深入理解支持向量机(SVM)
Posted 当交通遇上机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解支持向量机(SVM)相关的知识,希望对你有一定的参考价值。
1. 写在前面
如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的, 常见的机器学习算法:
-
监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻, 支持向量机,集成算法Adaboost等 -
无监督算法:聚类,降维,关联规则, PageRank等
为了详细的理解这些原理,曾经看过西瓜书,统计学习方法,机器学习实战等书,也听过一些机器学习的课程,但总感觉话语里比较深奥,读起来没有耐心,并且理论到处有,而实战最重要, 所以在这里想用最浅显易懂的语言写一个白话机器学习算法理论+实战系列。
个人认为,理解算法背后的idea和使用,要比看懂它的数学推导更加重要。idea会让你有一个直观的感受,从而明白算法的合理性,数学推导只是将这种合理性用更加严谨的语言表达出来而已,打个比方,一个梨很甜,用数学的语言可以表述为糖分含量90%,但只有亲自咬一口,你才能真正感觉到这个梨有多甜,也才能真正理解数学上的90%的糖分究竟是怎么样的。如果这些机器学习算法是个梨,本文的首要目的就是先带领大家咬一口。另外还有下面几个目的:
-
检验自己对算法的理解程度,对算法理论做一个小总结 -
能开心的学习这些算法的核心思想, 找到学习这些算法的兴趣,为深入的学习这些算法打一个基础。 -
每一节课的理论都会放一个实战案例,能够真正的做到学以致用,既可以锻炼编程能力,又可以加深算法理论的把握程度。 -
也想把之前所有的笔记和参考放在一块,方便以后查看时的方便。
学习算法的过程,获得的不应该只有算法理论,还应该有乐趣和解决实际问题的能力!
今天是白话机器学习算法理论+实战的第六篇,支持向量机算法(Support Vector Machine,SVM),这是一种二分类模型,它基本模型是定义在特征空间上的间隔最大的线性分类器, 间隔最大使它有别于感知机,支持向量机还包含核技巧,这使它成为实质上的非线性分类器,支持向量机在处理二分类问题上表现非常优越,也是一个很好的算法了。SVM 作为有监督的学习模型,通常可以帮我们模式识别、分类以及回归分析。
但是写这篇文章,确实有点难度,因为支持向量机的推导过程中涉及到很多的数学公式,什么拉格朗日对偶,KKT等这些东西了。而如果真的要从原理上深挖,那就不叫白话机器学习算法理论了,所以这里我还是会忽略掉推导演绎的过程,因为我觉得除了写论文,大部分时候,不会用到这些公式推导。
所谓白话,我理解的就是先懂算法的基本原理,然后用起来再说。至于具体细节,需要的时候再补,后面我会把所有数学公式的推导过程,更深层的原理的链接都贴上来。今天会用白话的语言说一下支持向量机的理论部分,然后说一下如何调用工具实现SVM,最后做一个乳腺癌检测的实战。
大纲如下:
-
SVM的工作原理(去找最大的分类间隔) -
硬间隔、软间隔和非线性SVM(线性可分SVM,线性SVM,非线性SVM) -
SVM如何解决多分类问题(一对多法和一对一法) -
SVM实战:如何进行乳腺癌检测?
OK, let's go!
2. 支持向量机?太深奥了名字,还是从几个小练习开始吧!
支持向量机,英文叫做Support Vector Machine。一听这名字就感觉高大上, 好多人一看到这就感觉太难了,名字都听不懂,然后就溜了,哪有电视好玩。但是你就不好奇听起来这么高大上的东西,在生活中是如何表现呢吗?其实也是来源于生活的, 不行?我们先做几个练习好不好。
练习1:桌子上放了红色和蓝色两种球,你能不能用一根棍子将这两种颜色的球分开?你说:这还不简单,就干净利落的直接搞定,嗯,太棒了。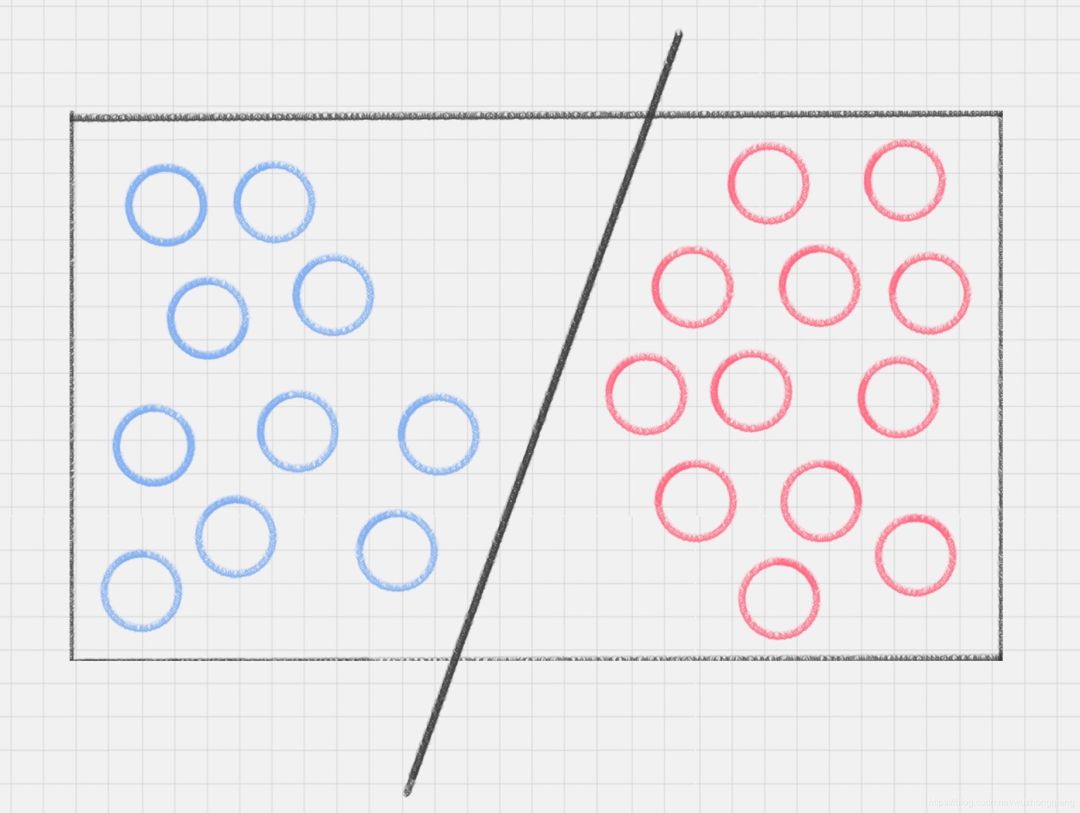 练习2:我第一个是不是出简单了啊?那么我提高一下难度,桌子上依然放着红色、蓝色两种球,但是它们的摆放不规律,如下图所示。如何用一根棍子把这两种颜色分开呢?
