初识支持向量机(SVM)
Posted 静候君来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识支持向量机(SVM)相关的知识,希望对你有一定的参考价值。
支持向量机又被称为SVM,它是目前最好的现成的分类算法之一。现成的指分类器不加修改即可直接使用,这也就意味着在数据上应用基本形式的SVM分类器就可以得到低错误的结果,SVM能够对训练集之外的数据点做出很好的分类决策。
一、SVM的进一步认识
假设我们有这样一个数据集:
现在要求你用一根棍子将它们分开,我猜你会这么做。
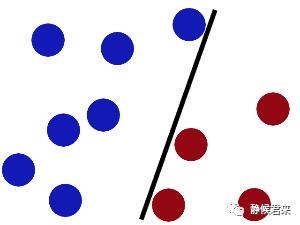
接着,当有更多的数据集加进去之后会出现分类错误问题:
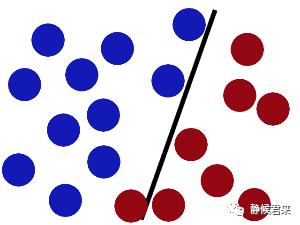
那么你会继续调整黑杆的位置
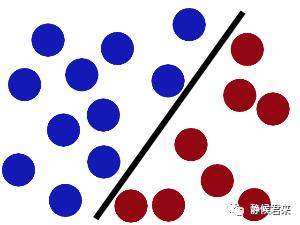
没错,这就是SVM,将杆放到最佳位置,再进一步定义,何为最佳位置?就是让球和杆子的距离保持最大。但是新的问题又出现了,如果出现这种数据集该怎么办?
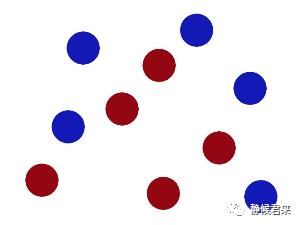
这时候我们需要一根曲线将它们分开,这样:
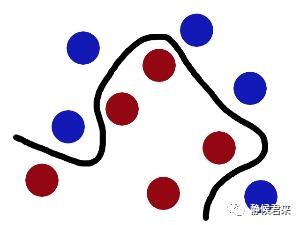
我们将它看成三维的试试看:
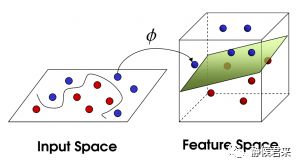
现在对SVM应该有个大概了解了。
我们做个小结:
SVM就是对数据集进行划分,当处理线性问题时,即数据集可以用一条直线划分时,我们试图去寻找这条直线使得划分最优,即数据距离直线最大。当处理非线性问题时,这时候我们需要将数据集进行升维处理,这种升维处理就被称为核函数,划分数据集的平面称为超平面。那么问题就是两个:线性和非线性。
二、线性SVM
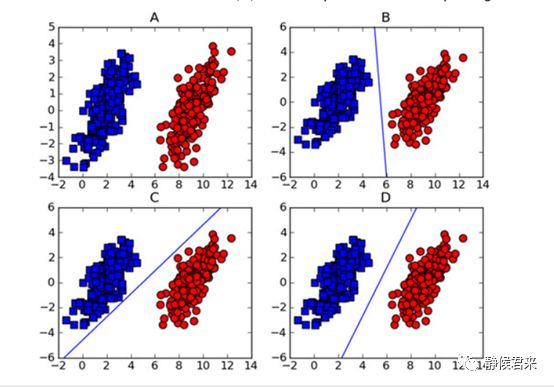
此为线性SVM相信一目了然,其中BCD各有各的划分方式,虽然它们的效果是一样的,然而体现在算法上面的性能是有差距的,我们看:
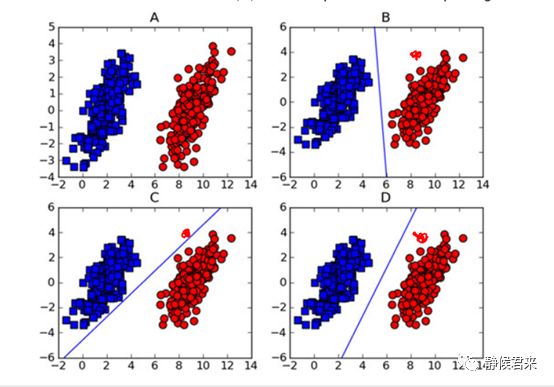
当我在新添加一个红点数据之后,C的决策面出现了错误,同理,当我添加一个蓝点之后,B也会出现错误,如图:
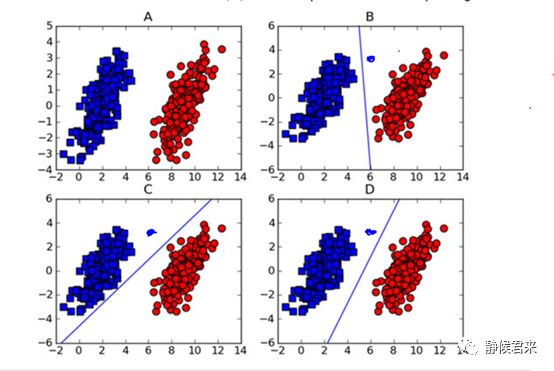
很显然,D在这两者情况下都不会出错,SVM算法也这么认为。它的依据就是分类间隔大小。那么如何找到这个最优决策面呢?我们可以尝试着做两条平行于这个决策面的直线,分别在决策面的两边,同时向两边平移,直到碰到数据点为止,那么最优决策面就在这两条直线之间。但是不同方向的最优决策面的分类间隔也是不同的,具有最大间隔的最优决策面就是SVM寻找的最优解,而这个最优解旁边的两条直线穿过的数据点,被称为“支持向量”。
