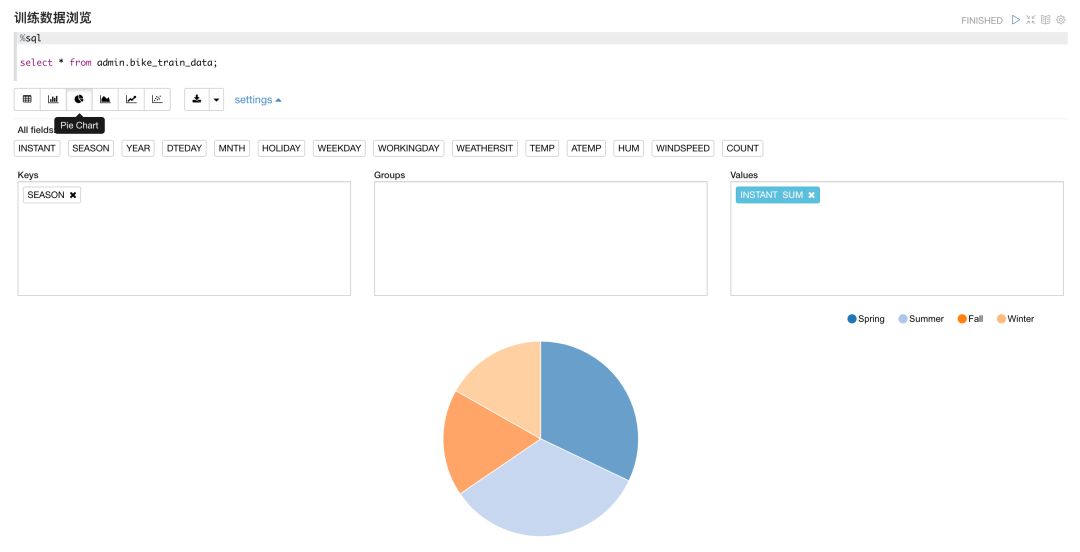
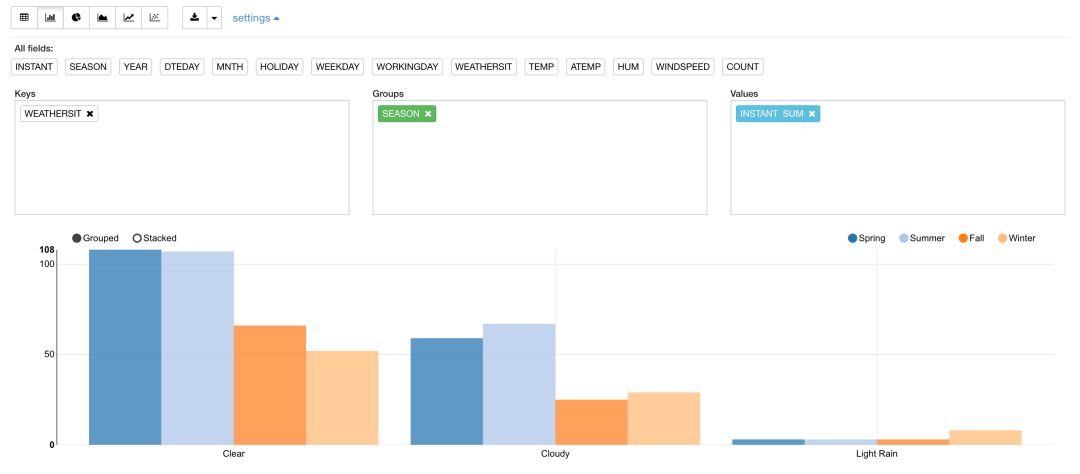
通过对season数据分布的图形分析,以及进一步的season和weathersit数据的图形分析,很轻易的获得了这两个变量的取值范围。下面根据上面获得的信息,通过脚本构建用于进行数据建模的数据库视图。如下脚本所示,所有字符型的变量都转变为可进行建模的数值型变量。

模型构建
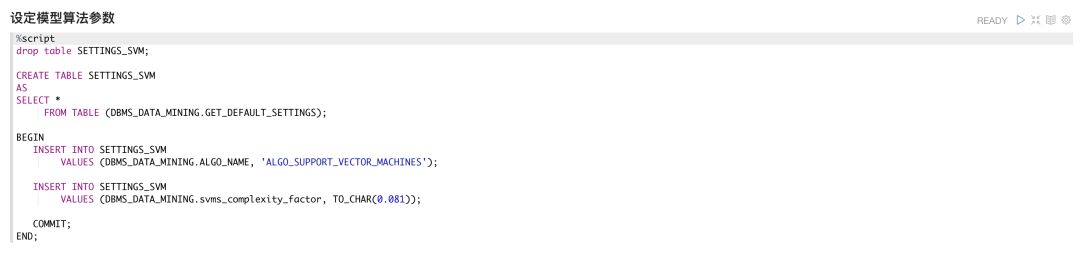
首先,我们要通过参数设置指定模型构建使用SVM算法,以及SVM算法的相关参数。通过创建参数表SETTINGS_SVM,设定算法名称ALGO_NAME和参数svms_complexity_factor,完成了模型构建的准备工作。
下一步,使用DBMS_DATA_MINING提供的CREATE_MODEL进行模型构建。如下所示,CREATE_MODEL需要制定模型名称、模型函数、训练数据集、case_id、targe_column和参数表。

