原来这就是支持向量机
Posted 月来客栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原来这就是支持向量机相关的知识,希望对你有一定的参考价值。
在前面一系列的文章中,我们已经学习了多种分类算法模型,对于机器学习算是有了一定的了解。在接下来的几篇文章中,我们将开始逐步介绍中的最后一个分类模型——支持向量机。支持向量机(Support Vector Machine) 可以算得上是机器学习算法中最经典的模型之一。之所以称之为经典是因为其有着近乎完美的数学推导与证明,同时也正是因为这个原因,使得其求解过程有着很高的数学门槛。因此,对于接下来的内容,笔者也仅仅只会从支持向量机的建模过程出发,介绍支持向量基的主要思想以及它需要解决的问题。至于最后的求解过程,我们依旧通过现有的开源框架来实现。
1 引例
那什么是支持向量机呢?初学者刚接触到这个算法时基本上都会被这个名字所困扰,到底啥叫“向量机”,听起来总觉得怪怪的。因此首先需要明白的是,支持向量机其实和"机"一点关系也没有,算法的关键在于“支持向量”。并且支持向量机主要也是用于解决分类问题的一个算法模型,只是它相较于前面介绍的几种模型有着更好的泛化能力。
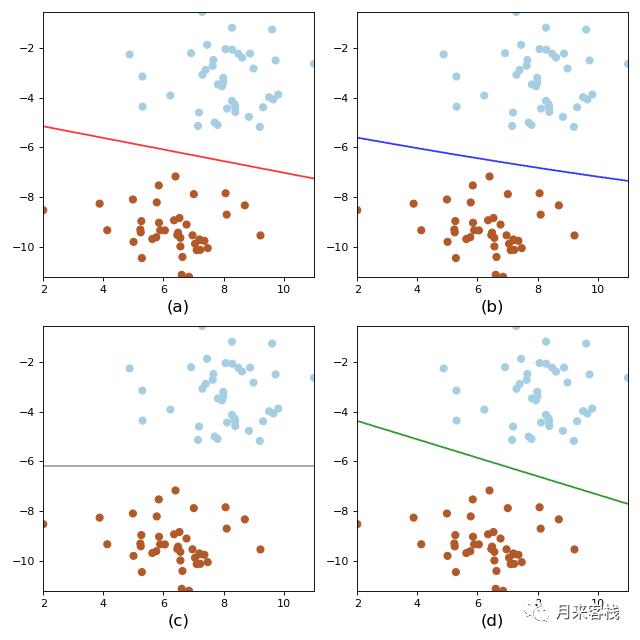
如图所示为四种模型对同一个数据集的分类后的决策边界,可以看到尽管每个模型都能准确地将数据集分成两类,但是从各自的决策边界来看却有着很大的区别。为了能清楚的进行观察,我们将四个决策边界放到一张图里面。
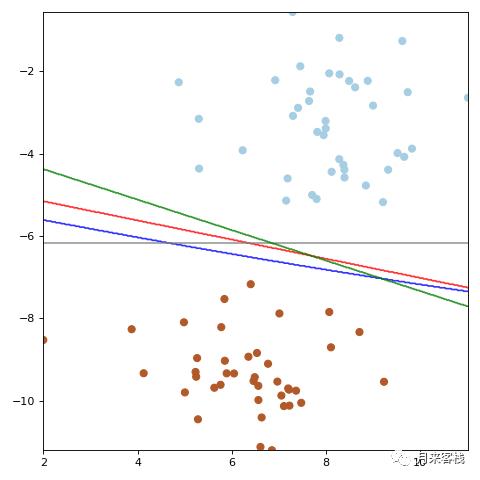
如图所示便为四个模型的决策边界放到一张图中的样子,可以发现模型c(灰色直线)的泛化能力应该会是最差的,因为从数据的分布位置来看真实的决策面应该是一条左高右低倾斜的直线。其次是模型c(蓝色直线)的泛化能力,因为模型c的决策面太过于的偏向于棕色的样本点;有一个原则就是:当没有明确的先验知识告诉我们决策面应该偏向于哪边时,最好的做法应该是居于中间的位置(类似于模型a和模型d的决策面)。那么模型a和模型d谁又更胜一筹呢?