1、数学建模
数学建模有两个对象:目标函数和优化对象
目标函数为分类间隔,优化对象就是决策面。我们先从数学层面对这两个对象进行描述。
1)决策面
显而易见的是二维空间下“决策面”的方程是:
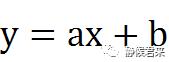
我们令x为x1,y为x2,可以将方程变换为:
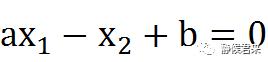
将此方程向量化:
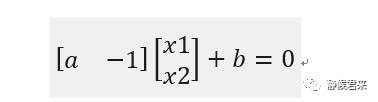
进一步向量化,用w代表参数,x代表变量,代表常量,将方程变换为:
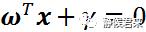
w和x分别是:
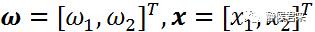
我们不妨将w和直线方程画出来,
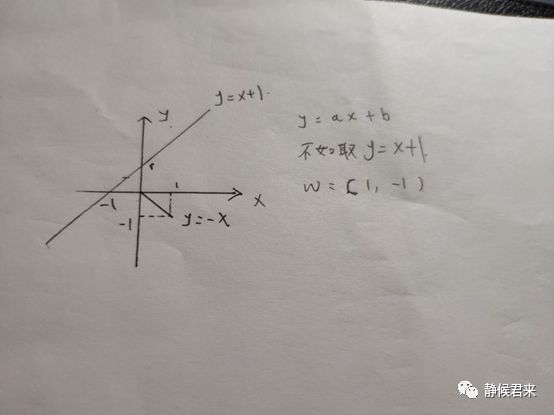
这是特殊情况,可以看出向量和直线是垂直的,放大到一般情况,w=(a,-1),则其斜率为-1/a,直线的斜率为a,很容易推出w向量其实是直线的法向量。这是二维空间的直线方程,将其扩展到n维空间其实也是一样的,只是里面的参数量和变量增加了而已,依旧是此方程:
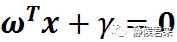
只不过它现在被叫做超平面方程。
1)分类间隔
前面已经提到过,所谓的分类间隔就是数据点和直线的距离,相信大家都知道点到直线距离公式:
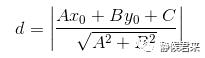
二维的很好解决,那么更高维的呢?我们对公式作如下变形:
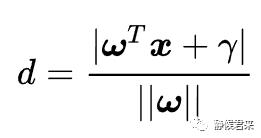
我们来好好理解此方程,先看分子,分子为什么是这个?我们知道数学中有个方法叫做等效替代法,Ax0+By0+c=0是二维平面的“超平面方程”,而w^Tx+r是更高维平面的超平面方程,我们刚刚推导了高维的超平面方程,其只是在二维平面的超平面方程上做了一些变换,其效果是一样的,所以我们可以等效替代,同理,分母依旧如此,与常量r无关。其中||w||表示的是二范数,指空间上两个向量矩阵的直线距离,其公式如下:
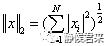
简单的来说就是将平方相加再开方。我们说过在众多超平面中选取分类效果最好的作为超平面,通俗点就是在精英中选取一个精英。我们如何选取?就是通过这个分类间隔,分类间隔越大,分类效果越好。
3)约束条件
为了求解分类间隔,我们有两个问题:
如何判断超平面已经将样本集正确分类?
