原创支持向量机原理线性支持回归
Posted 机器学习爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创支持向量机原理线性支持回归相关的知识,希望对你有一定的参考价值。
在前四篇里面我们讲到了SVM的线性分类和非线性分类,以及在分类时用到的算法。这些都关注与SVM的分类问题。实际上SVM也可以用于回归模型,本篇就对如何将SVM用于回归模型做一个总结。重点关注SVM分类和SVM回归的相同点与不同点。
1. SVM回归模型的损失函数度量
回顾下我们前面SVM分类模型中,我们的目标函数是让 最小,同时让各个训练集中的点尽量远离自己类别一边的的支持向量,即 。如果是加入一个松弛变量 ,则目标函数是 ,对应的约束条件变成:
但是我们现在是回归模型,优化目标函数可以继续和SVM分类模型保持一致为 ,但是约束条件呢?不可能是让各个训练集中的点尽量远离自己类别一边的的支持向量,因为我们是回归模型,没有类别。对于回归模型,我们的目标是让训练集中的每个点 ,尽量拟合到一个线性模型 。对于一般的回归模型,我们是用均方差作为损失函数,但是SVM不是这样定义损失函数的。
SVM需要我们定义一个常量 ,对于某一个点 ,如果 ,则完全没有损失,如果 ,则对应的损失为 ,这个均方差损失函数不同,如果是均方差,那么只要 ,那么就会有损失。
如下图所示,在蓝色条带里面的点都是没有损失的,但是外面的点的是有损失的,损失大小为红色线的长度。
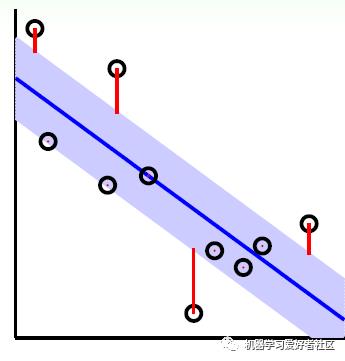
总结下,我们的SVM回归模型的损失函数度量为:
2. SVM回归模型的目标函数的原始形式
上一节我们已经得到了我们的损失函数的度量,现在可以可以定义我们的目标函数如下:
和SVM分类模型相似,回归模型也可以对每个样本 加入松弛变量 , 但是由于我们这里用的是绝对值,实际上是两个不等式,也就是说两边都需要松弛变量,我们定义为 , 则我们SVM回归模型的损失函数度量在加入松弛变量之后变为:
依然和SVM分类模型相似,我们可以用拉格朗日函数将目标优化函数变成无约束的形式,也就是拉格朗日函数的原始形式如下:
其中 ,均为拉格朗日系数。
3. SVM回归模型的目标函数的对偶形式
上一节我们讲到了SVM回归模型的目标函数的原始形式,我们的目标是
和SVM分类模型一样,这个优化目标也满足KKT条件,也就是说,我们可以通过拉格朗日对偶将我们的优化问题转化为等价的对偶问题来求解如下:
我们可以先求优化函数对于 的极小值, 接着再求拉格朗日乘子 的极大值。
首先我们来求优化函数对于 的极小值,这个可以通过求偏导数求得:
好了,我们可以把上面4个式子带入
看似很复杂,其实消除过程和系列第一篇第二篇文章类似,由于式子实在是冗长,这里我就不写出推导过程了,最终得到的对偶形式为:
对目标函数取负号,求最小值可以得到和SVM分类模型类似的求极小值的目标函数如下:
对于这个目标函数,我们依然可以用第四篇讲到的SMO算法来求出对应的 ,进而求出我们的回归模型系数 。
-
SVM回归模型系数的稀疏性 ================
在SVM分类模型中,我们的KKT条件的对偶互补条件为:
根据松弛变量定义条件,如果 ,我们有 ,此时
我们定义样本系数系数
根据上面 的计算式
5. SVM 算法小结
这个系列终于写完了,这里按惯例SVM 算法做一个总结。SVM算法是一个很优秀的算法,在集成学习和神经网络之类的算法没有表现出优越性能前,SVM基本占据了分类模型的统治地位。目前则是在大数据时代的大样本背景下,SVM由于其在大样本时超级大的计算量,热度有所下降,但是仍然是一个常用的机器学习算法。
SVM算法的主要优点有:
1) 解决高维特征的分类问题和回归问题很有效,在特征维度大于样本数时依然有很好的效果。
2) 仅仅使用一部分支持向量来做超平面的决策,无需依赖全部数据。
3) 有大量的核函数可以使用,从而可以很灵活的来解决各种非线性的分类回归问题。
4)样本量不是海量数据的时候,分类准确率高,泛化能力强。
SVM算法的主要缺点有:
1) 如果特征维度远远大于样本数,则SVM表现一般。
2) SVM在样本量非常大,核函数映射维度非常高时,计算量过大,不太适合使用。
3)非线性问题的核函数的选择没有通用标准,难以选择一个合适的核函数。
4)SVM对缺失数据敏感。
之后会对scikit-learn中SVM的分类算法库和回归算法库做一个总结,重点讲述调参要点,敬请期待。
前情回顾
在SVM的前三篇里,我们优化的目标函数最终都是一个关于
向量的函数。而怎么极小化这个函数,求出对应的
向量,进而求出分离超平面我们没有讲。本篇就对优化这个关于
向量的函数的SMO算法做一个总结。
1. 回顾SVM优化目标函数