练习2:我第一个是不是出简单了啊?那么我提高一下难度,桌子上依然放着红色、蓝色两种球,但是它们的摆放不规律,如下图所示。如何用一根棍子把这两种颜色分开呢?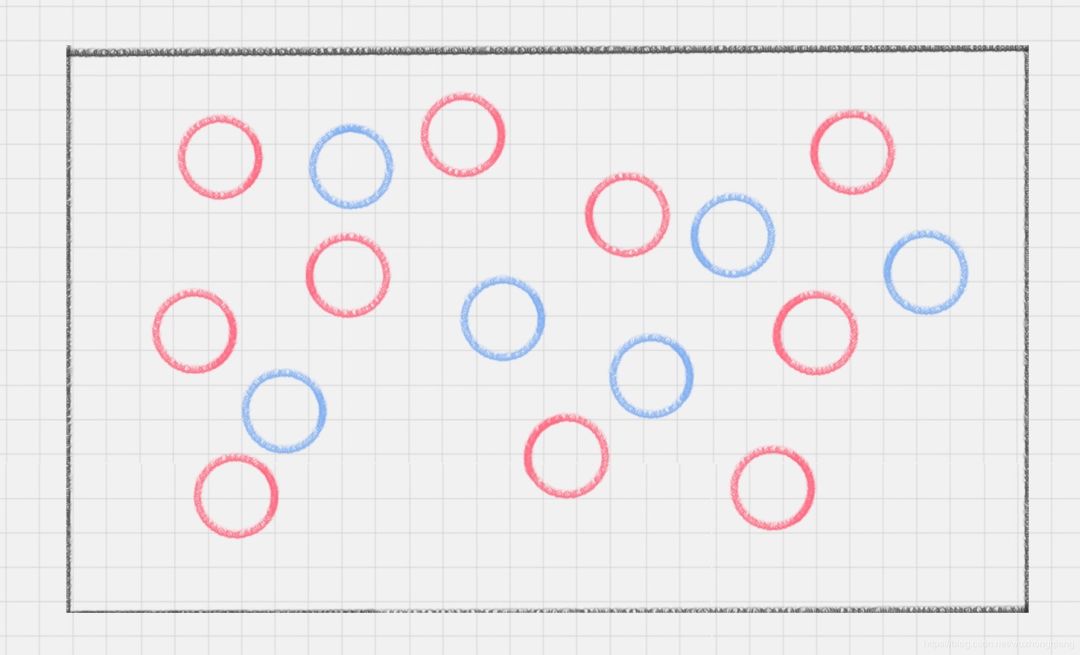 这时候你就为难了,这用一根棍子能分开? 除非把棍子弯曲,像下面这样:
这时候你就为难了,这用一根棍子能分开? 除非把棍子弯曲,像下面这样: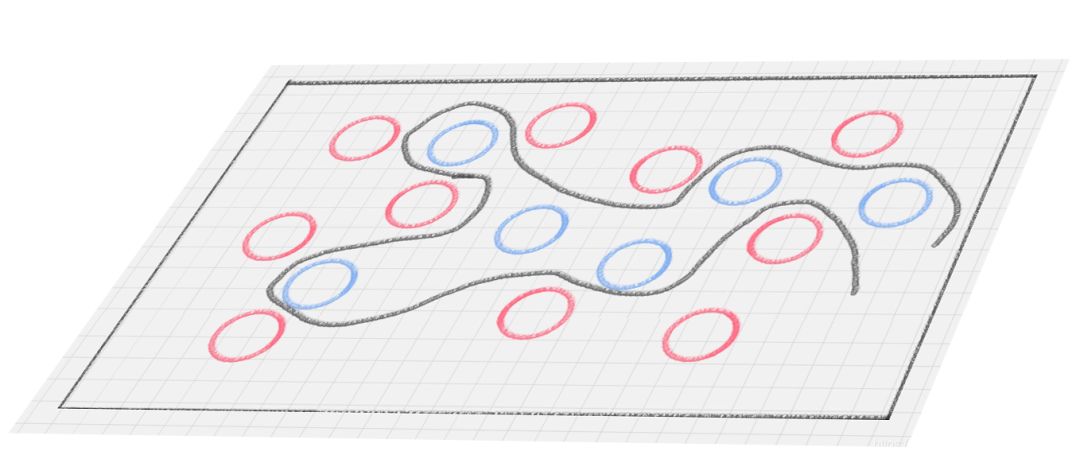 所以这里直线变成了曲线。如果在同一个平面上来看,红蓝两种颜色的球是很难分开的。那么有没有一种方式,可以让它们自然地分开呢?
所以这里直线变成了曲线。如果在同一个平面上来看,红蓝两种颜色的球是很难分开的。那么有没有一种方式,可以让它们自然地分开呢?
这里你可能会灵机一动,猛拍一下桌子,这些小球瞬间腾空而起,如下图所示。在腾起的那一刹那,出现了一个水平切面,恰好把红、蓝两种颜色的球分开。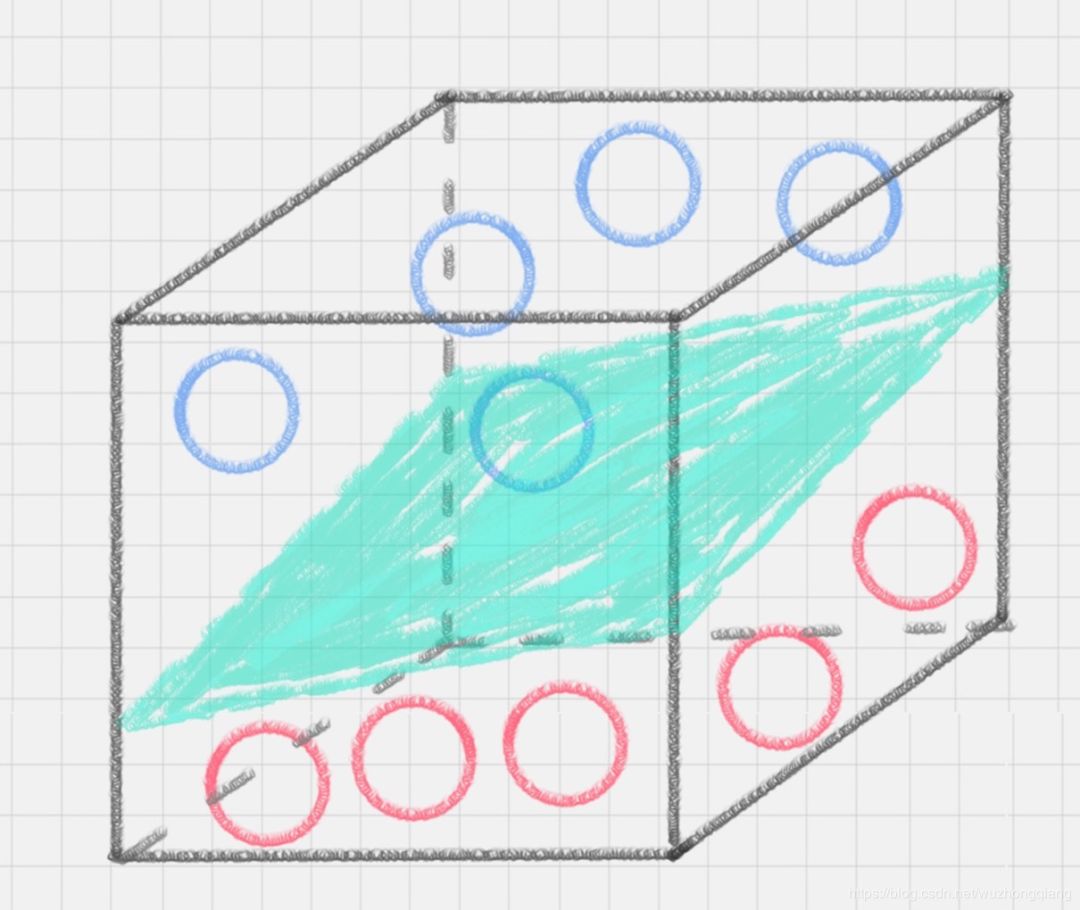 在这里,二维平面变成了三维空间。原来的曲线变成了一个平面。这个平面,我们就叫做超平面。(你真是太厉害了,球都飞成这样,手疼不疼?)
在这里,二维平面变成了三维空间。原来的曲线变成了一个平面。这个平面,我们就叫做超平面。(你真是太厉害了,球都飞成这样,手疼不疼?)
你知道吗?这其实就有点支持向量机的味道了,支持向量机的计算过程,就是帮我们找到那个绿色的超平面的过程,这个超平面就是我们的SVM分类器。哈哈,神奇不?这么高大上的东西,竟然是在找这样一个超平面?
下面看看SVM的原理吧!