要求间隔最大值,如何找出支持向量?
这就要涉及高数里面的约束条件,也就是距离的范围受到约束的条件。
我们假设n维平面上的n个数据点,红色点分类标签就是1,蓝色分类标签为-1,那么如果我们的超平面方程能正确分类,就会满足如下条件:
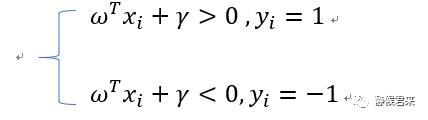
如果不巧,决策面就在最优决策面处,那么就意味着分类标签1的点都>=d,分类标签为-1的点都<=-d,即
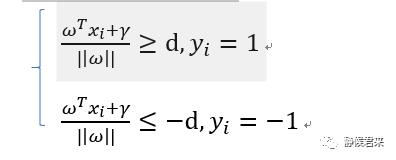
两边同时除以d得:
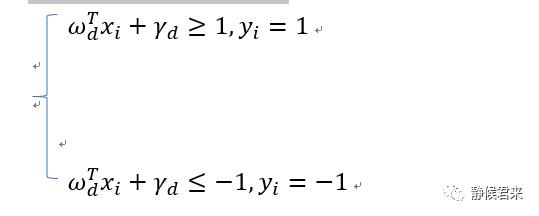
其中,
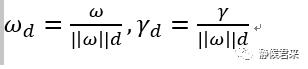
可以看出来,wd和rd是两个矢量,依旧描述的是法向量和截距:
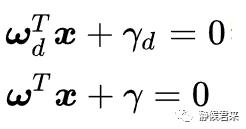
我们重新对wd和rd起名为w和r,那么我们可以这样认为:“存在分类间隔的数据集,一定满足如下条件”:
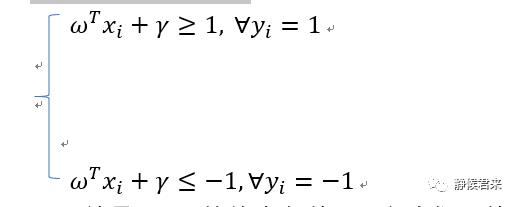
以上就是SVM的约束条件,那么我们为什么要将分类标记成1和-1呢?因为我们要方便以下方程:
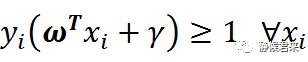
正因为标签为1和-1才方便我们将它转换为一个约束方程,从而方便我们计算。
4)线性SVM优化问题的基本描述
我们的问题是将d最大化,前面我们已经说过,我们用支持向量来求解,那么支持向量有如下特点:
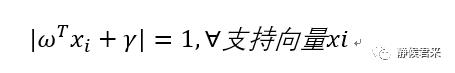
如何解释?我们假设最优决策面为x1+x2+1=0,那么其直线上的点都满足|x1+x2+1|=0,那么它左右两边的直线为:x1+x2=0,x1+x2+2=0,支持向量在其上,根据最优决策面的直线我们知道,x1+x2=-1,那么|x1+x2|=|x1+x2+2|=1,再等效到高维上面依旧满足,所以我们推出:
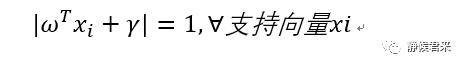
好哒,我们继续化简:
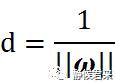
显然,问题转化为了||w||最小的问题,但是为了方便对目标函数求导,我们继续将它等效为:
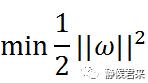
我们将目标函数和约束函数放在一起:
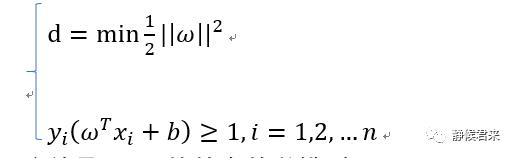
这就是SVM的基本数学模型。
5)求解准备