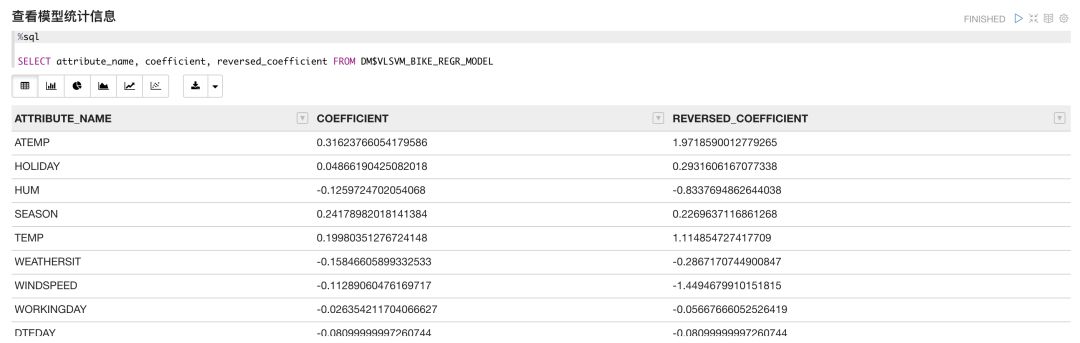
模型构建完成后,我们来查看模型结果的各项输出,其中VLSVM_BIKE_REGR_MODEL可以看到训练数据集中各个参数对预测结果的相关性。

查询该数据表可以看到,所有属性对模型结果的相关性都在-1到1之间,通过可视化分析可以直观的看出各属性的正相关和负相关特性。
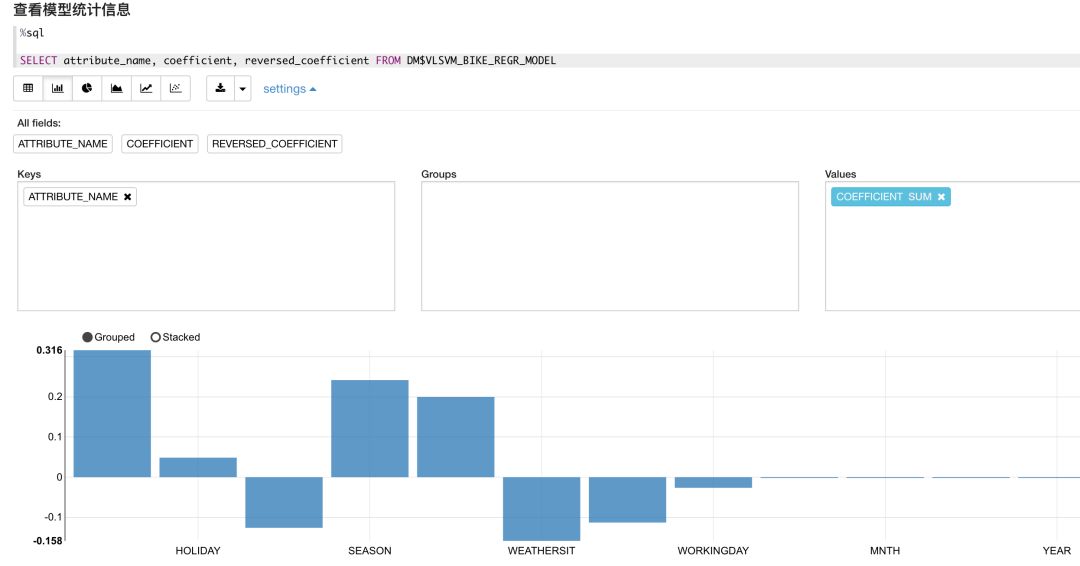
应用模型
通过DBMS_DATA_MINING的APPLY功能,可以快速的将模型应用于预测数据集,和CREATE_MODEL类似的,APPLY需要提供模型名称、预测数据集、case_id和结果数据表。

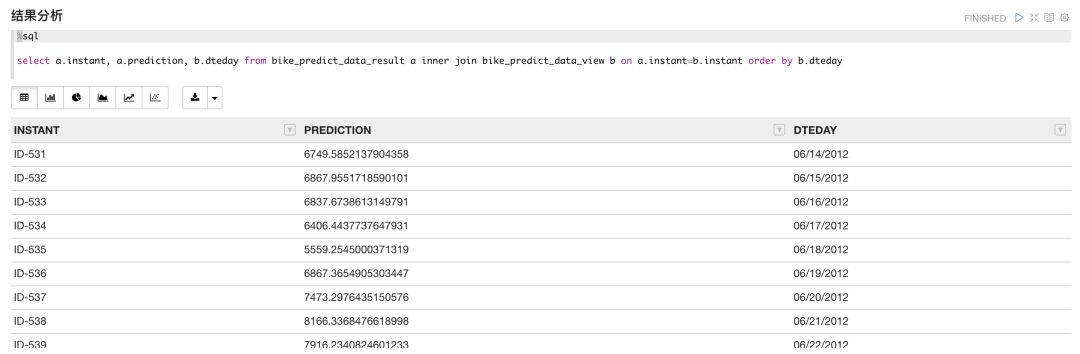