3. SVM的工作原理
还是从练习1开始,我相信,好多人划分的方式可能和我画的不一样,比如下面这几种: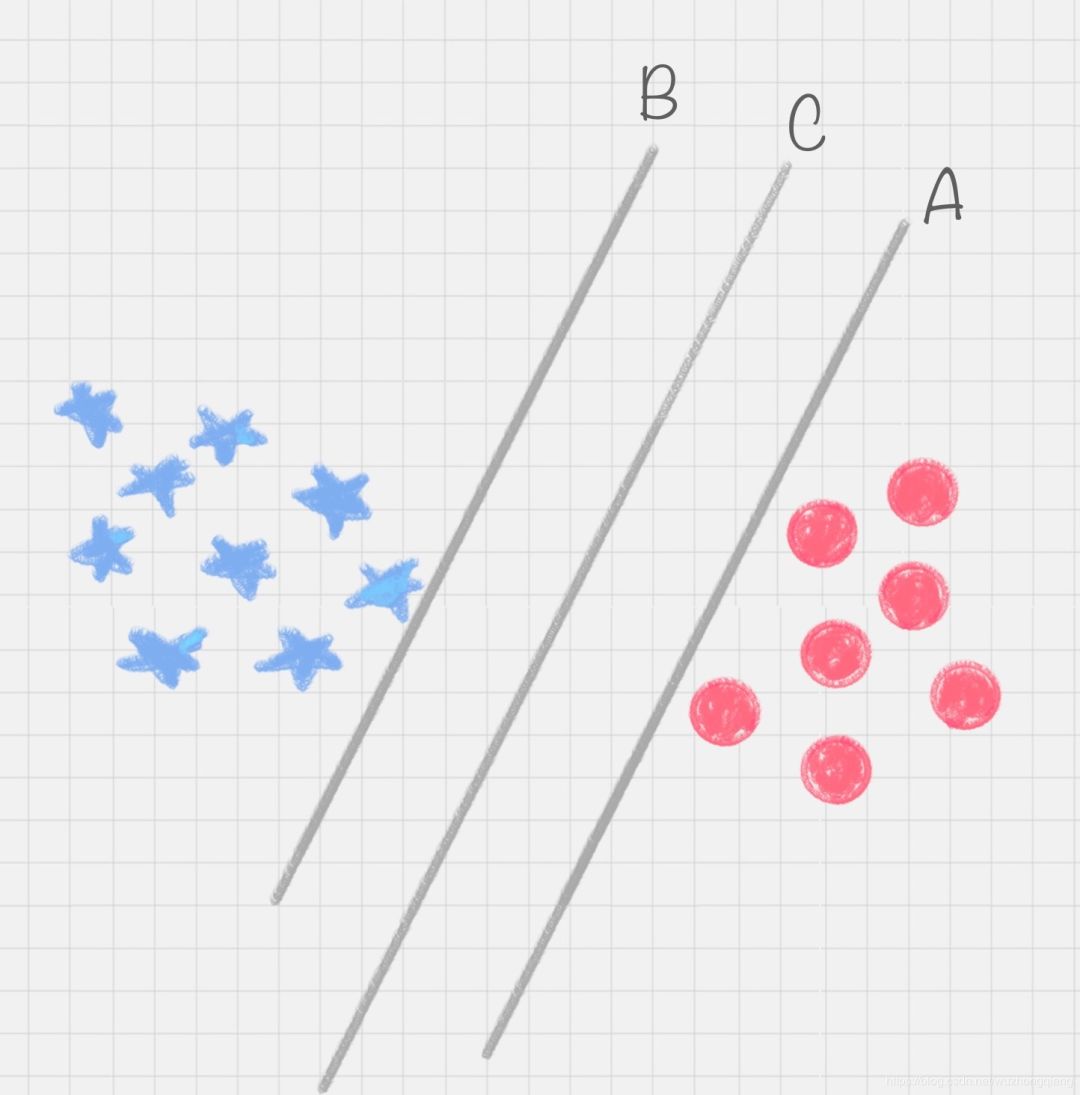 A,B,C这三条直线,都可以把红蓝球给分开。究竟哪一个最好呢?
A,B,C这三条直线,都可以把红蓝球给分开。究竟哪一个最好呢?
★很明显,直线 B 更靠近蓝色球,但是在真实环境下,球再多一些的话,蓝色球可能就被划分到了直线 B 的右侧,被认为是红色球。
”
同样直线 A 更靠近红色球,在真实环境下,如果红色球再多一些,也可能会被误认为是蓝色球。
所以相比于直线 A 和直线 B,直线 C 的划分更优,因为它的鲁棒性更强。啥叫鲁棒性?在这里你可以理解成容错能力比较强。不会轻易的分错红色球和蓝色球。
你可能又说了,你画的当然那么轻松,可以计算机究竟怎么才能找到直线C这种呢?(实际上,我们的分类环境不是在二维平面中的,而是在多维空间中,这样直线 C 就变成了决策面 C。)
问得好,下面就来回答这个问题,可以回答之前,需要先介绍一个SVM特有的概念:分类间隔。
在保证决策面不变,且分类不产生错误的情况下,我们可以移动决策面 C,直到产生两个极限的位置:如图中的决策面 A 和决策面 B。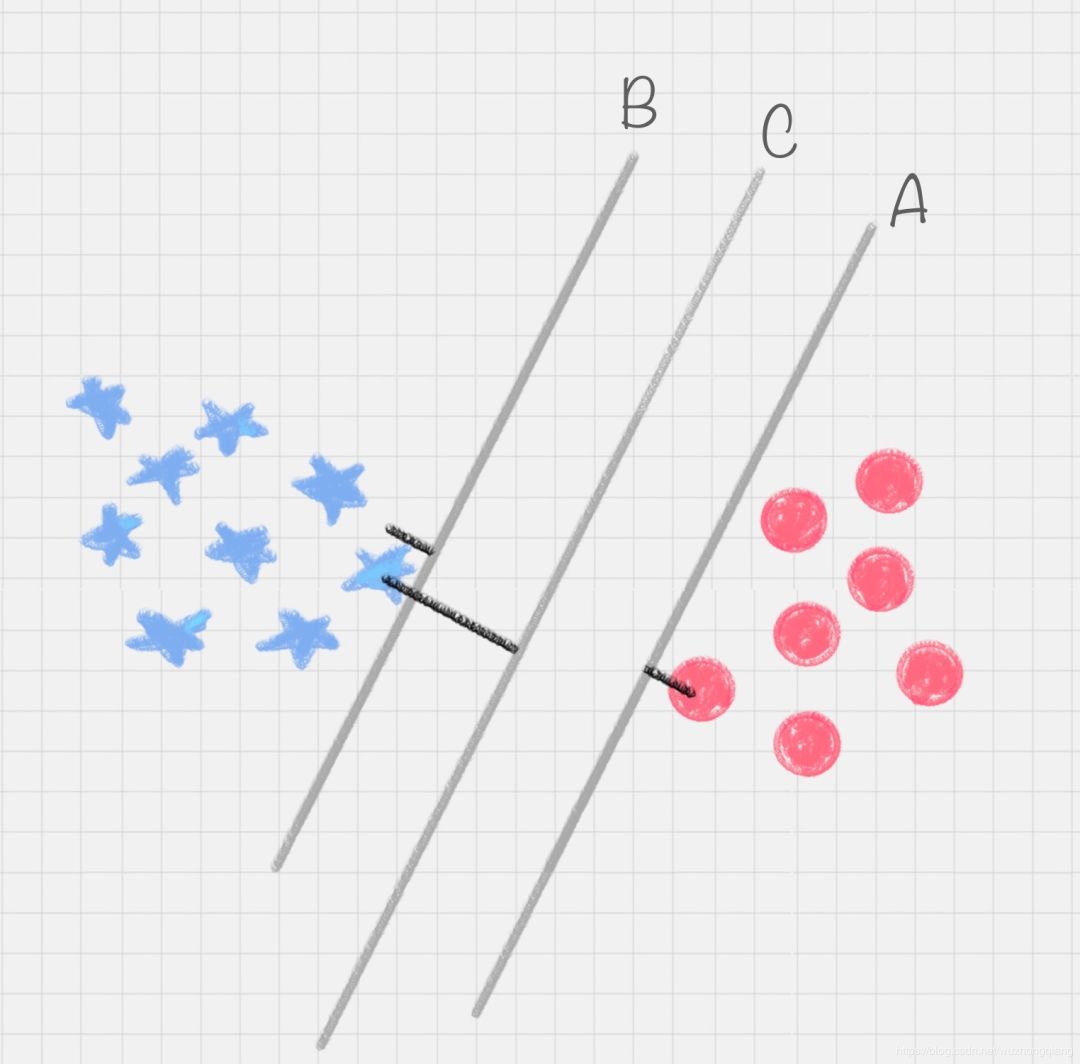 极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置 A 和 B 之间的分界线 C 就是最优决策面。
极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置 A 和 B 之间的分界线 C 就是最优决策面。
极限位置到最优决策面 C 之间的距离,就是“分类间隔”,英文叫做 margin。 如果我们转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是 SVM 要找的最优解。那么怎么确定最大间隔呢?
如果我们转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是 SVM 要找的最优解。那么怎么确定最大间隔呢?