我们需要根据数学模型求出最优解。然而,目标函数是否具备最优解?或者什么样的函数才具备最优解?如果不事先了解目标函数是否具备最优解,我们解的过程将失去意义。根据我们的数学知识了解到,只有凸凹函数才具备最优解,现在给出凸函数的定义:凸函数是一个定义在某个向量空间的凸子集C(区间)上的实值函数f。需要注意的是::中国大陆数学界某些机构关于函数凹凸性定义和国外的定义是相反的。举个例子:
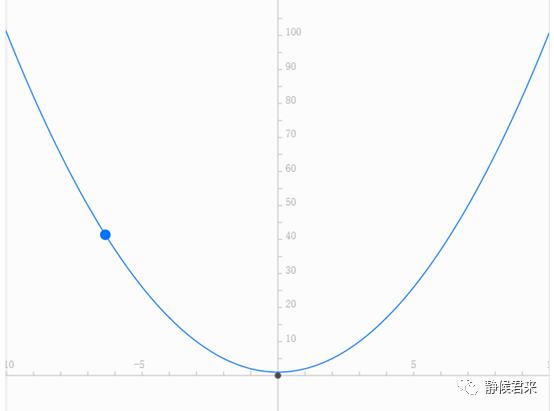
看到这个,相信绝大多数人认为这是凹函数,这在同济教材里也是这么定义的,然而在国际上这被认为是凸函数,这只是观察方式不一样,不必纠结,我们在这里采用国际标准,即开口向上被认为是凸函数,即此图。显然我们的目标函数是个凸函数。通常,我们求解最优问题分成以下几类:
第一类:无约束:
Min f(x)
第二类:有等式约束:
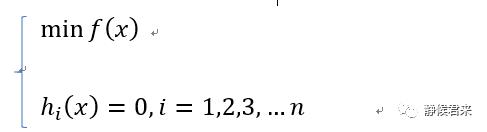
分别对应以下三种处理:
第一类:高中知识,求导,令导数为0,求取极值
第二类:大学知识,利用拉格朗日乘数法求解。
6)拉格朗日乘数法
显而易见这是第二类问题,我们首先使用拉格朗日乘数法整合成一个式子,对的,你的思路没错.,拉格朗日乘数法的意义就在于将有约束条件的目标函数转换为无约束条件的新目标函数且与原来的目标函数等价,接着就是大家高中所熟悉的求导,求极值问题。那么开始转换为拉格朗日函数:
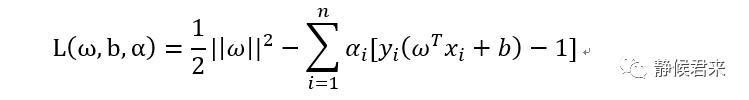
其中ai是拉格朗日乘子,ai>=0
求导如下:
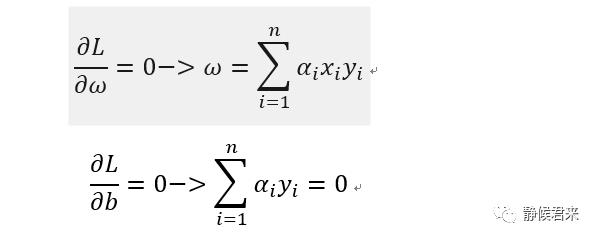
将结果带到原式得:

现在我们冷静下,我们这一步到底在干什么?我们这一步是在求具有最小间隔的数据点,下一步是要对该间隔最大化,即:
至此,一切都很完美,但是这里有个假设:数据必须100%线性可分。目前为止,我们知道,几乎所有的数据都不那么“干净”。这是我们就可以通过引入所谓松弛变量,来允许有些数据点可以处于分割面错误的一侧。这样我们的优化目标就能保持不变。但是此时新的约束条件变为:
这里的常数C用于控制”最大化间隔”和“保证大部分点的函数间隔小于1.0”这两个目标的权重(这很重要),在优化算法的实现代码中,常数C是一个参数,因此我们可以调节该参数得到不同的结果。一旦求出了所有的alpha,那么分割超平面就可以通过这些alpha表达,SVM的主要工作就是求解这些alpha。这个参数C是怎么来的,需要大量的推导证明,感兴趣的读者请参照PS。PS:https://www.cnblogs.com/pinard/p/6111471.html
如有疑问,请留言,如有错误,请指正。
以上是关于初识支持向量机(SVM)的主要内容,如果未能解决你的问题,请参考以下文章