模型应用会自动创建结果数据表bike_predict_data_result,通过join结果数据表和预测数据集,我们对预测结果进行检查,可以看到预测结果中生成了predition这一数据列,也就是我们需要的单车用量的预测值。
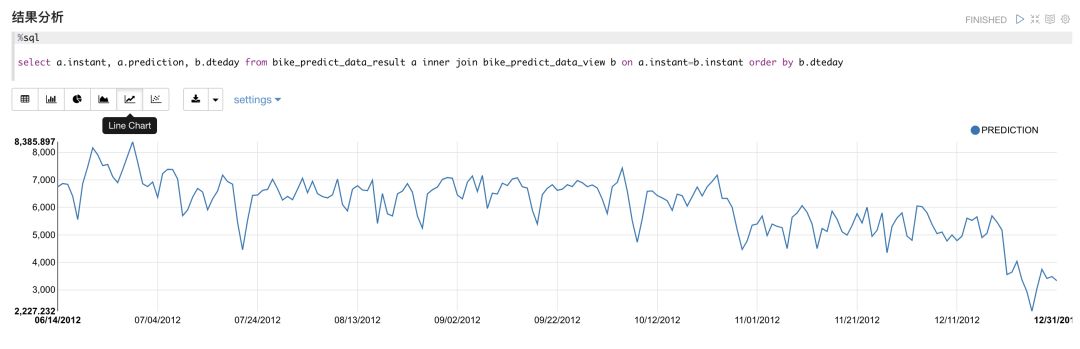
通过可视化方式对结果进行分析,可以看出随着时间的推移,从夏天到冬天,共享单车的使用量呈缓慢下降的趋势。
总结
ADW提供的Machine Learning Notebooks方便数据科学家自助创建分析项目,同时提供了方便多人一起工作的共享能力,可以对分析项目的各个步骤一目了然。同时,ADW内置的各种机器学习算法,简化了构建模型的过程,同时基于ADW底层强大的弹性伸缩的计算能力,可以快速的处理海量数据的模型构建,而基于Oracle数据库的机器学习功能也便于将模型结果快速部署到生产系统中,支持实时决策。
编辑:殷海英
以上是关于使用支持向量机(SVM)在Oracle自治数据仓库云中进行机器学习的主要内容,如果未能解决你的问题,请参考以下文章