谈到分类间隔这个词,就有必要先说说这个距离应该如何衡量了。(间隔可以分为函数间隔和几何间隔,前者是衡量多个点都同一超平面的相对距离,而后者是衡量同一点到不同超平面的真实距离,很明显,这里需要用到后者,因为我们这里有太多的超平面)
而如果想说距离,就得先定义出超平面来吧。
在上面这个例子中,如果我们把红蓝两种颜色的球放到一个三维空间里,你发现决策面就变成了一个平面。这里我们可以用线性函数来表示,如果在一维空间里就表示一个点,在二维空间里表示一条直线,在三维空间中代表一个平面,当当然空间维数还可以更多,这样我们给这个线性函数起个名称叫做“超平面”。超平面的数学表达可以写成: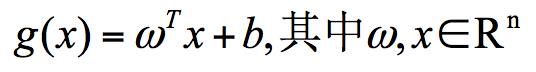 在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。
在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。
SVM 就是帮我们找到一个超平面,这个超平面能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化。
接下来,我们定义某类样本集到超平面的距离是这个样本集合内的样本到超平面的最短距离。我们用 di 代表点 xi 到超平面 wxi+b=0 的欧氏距离。因此我们要求 di 的最小值,用它来代表这个样本到超平面的最短距离。di 可以用公式计算得出: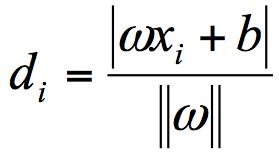 其中||w||为超平面的范数,di 的公式可以用解析几何知识进行推导,这里不做解释。
其中||w||为超平面的范数,di 的公式可以用解析几何知识进行推导,这里不做解释。
SVM要做的就是求解最大分类间隔, 怎么求?我们已经知道了点到超平面的距离公式,我们希望一个训练样本(xi,yi),这个样本点和分离超平面的几何距离最小,记作γ,其他的每一个训练样本的间隔都大于γ,在这个约束下,我们要最大化这个γ,即最大化超平面(w,b)关于训练集的几何间隔。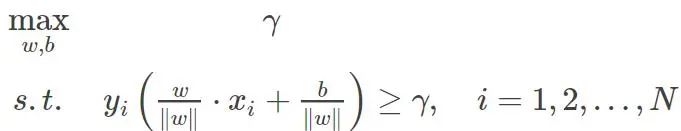 这就成了求解一个优化问题了。上面那种形式还可以这样表示:
这就成了求解一个优化问题了。上面那种形式还可以这样表示: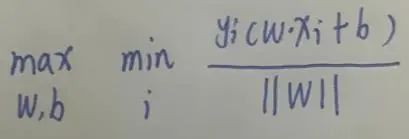 而这个||w||这是个常数,可以提出来:
而这个||w||这是个常数,可以提出来: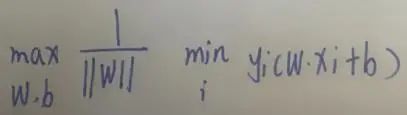 这样就会发现,后面那个是一个函数间隔了,我们知道函数间隔的取值并不影响最优化问题的解(因为假设w和b按比例变为λw和λb,那么函数间隔也变为λ倍,这一变化对最小化问题不影响),所以索性我们取后面的为1, 即所有样本点到超平面的函数间隔至少是1,即下面的改写:
这样就会发现,后面那个是一个函数间隔了,我们知道函数间隔的取值并不影响最优化问题的解(因为假设w和b按比例变为λw和λb,那么函数间隔也变为λ倍,这一变化对最小化问题不影响),所以索性我们取后面的为1, 即所有样本点到超平面的函数间隔至少是1,即下面的改写: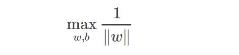 这个问题,我们可以转换一下,化成倒数,同时最小化,变成等价的问题:
这个问题,我们可以转换一下,化成倒数,同时最小化,变成等价的问题: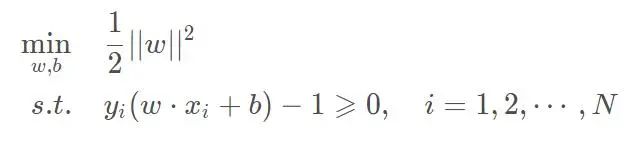 到此,这就成了一个凸优化的问题,可以转成拉格朗日的对偶问题,判断是否满足KKT条件,然后求解,需要数学公式推导了。但是不想写这一块,因为这里只想说明这个超平面通过这种方式就能求出来,而不需要知道是怎么求出来的。
到此,这就成了一个凸优化的问题,可以转成拉格朗日的对偶问题,判断是否满足KKT条件,然后求解,需要数学公式推导了。但是不想写这一块,因为这里只想说明这个超平面通过这种方式就能求出来,而不需要知道是怎么求出来的。
就假设我求完了,求出了这个超平面,比如下面这个: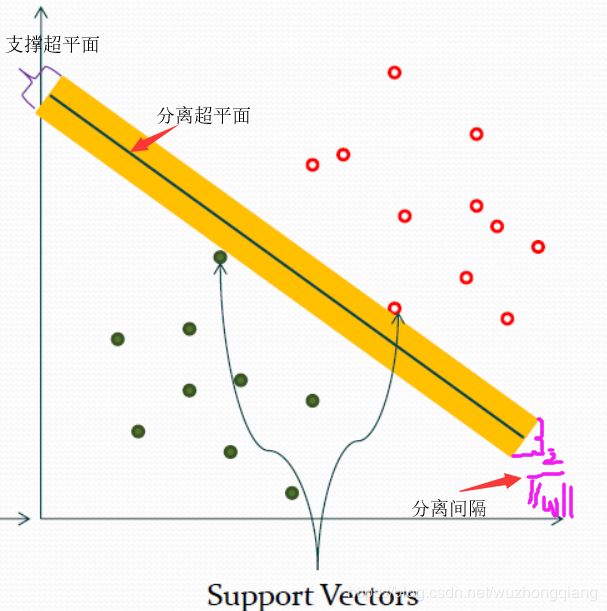 数学公式不知道不要紧,但是得知道几个术语, 要不然就是外行了。
数学公式不知道不要紧,但是得知道几个术语, 要不然就是外行了。
-
分离超平面:也就是那个能把样本分开的那个最优超平面了 -
支撑超平面:是分离超平面平移到极限位置之后的那两条直线 -
分离间隔:支撑超平面之间的距离 -
支持向量:就是那两个极限位置的样本。(在决定分离超平面时,只有支持向量在起作用,而其他实例点不起作用。由于支持向量在确定分离超平面中起着决定性作用,所以将这类模型叫做支持向量机)
支持向量机的原理知道了吧? 就是求一个超平面,这个超平面能把所有的样本点最有把握的分开。最有把握就是说,样本点到超平面的距离最大。而之所以叫做支持向量,是因为在决定分离超平面的时候,只有极限位置的那两个点有用,其他点根本没有大作用,因为只要极限位置离得超平面的距离最大,就是最佳的分离平面了。而具体的求解方法,是求解一个凸优化的问题,用到一些数学的知识,在这里我们不展开讲。不知道这样说明白了没有?
下面,还有一个要讨论的问题,就是,线性可分的情况往往在实际生活中是一个理想的状态,这个条件实际上太严厉了,哪有那么好的数据?一点噪声都没有吗? 万一有一点数据怎么办呢?