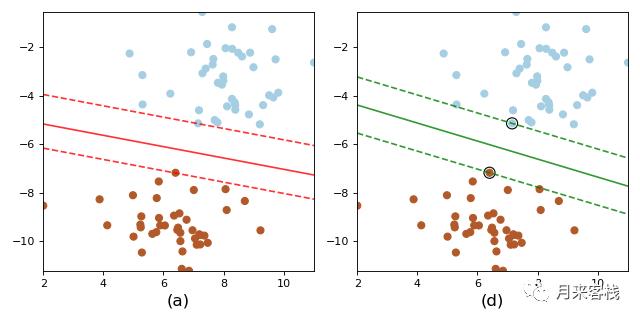
从图中一眼便可以看出,模型d的决策面更居于“中间”(事实上就是在中间),而模型a的决策面也略微的偏向于棕色样本点。因此在这四个模型中,模型d的泛化能力通常情况下都会是最强的。那有的朋友可能就会问,假如我们把模型a中的决策面向上移动一点,使得其也居于两条虚线之间,那么此时应该选择谁呢?答案当然依旧是d,原因在于模型d的决策面还满足另外一个条件:到两条虚线的距离最大。换句话说也就是,模型d中两条虚线之间的距离要大于模型a中两条虚线之间的距离。说到这里,相信大家已经明白了,其实模型d对应的就是支持向量机模型,而虚线上的两个点称为支持向量。可以发现其实对决策面其决定性作用的也只有这两个样本点,说白了就是通过这两个点就能训练得到模型d。
说到这里可以得出的结论就是,通过支持向量机我们便能够得到一个最优超平面,该超平面满足到左右两侧最近样本点的间隔相同,且离最近样本点的间隔最大。那我们又该如何来找到这个超平面呢?
2 间隔的度量方式
2.1 超平面的表达
在谈距离之前,我们先把超平面的表达式给写出来:
其中 表示截距;另一个需要说明的就是,我们在SVM中,用 分别来表示正样本和负样本。从表达式我们可以知道,当通过某种方法找到参数 后,也就代表确立了超平面。那么应该从哪个地方入手呢? 当然就是从SVM的核心思想:最大化间隔(gap) 入手。
2.2 函数间隔(functional margin)
上面说到SVM的核心思想就是最大化间隔,既然是最大化间隔那总得有个度量间隔的量才行。我们知道,当超平面 确定后, 可以相对的来表示每个样本点到超平面的距离,也就是说虽然实际距离不是 这么多,但是依旧遵循绝对值大的离超平面更远的原则。如下图所示:
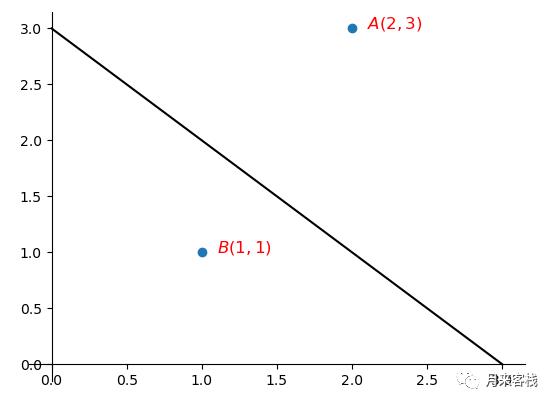
其中直线方程为: ,且 分别为正负两个样本点,即 ,则此时有:
点 到直线的相对距离为 ,点 到直线的相对距离为 。
同时我们可以注意到,只要分类正确, 就成立;或者说如果 成立,就意味着分类正确,且其值越大说明其分类正确的可信度就越高,而这也是 为什么取 的原因。所以此时我们将训练集中所有样本点到超平面的函数间隔定义为如下:
且定义训练集到超平面的函数间隔中的最小值为:
但是我们发现,如果同时在方程 的两边乘以 ;虽然此时超平并没有发生改变,但是相对距离却变成了之前的 倍,所以仅有函数间隔明显是不够的,还要引入另外一种度量方式——几何间隔。
2.3 几何间隔
如下图所示,所谓几何间隔(geometric margins),就是样本点到直线实实在在的距离。只要直线不发生改变,那么间隔就不会发生任何改变,这样就避免了在函数间隔中所存在的问题。那么应该如何来表示几何间隔呢?