我们首先回顾下我们的优化目标函数: $
我们的解要满足的KKT条件的对偶互补条件为:$
根据这个KKT条件的对偶互补条件,我们有:
由于,我们令,则有:
2. SMO算法的基本思想
上面这个优化式子比较复杂,里面有m个变量组成的向量 需要在目标函数极小化的时候求出。直接优化时很难的。SMO算法则采用了一种启发式的方法。它每次只优化两个变量,将其他的变量都视为常数。由于 .假如将 固定,那么 之间的关系也确定了。这样SMO算法将一个复杂的优化算法转化为一个比较简单的两变量优化问题。
为了后面表示方便,我们定义
由于 都成了常量,所有的常量我们都从目标函数去除,这样我们上一节的目标优化函数变成下式:
3. SMO算法目标函数的优化
为了求解上面含有这两个变量的目标优化问题,我们首先分析约束条件,所有的 都要满足约束条件,然后在约束条件下求最小。
根据上面的约束条件,又由于 均只能取值1或者-1, 这样 在[0,C]和[0,C]形成的盒子里面,并且两者的关系直线的斜率只能为1或者-1,也就是说 的关系直线平行于[0,C]和[0,C]形成的盒子的对角线,如下图所示:
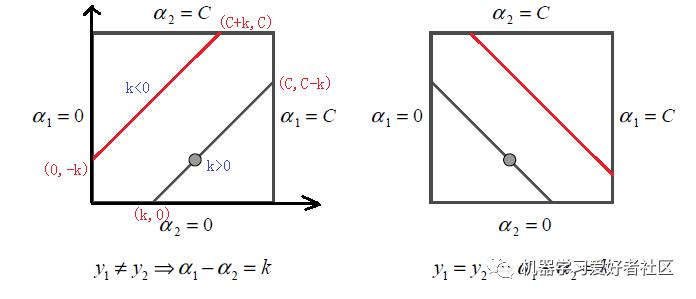
由于 的关系被限制在盒子里的一条线段上,所以两变量的优化问题实际上仅仅是一个变量的优化问题。不妨我们假设最终是 的优化问题。由于我们采用的是启发式的迭代法,假设我们上一轮迭代得到的解是 ,假设沿着约束方向 未经剪辑的解是 .本轮迭代完成后的解为
由于 必须满足上图中的线段约束。假设L和H分别是上图中 所在的线段的边界。那么很显然我们有:
而对于L和H,我们也有限制条件如果是上面左图中的情况,则
如果是上面右图中的情况,我们有:
也就是说,假如我们通过求导得到的 ,则最终的 应该为:
那么如何求出 呢?很简单,我们只需要将目标函数对 求偏导数即可。
首先我们整理下我们的目标函数。
为了简化叙述,我们令
,
其中 就是我们在第一节里面的提到的$
我们令
这样我们的优化目标函数进一步简化为:
由于 ,并且 ,可以得到 表达的式子为:
将上式带入我们的目标优化函数,就可以消除 ,得到仅仅包含 的式子。
忙了半天,我们终于可以开始求 了,现在我们开始通过求偏导数来得到 。
整理上式有:
将 带入上式,我们有:
我们终于得到了 的表达式:
利用上面讲到的 和 的关系式,我们就可以得到我们新的 了。利用 和 的线性关系,我们也可以得到新的 。
4. SMO算法两个变量的选择
SMO算法需要选择合适的两个变量做迭代,其余的变量做常量来进行优化,那么怎么选择这两个变量呢?
4.1 第一个变量的选择
SMO算法称选择第一个变量为外层循环,这个变量需要选择在训练集中违反KKT条件最严重的样本点。对于每个样本点,要满足的KKT条件我们在第一节已经讲到了:
一般来说,我们首先选择违反 这个条件的点。如果这些支持向量都满足KKT条件,再选择违反 和 的点。
4.2 第二个变量的选择
SMO算法称选择第二一个变量为内层循环,假设我们在外层循环已经找到了 , 第二个变量 的选择标准是让 有足够大的变化。由于 定了的时候, 也确定了,所以要想 最大,只需要在 为正时,选择最小的 作为 , 在 为负时,选择最大的 作为 ,可以将所有的 保存下来加快迭代。
如果内存循环找到的点不能让目标函数有足够的下降, 可以采用遍历支持向量点来做 ,直到目标函数有足够的下降, 如果所有的支持向量做 都不能让目标函数有足够的下降,可以跳出循环,重新选择
4.3 计算阈值b和差值
在每次完成两个变量的优化之后,需要重新计算阈值b。当 时,我们有
于是新的 为:
计算出 为:
可以看到上两式都有 ,因此可以将 用 表示为:
同样的,如果 , 那么有:
最终的 为:
得到了 我们需要更新 :
其中,S是所有支持向量 的集合。
好了,SMO算法基本讲完了,我们来归纳下SMO算法。
5. SMO算法总结
输入是m个样本,其中x为n维特征向量。y为二元输出,值为1,或者-1.精度e。
输出是近似解
1)取初值
2)按照4.1节的方法选择 ,接着按照4.2节的方法选择 ,求出新的 。
3)按照下式求出
4)利用 和 的关系求出
5)按照4.3节的方法计算 和
6)在精度e范围内检查是否满足如下的终止条件:
7)如果满足则结束,返回 ,否则转到步骤2)。
SMO算法终于写完了,这块在以前学的时候是非常痛苦的,不过弄明白就豁然开朗了。希望大家也是一样。写完这一篇, SVM系列就只剩下支持向量回归了,胜利在望!
1
2.
3.
5.
6.
7.
8.
记得把公号加星标,会第一时间收到通知。
创作不易,如果觉得有点用,希望可以随手转发或者”在看“,拜谢各位老铁
以上是关于原创支持向量机原理线性支持回归的主要内容,如果未能解决你的问题,请参考以下文章