别慌,支持向量机没有那么脆弱,上面说的那种完全线性可分,叫做硬间隔最大化,看这个词也知道多么严厉了啊!有硬,当然就有软了,下面谈谈软间隔最大化,也就是有点噪声点怎么样。
4. 硬间隔、软间隔和非线性SVM
假如数据是完全的线性可分的,那么学习到的模型可以称为硬间隔支持向量机。换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误。
我们知道,实际工作中的数据没有那么“干净”,或多或少都会存在一些噪点。所以线性可分是个理想情况。这时,我们需要使用到软间隔 SVM(近似线性可分),比如下面这种情况: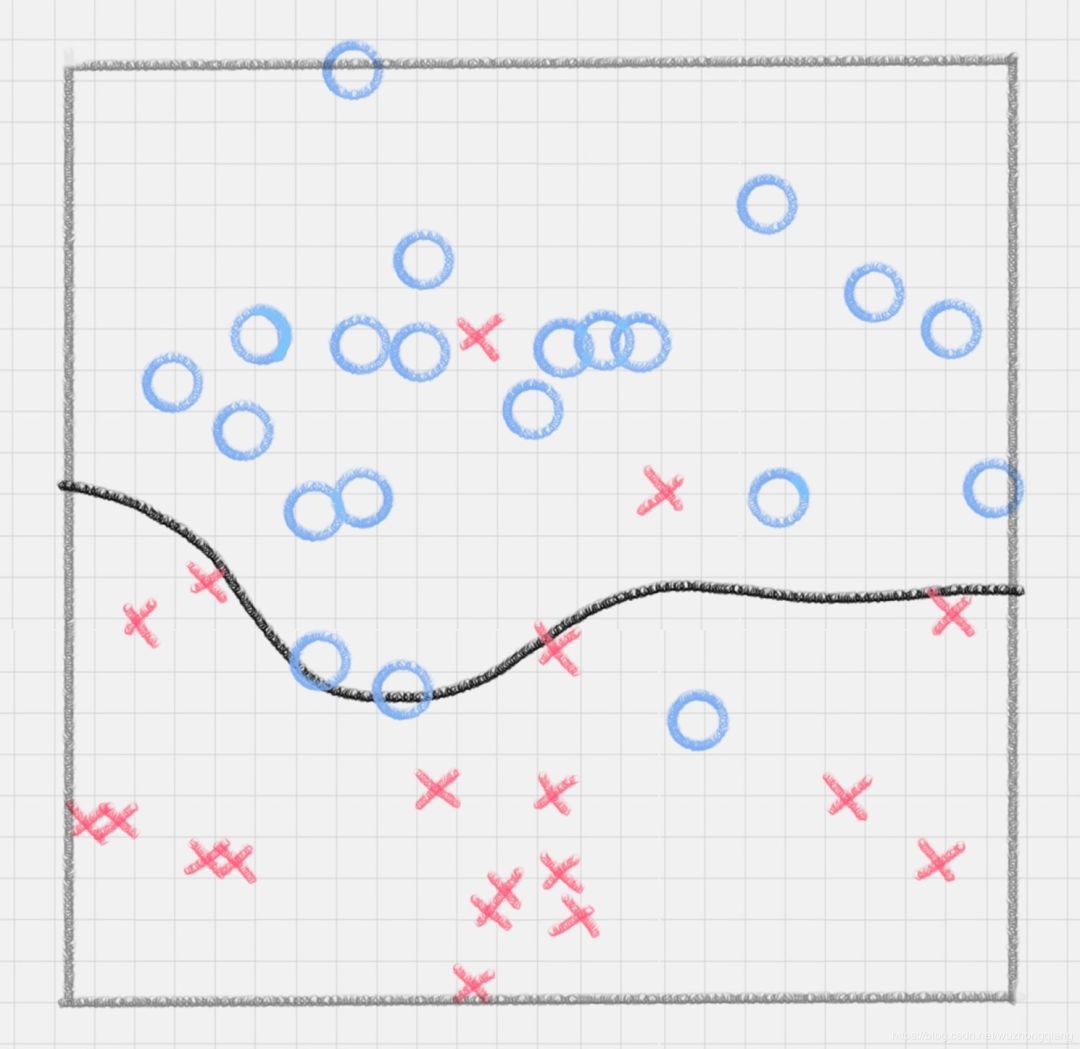 这种情况,是不是就柔和了一些啊,就是允许有分类错误的点。人无完人嘛,况且机器了啊。那么优化目标变成了下面的这种:
这种情况,是不是就柔和了一些啊,就是允许有分类错误的点。人无完人嘛,况且机器了啊。那么优化目标变成了下面的这种: 又出来一个公式,但是这一个和上面的那个最优化问题类似,无非就是目标那多出来一项松弛项。就是允许有分类错误的点,但是尽可能的少就可以了。这个也是转成拉格朗日对偶问题进行求解,依然不用求,了解一下即可。如果想知道怎么求,可以参考我下面的链接(统计学习方法之支持向量机笔记)
又出来一个公式,但是这一个和上面的那个最优化问题类似,无非就是目标那多出来一项松弛项。就是允许有分类错误的点,但是尽可能的少就可以了。这个也是转成拉格朗日对偶问题进行求解,依然不用求,了解一下即可。如果想知道怎么求,可以参考我下面的链接(统计学习方法之支持向量机笔记)
另外还存在一种情况,就是非线性支持向量机。
比如下面的样本集就是个非线性的数据。图中的两类数据,分别分布为两个圆圈的形状。那么这种情况下,不论是多高级的分类器,只要映射函数是线性的,就没法处理,SVM 也处理不了。
这时,我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行。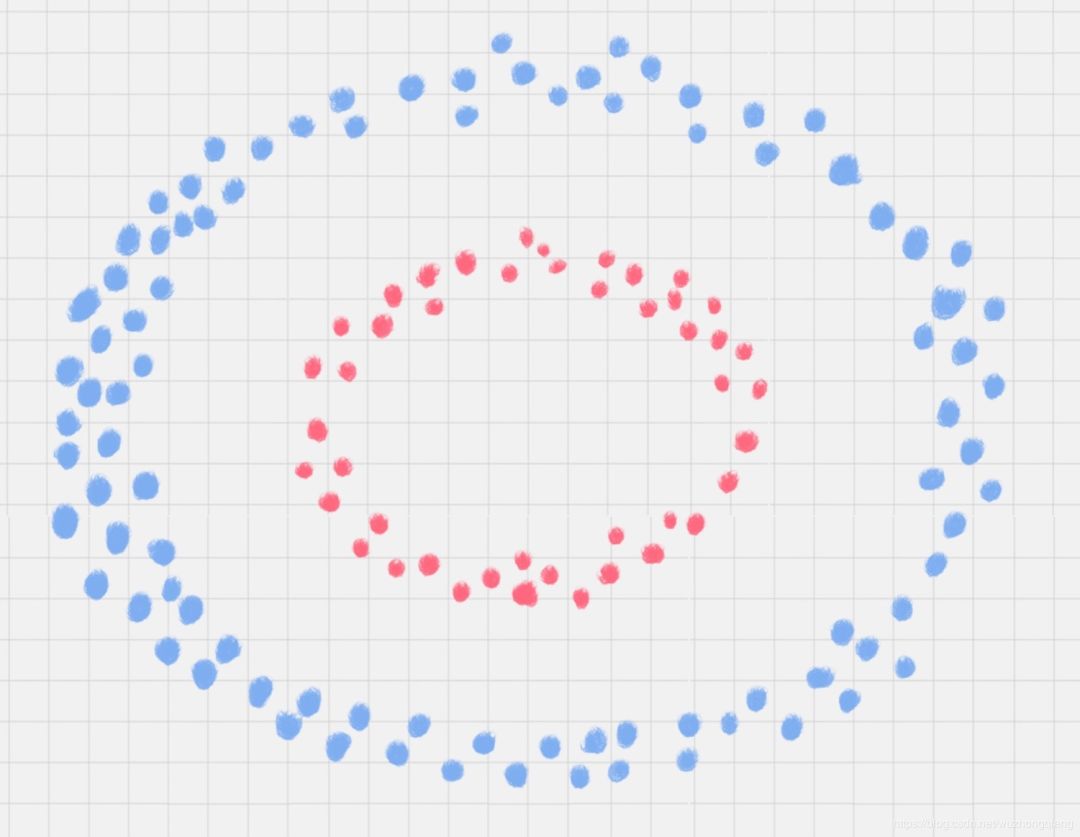 还记得上面的一拍桌子,球飞起来的情况不? 你拍手的过程,其实就是核函数做映射的过程,把二维平面上的点,通过等价运算,放到了三维空间中,这样就可能找出一个超平面来分类这些点了。
还记得上面的一拍桌子,球飞起来的情况不? 你拍手的过程,其实就是核函数做映射的过程,把二维平面上的点,通过等价运算,放到了三维空间中,这样就可能找出一个超平面来分类这些点了。
核技巧类似这样: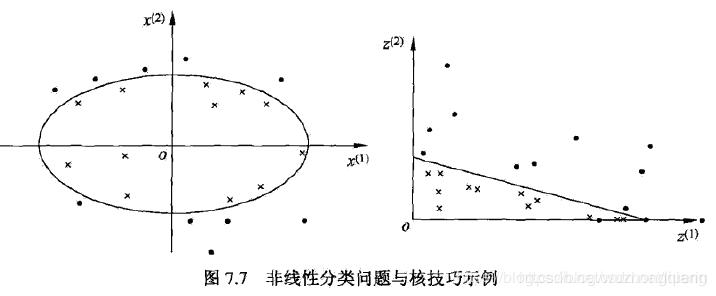 所以在非线性 SVM 中,核函数的选择就是影响 SVM 最大的变量。最常用的核函数有线性核、多项式核、高斯核、拉普拉斯核、sigmoid 核,或者是这些核函数的组合。这些函数的区别在于映射方式的不同。通过这些核函数,我们就可以把样本空间投射到新的高维空间中。
所以在非线性 SVM 中,核函数的选择就是影响 SVM 最大的变量。最常用的核函数有线性核、多项式核、高斯核、拉普拉斯核、sigmoid 核,或者是这些核函数的组合。这些函数的区别在于映射方式的不同。通过这些核函数,我们就可以把样本空间投射到新的高维空间中。
至于这些核函数长什么样子,可以看下面的链接,在sklearn中使用的时候,还会介绍具体怎么用。
至此,向量机的理论就讲的差不多了,你明白了多少?