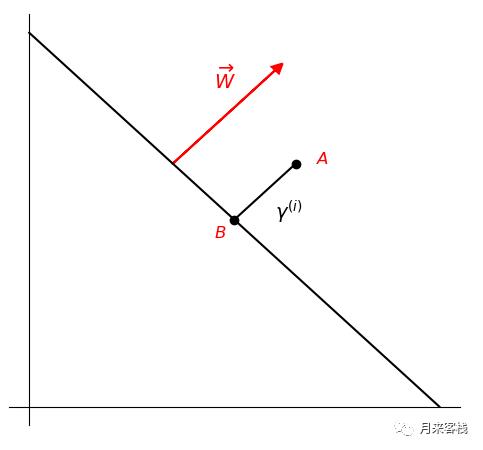
如图所示,直线方程为 , 为数据集中任意一个点 , 为 到直线的距离,可以看成是向量 的模; 为垂直于 的法向量。此时我们可以得到点B的坐标为:
又因为 点在直线上,所以满足:
因此我们可以通过化简等式 来得到几何距离的计算公式,但问题在于 该怎么得到?假设有一直线 ,(即: )那么该直线的斜率 ,又因为 垂直于直线,所以 的斜率为 。因此 的一个方向向量为 ,再同时乘以 即可得到 。也即是 其实就是 。
所以根据公式 有:
因此几何距离计算公式为:
如图:
直线方程为: , 为正样本, 为负样本,即 则:
此时我们发现,这是一个有符号的距离:正样本到直线的距离为正;负样本到直线的距离为负。但无论如何,同函数间隔一样只要是分类正确的情况下都满足 。同样,我们将数据集中所有样本点到平面的几何间隔定义为如下形式:
且定义训练集到超平面的几何间隔中的最小值:
同时,我们还可以发现函数间隔同几何间隔存在以下关系:
可以发现几何间隔其实就是在函数间隔的基础上施加了一个约束限制。此时我们已经有了对于间隔度量的方式,所以下一步自然就是最大化这个间隔来求得分类超平面。
3 最大间隔分类器
什么是最大间隔分类器(Maximum margin classifiers) 呢?上面我们说到有了间隔的度量方式之后,接着就是最大化这一间隔,然后求得超平面 。然后通过函数 将所有样本点输出只含 的值,以此来完成对数据集样本的分类任务。而 就是一个分类器,又因为是通过最大化几何间隔得来的,故将其称之为最大间隔分类器。
在上面的公式 中我们得到了几何间隔的表达式,因此再对其最大化即可:
式子 的含义就是找到参数 ,使得满足以下条件:
-
尽可能大,因为目的就是最大化 ; -
同时要使得样本中所有的几何距离都大于 ,因为由式子 可以知道 是所有间隔中的最小值;
所以,进一步由函数间隔与几何间隔的关系 我们可以得出以下优化问题:
此时我们发现,约束条件几何间隔依然变成了函数间隔,准确说应该既是函数间隔同样也是几何间隔。既然可以看做函数间隔,那么令 自然也不会影响最终的优化结果。
所以上述优化问题 就可以转化为如下形式:
但是对于 这样一个优化问题,我们还是无法直接解决。但我们知道,对于 ,三者求解出的 都相同。所以可以进一步将式子 化简为:
之所以要进行这样的处理,是因为我们可以将其转换为凸优化问题,用现有的方法进行求解(前面在乘以 是为了后面求导的时候能更方便,同时这也不会影响优化结果)。到这一步,我们就算是搞清楚了SVM的基本思想,以及其需要求解的优化问题。
4 总结
在这篇文章中,笔者首先通过一个引例介绍了支持向量机的核心思想;然后介绍了支持向量机中衡量间隔的两种度量方式:函数间隔和几何间隔;最后介绍了如何通过结合函数间隔与几何间隔来建模支持向量机的优化问题。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[2]Andrew Ng. CS229. Note3 http://cs229.stanford.edu/notes/cs229-notes3.pdf
[3]学习July博文总结——支持向量机(SVM)的深入理解(上)http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399
[4] 示例代码 : https://github.com/moon-hotel/MachineLearningWithMe
近期文章
Bagging、Boosting和Stacking
以上是关于原来这就是支持向量机的主要内容,如果未能解决你的问题,请参考以下文章