简单的理一下子吧:(放在平时是不理的,由于这块确实涉及到了太多的数学知识,只白话描述有点困难,所以理理上面想表达一个什么意思):
★首先,我们所说的支持向量机,其实有三种情况:
”
样本完全线性可分,针对这种情况,我们通过硬间隔最大化方式学习,即找到一个超平面能够完全无误的分类。目标函数长这样: 求解这个问题,需要转成拉格朗日对偶形式,然后用拉格朗日函数法,考虑KKT条件等一系列操作,会求出最优的w*, b*。就形成了一个超平面:g(x) = w x + b。就是最优的面,这样求出的向量机叫做 线性可分支持向量机。
样本不完全线性可分,针对这种情况,通过软间隔最大化方式学习,即允许分类错误,但是要尽可能的少。目标函数长这样: 求解这个问题,也同样需要转成拉格朗日的对偶形式,然后考虑拉格朗日乘数法,KKT等,求出最优的w*, 但此时b*不止一个。这时候,求出的向量机叫做 线性支持向量机。
样本本身就是一个非线性的数据集。这时候就需要通过核函数进行转换一下,到一个别的空间里面,让它变成一个线性可分的,然后再去求最优的超平面。这一个优化问题长这样:当然已经转成了对偶问题, K(xi, xj) 就是通过核函数进行的转换。这一个也能解出结果来。这里不详细描述,这样的向量机叫做 非线性支持向量机。
关于向量机的原理这块,我想说的就是上面这些。 知道这三种情况,和优化目标,大体上是怎么个求法,就可以了。现在没有必要追究那么明白,在深度学习的时代,神经网络都搞不过来,如果不想真的搞科研,真的在向量机上突破,我建议先懂我上面描述的这些,然后重点在下面学学咋用,你会发现,即使你不明白这些东西手算怎么求解,你也同样可以学会根据样本特征实现向量机,并且用支持向量机进行乳腺癌的检测。即使你会手算支持向量机的求解,你也无法用手算进行乳腺癌的检测,还是得使用工具实现向量机,去进行检测。
好吧,可能已经迷糊了,什么这的,那的啊? 我理解,这块确实,如果想真的学明白,还就得知道一些数学的知识, 水平有限,既想白话,又想不写数学,我太难了。
下面聊点轻松点的话题,上面都是讲的如何支持向量机把红球和篮球分开,那如果我不是两种颜色的球呢?向量机应该怎么做,这就是一个多分类的问题了。
5. 用SVM如何解决多分类问题
SVM 本身是一个二值分类器,最初是为二分类问题设计的,也就是回答 Yes 或者是 No。而实际上我们要解决的问题,可能是多分类的情况,比如对文本进行分类,或者对图像进行识别。
针对这种情况,我们可以将多个二分类器组合起来形成一个多分类器,常见的方法有“一对多法”和“一对一法”两种。
-
一对多法 假设我们要把物体分成 A、B、C、D 四种分类,那么我们可以先把其中的一类作为分类 1,其他类统一归为分类 2。这样我们可以构造 4 种 SVM,分别为以下的情况: (1)样本 A 作为正集,B,C,D 作为负集; (2)样本 B 作为正集,A,C,D 作为负集; (3)样本 C 作为正集,A,B,D 作为负集; (4)样本 D 作为正集,A,B,C 作为负集。这种方法,针对 K 个分类,需要训练 K 个分类器,分类速度较快,但训练速度较慢,因为每个分类器都需要对全部样本进行训练,而且负样本数量远大于正样本数量,会造成样本不对称的情况,而且当增加新的分类,比如第 K+1 类时,需要重新对分类器进行构造。 -
一对一法 一对一法的初衷是想在训练的时候更加灵活。我们可以在任意两类样本之间构造一个 SVM,这样针对 K 类的样本,就会有 C(k,2) 类分类器。比如我们想要划分 A、B、C 三个类,可以构造 3 个分类器: (1)分类器 1:A、B; (2)分类器 2:A、C; (3)分类器 3:B、C。当对一个未知样本进行分类时,每一个分类器都会有一个分类结果,即为 1 票,最终得票最多的类别就是整个未知样本的类别。
这样做的好处是,如果新增一类,不需要重新训练所有的 SVM,只需要训练和新增这一类样本的分类器。而且这种方式在训练单个 SVM 模型的时候,训练速度快。
但这种方法的不足在于,分类器的个数与 K 的平方成正比,所以当 K 较大时,训练和测试的时间会比较慢。
6. 支持向量机实战 - 如何乳腺癌检测?
懂了上面的原理之后,我们就可以亲手实现向量机,然后进行实战了。哈哈,激动不?你可能会说,上面的原理还没搞清楚呢? 还没弄明白KKT和拉格朗日对偶呢, 那也没关系,你也能够先用,然后在学。
6.1 如何在sklearn中使用SVM
在Python的sklearn工具包中有SVM算法, 首先引入工具包
from sklearn import svm
SVM 既可以做分类,也可以做回归。
-
当用 SVM 做回归的时候,我们可以使用 SVR 或 LinearSVR。SVR 的英文是 Support Vector Regression -
当做分类器的时候,我们使用的是 SVC 或者 LinearSVC。SVC 的英文是 Support Vector Classification。
简单说一下两者的区别:
★从名字上你能看出 LinearSVC 是个线性分类器,用于处理线性可分的数据,只能使用线性核函数。
”
如果是针对非线性的数据,需要用到 SVC。在 SVC 中,我们既可以使用到线性核函数(进行线性划分),也能使用高维的核函数(进行非线性划分)。
如何创建一个SVM分类器呢?
★首先使用SVC的构造函数:model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’),这里有三个重要的参数 kernel、C 和 gamma。
kernel代表核函数的选择,有四种选择,默认rbf,即高斯核函数 ★”
linear:线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据。 poly:多项式核函数,多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大。 rbf:高斯核函数(默认),高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数。 sigmoid:sigmoid 核函数,sigmoid 经常用在神经网络的映射中。因此当选用 sigmoid 核函数时,SVM 实现的是多层神经网络。 ”
参数 C 代表目标函数的惩罚系数,惩罚系数指的是分错样本时的惩罚程度,默认情况下为 1.0。当 C 越大的时候,分类器的准确性越高,但同样容错率会越低,泛化能力会变差。相反,C 越小,泛化能力越强,但是准确性会降低。 参数 gamma 代表核函数的系数,默认为样本特征数的倒数,即 gamma = 1 / n_features。
在创建 SVM 分类器之后,就可以输入训练集对它进行训练。
★我们使用 model.fit(train_X,train_y),传入训练集中的特征值矩阵 train_X 和分类标识 train_y。特征值矩阵就是我们在特征选择后抽取的特征值矩阵(当然你也可以用全部数据作为特征值矩阵);分类标识就是人工事先针对每个样本标识的分类结果。这样模型会自动进行分类器的训练。我们可以使用 prediction=model.predict(test_X) 来对结果进行预测,传入测试集中的样本特征矩阵 test_X,可以得到测试集的预测分类结果 prediction。
”
同样我们也可以创建线性 SVM 分类器
★使用 model=svm.LinearSVC()。在 LinearSVC 中没有 kernel 这个参数,限制我们只能使用线性核函数。由于 LinearSVC 对线性分类做了优化,对于数据量大的线性可分问题,使用 LinearSVC 的效率要高于 SVC。
”
如果你不知道数据集是否为线性,可以直接使用 SVC 类创建 SVM 分类器。
在训练和预测中,LinearSVC 和 SVC 一样,都是使用 model.fit(train_X,train_y) 和 model.predict(test_X)。
6.2 SVM进行乳腺癌检测
6.2.1 数据集介绍
数据集来自美国威斯康星州的乳腺癌诊断数据集,点击这里进行下载。
医疗人员采集了患者乳腺肿块经过细针穿刺 (FNA) 后的数字化图像,并且对这些数字图像进行了特征提取,这些特征可以描述图像中的细胞核呈现。肿瘤可以分成良性和恶性。部分数据截屏如下所示: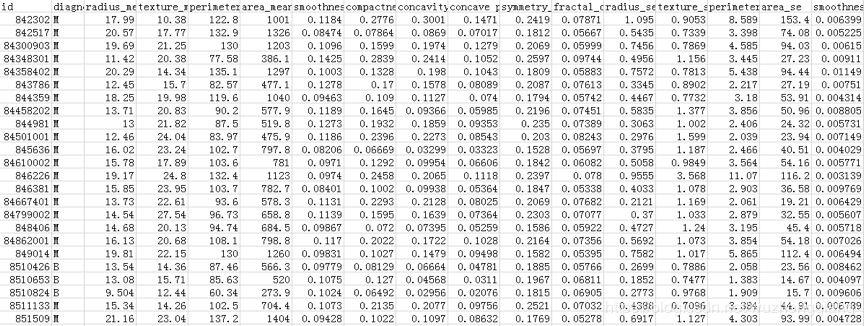 数据表一共包括了 32 个字段,代表的含义如下:
数据表一共包括了 32 个字段,代表的含义如下: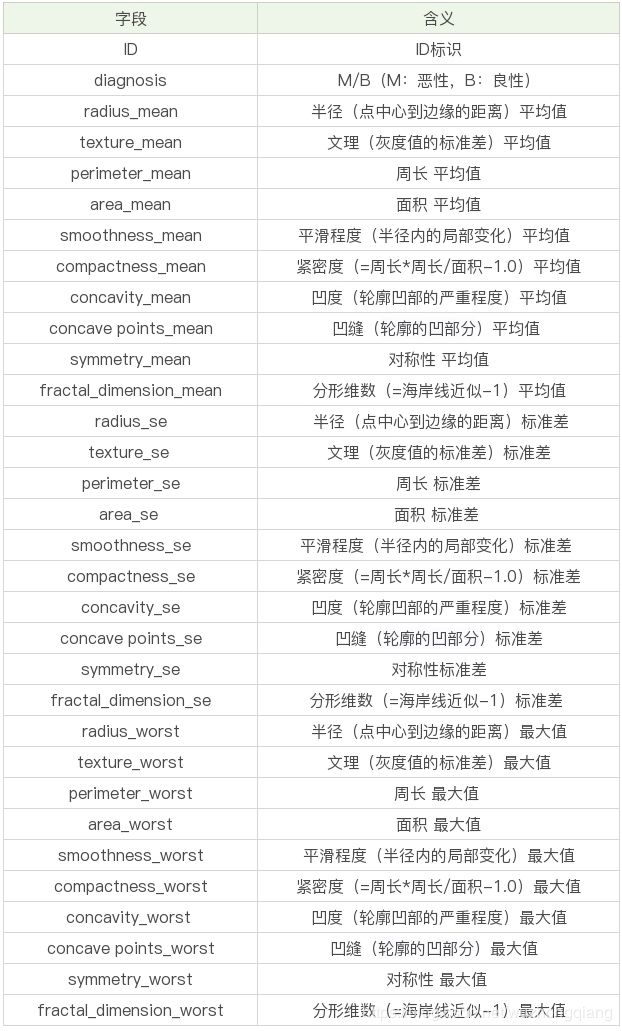 上面的表格中,mean 代表平均值,se 代表标准差,worst 代表最大值(3 个最大值的平均值)。每张图像都计算了相应的特征,得出了这 30 个特征值(不包括 ID 字段和分类标识结果字段 diagnosis),实际上是 10 个特征值(radius、texture、perimeter、area、smoothness、compactness、concavity、concave points、symmetry 和 fractal_dimension_mean)的 3 个维度,平均、标准差和最大值。这些特征值都保留了 4 位数字。字段中没有缺失的值。在 569 个患者中,一共有 357 个是良性,212 个是恶性。
上面的表格中,mean 代表平均值,se 代表标准差,worst 代表最大值(3 个最大值的平均值)。每张图像都计算了相应的特征,得出了这 30 个特征值(不包括 ID 字段和分类标识结果字段 diagnosis),实际上是 10 个特征值(radius、texture、perimeter、area、smoothness、compactness、concavity、concave points、symmetry 和 fractal_dimension_mean)的 3 个维度,平均、标准差和最大值。这些特征值都保留了 4 位数字。字段中没有缺失的值。在 569 个患者中,一共有 357 个是良性,212 个是恶性。
6.2.2 项目执行流程
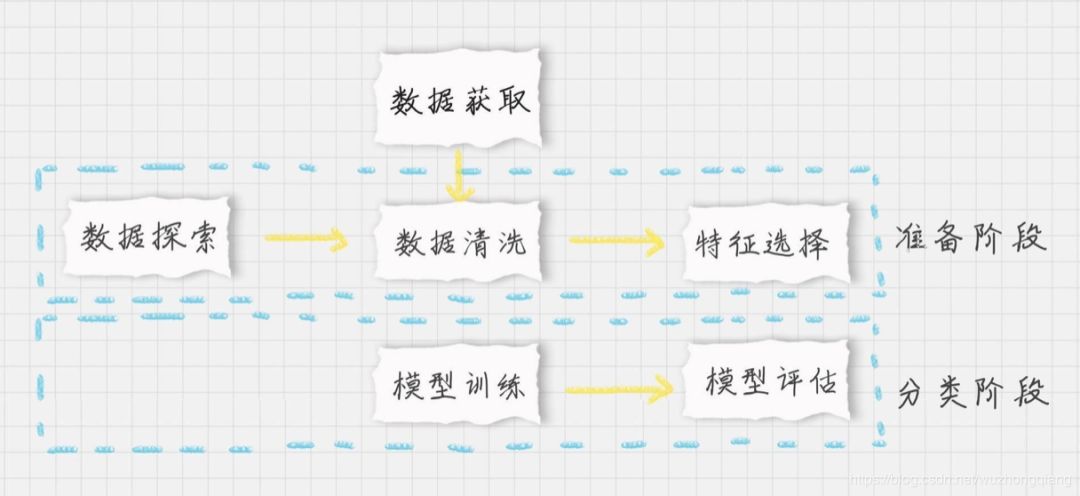
-
首先我们需要加载数据源; -
在准备阶段,需要对加载的数据源进行探索,查看样本特征和特征值,这个过程你也可以使用数据可视化,它可以方便我们对数据及数据之间的关系进一步加深了解。然后按照“完全合一”的准则来评估数据的质量,如果数据质量不高就需要做数据清洗。数据清洗之后,你可以做特征选择,方便后续的模型训练; -
在分类阶段,选择核函数进行训练,如果不知道数据是否为线性,可以考虑使用 SVC(kernel=‘rbf’) ,也就是高斯核函数的 SVM 分类器。然后对训练好的模型用测试集进行评估。
下面,我们编写一下吧:在导入数据集之前,你需要用到这些包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.svm import SVC, LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
导入数据集
# 加载数据集,你需要把数据放到目录中
data = pd.read_csv("./data.csv")
# 数据探索
# 因为数据集中列比较多,我们需要把dataframe中的列全部显示出来
pd.set_option('display.max_columns', None)
print(data.columns)
print(data.head(5))
print(data.describe())
# 结果如下
Index(['id', 'diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se', 'texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst',
'perimeter_worst', 'area_worst', 'smoothness_worst',
'compactness_worst', 'concavity_worst', 'concave points_worst',
'symmetry_worst', 'fractal_dimension_worst'],
dtype='object')
id diagnosis radius_mean texture_mean perimeter_mean area_mean \
0 842302 M 17.99 10.38 122.80 1001.0
1 842517 M 20.57 17.77 132.90 1326.0
2 84300903 M 19.69 21.25 130.00 1203.0
3 84348301 M 11.42 20.38 77.58 386.1
4 84358402 M 20.29 14.34 135.10 1297.0
接下来,数据清洗
★运行结果中,你能看到 32 个字段里,id 是没有实际含义的,可以去掉。diagnosis 字段的取值为 B 或者 M,我们可以用 0 和 1 来替代。另外其余的 30 个字段,其实可以分成三组字段,下划线后面的 mean、se 和 worst 代表了每组字段不同的度量方式,分别是平均值、标准差和最大值。
”
代码如下:
# 将特征字段分成3组
features_mean= list(data.columns[2:12])
features_se= list(data.columns[12:22])
features_worst=list(data.columns[22:32])
# 数据清洗
# ID列没有用,删除该列
data.drop("id",axis=1,inplace=True)
# 将B良性替换为0,M恶性替换为1
data['diagnosis']=data['diagnosis'].map({'M':1,'B':0})
然后我们要做特征字段的筛选,首先需要观察下 features_mean 各变量之间的关系,这里我们可以用 DataFrame 的 corr() 函数,然后用热力图帮我们可视化呈现。同样,我们也会看整体良性、恶性肿瘤的诊断情况。
# 将肿瘤诊断结果可视化
sns.countplot(data['diagnosis'],label="Count")
plt.show()
# 用热力图呈现features_mean字段之间的相关性
corr = data[features_mean].corr()
plt.figure(figsize=(14,14))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
这是运行的结果: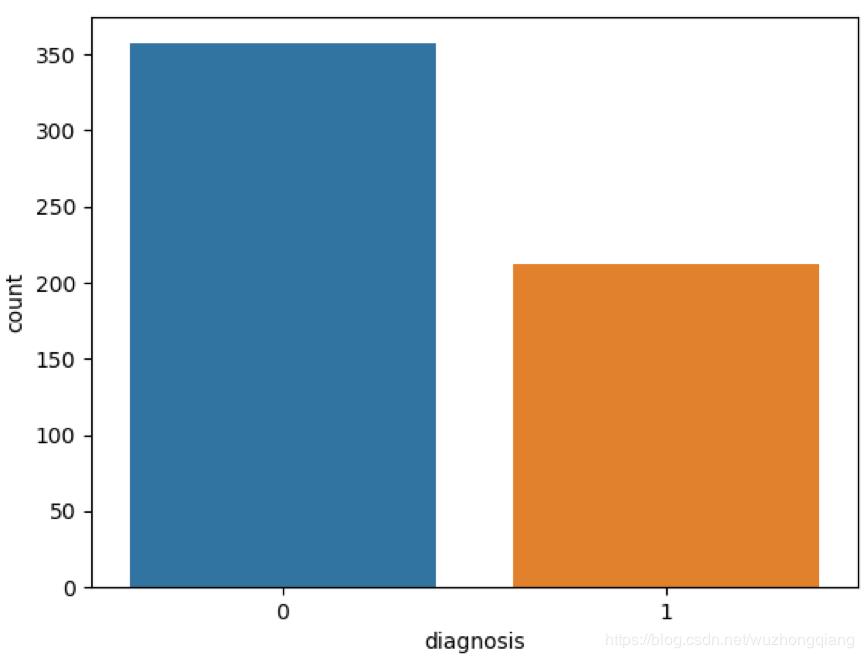
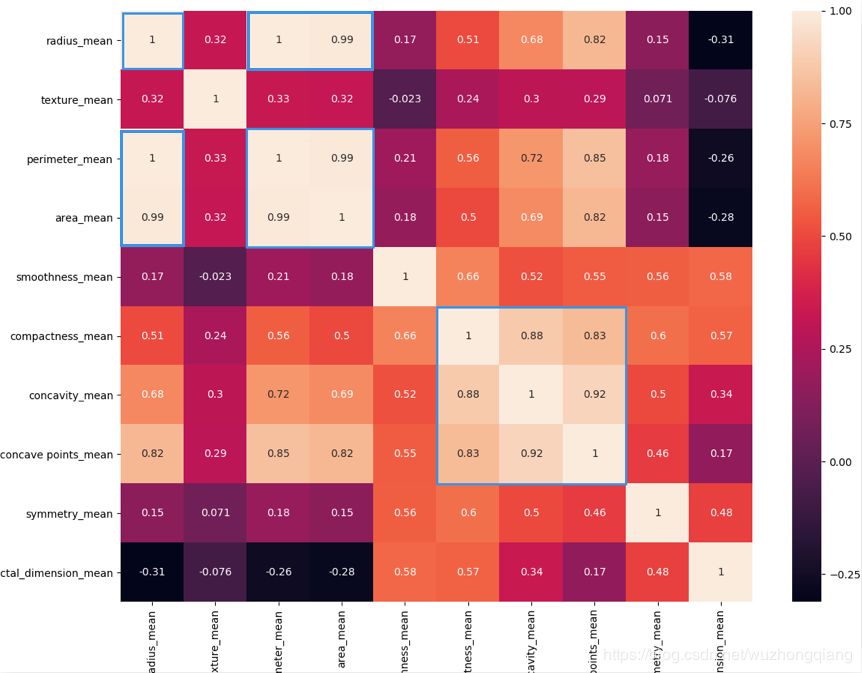 热力图中对角线上的为单变量自身的相关系数是 1。颜色越浅代表相关性越大。所以你能看出来 radius_mean、perimeter_mean 和 area_mean 相关性非常大,compactness_mean、concavity_mean、concave_points_mean 这三个字段也是相关的,因此我们可以取其中的一个作为代表。
热力图中对角线上的为单变量自身的相关系数是 1。颜色越浅代表相关性越大。所以你能看出来 radius_mean、perimeter_mean 和 area_mean 相关性非常大,compactness_mean、concavity_mean、concave_points_mean 这三个字段也是相关的,因此我们可以取其中的一个作为代表。
那么如何进行特征选择呢?
特征选择的目的是降维,用少量的特征代表数据的特性,这样也可以增强分类器的泛化能力,避免数据过拟合。我们能看到 mean、se 和 worst 这三组特征是对同一组内容的不同度量方式,我们可以保留 mean 这组特征,在特征选择中忽略掉 se 和 worst。同时我们能看到 mean 这组特征中,radius_mean、perimeter_mean、area_mean 这三个属性相关性大,compactness_mean、daconcavity_mean、concave points_mean 这三个属性相关性大。我们分别从这 2 类中选择 1 个属性作为代表,比如 radius_mean 和 compactness_mean。
这样我们就可以把原来的 10 个属性缩减为 6 个属性,代码如下:
# 特征选择
features_remain = ['radius_mean','texture_mean', 'smoothness_mean','compactness_mean','symmetry_mean', 'fractal_dimension_mean']
对特征进行选择之后,我们就可以准备训练集和测试集:
# 抽取30%的数据作为测试集,其余作为训练集
train, test = train_test_split(data, test_size = 0.3)# in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y=train['diagnosis']
test_X= test[features_remain]
test_y =test['diagnosis']
在训练之前,我们需要对数据进行规范化,这样让数据同在同一个量级上,避免因为维度问题造成数据误差:
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)
最后我们可以让 SVM 做训练和预测了:
# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(train_X,train_y)
# 用测试集做预测
prediction=model.predict(test_X)
print('准确率: ', metrics.accuracy_score(prediction,test_y))
# 运行结果
准确率: 0.9181286549707602
从上面来看,准确率还可以, 你可以尝试用所有的特征进行计算,也可以尝试换成线性可分支持向量机试试吧。
7. 总结
到这终于写完了支持向量机, 我的天啊,没想到这么多,赶紧来总结一下吧。今天我们从支持向量机的原理出发,通过小练习得到了超平面的初识,然后介绍了间隔和三种支持向量机,每一种支持向量机都针对不同的数据集训练出来的,并且背后都隐藏着很高深的数学推导。这一块数学知识很多,我都没有讲,只讲了大体上应该怎么算,详细过程我下面的链接里面都有,感兴趣的自行查看。
然后又介绍了向量机处理多分类的情况,两种方法一对一和一对多。
最后,理解了向量机的原理之后,利用sklearn实现了支持向量机,并拿来做了一个乳腺癌检测的例子。
希望通过今天的学习同样能够让你收获满满!加油吧!
参考:
-
http://note.youdao.com/noteshare?id=643e2e951d12826c31be515d9bcc5cc2&sub=FDE2B3547BB74A2B901D47177FA1DA3E -
http://note.youdao.com/noteshare?id=646c827fb51e067cb70d19f8b9a15cce&sub=D215BB1FE25D461D81027EA7C40FB7B8 -
https://blog.csdn.net/b285795298/article/details/81977271 -
http://note.youdao.com/noteshare?id=dd8506ca4fdf4a3d68757f985dfbb8e8&sub=4401DBD7C07C4D8C883F997B92563591 -
http://note.youdao.com/noteshare?id=d50add1394ad30ed2ce4438a93a38ffd&sub=1D7BA8DE2F354111A7B3D58E7FBC7F84 -
https://www.jiqizhixin.com/articles/2018-10-17-20
点个在看,么么哒!
以上是关于深入理解支持向量机(SVM)的主要内容,如果未能解决你的问题,请参考以下文章